阅读原文 转自博客园 知行思新
引言:数据库设计 Step by Step (2)在园子里发表之后,收到了一些邮件,还有朋友直接电话我询问为什么不包含数据库物理设计方面的内容。我在这里解释一下,数据库物理设计与数据库产品是密切相关的,本系列的专注点是较为通用的数据库设计理念与方法,这也是国内软件项目中容易被忽视的一块。今天我们将学习实体关系(ER)模型构件及其语义,这是数据库逻辑设计的基础。内容可能有些枯燥,但却非常重要和有用。
由于内容比较多,我们将分两讲来学习实体关系模型构件。
今天我们先来学习基本实体关系模型。

实体关系(ER)模型的目标是捕获现实世界的数据需求,并以简单、易理解的方式表现出来。ER模型可用于项目组内部交流或用于与用户讨论系统数据需求。
ER模型中的基本元素
基本的ER模型包含三类元素:实体、关系、属性
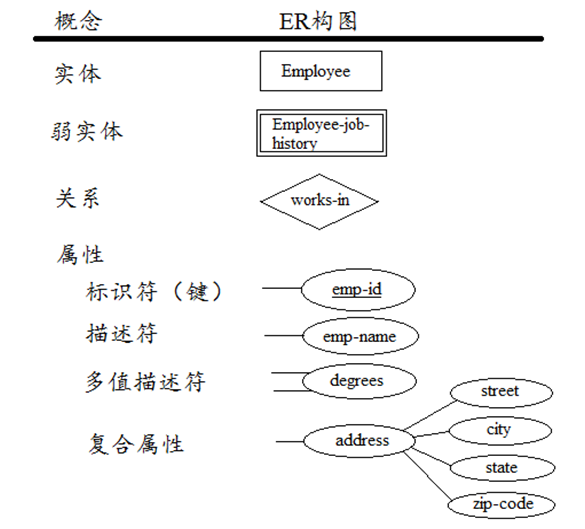
实体(Entities):实体是首要的数据对象,常用于表示一个人、地方、某样事物或某个事件。一个特定的实体被称为实体实例(entity instance或entity occurrence)。实体用长方形框表示,实体的名称标识在框内。一般名称单词的首字母大写。
关系(Relationships):关系表示一个或多个实体之间的联系。关系依赖于实体,一般没有物理概念上的存在。关系最常用来表示实体之间,一对一,一对多,多对多的对应。关系的构图是一个菱形,关系的名称一般为动词。关系的端点联系着角色(role)。一般情况下角色名可以省略,因为实体名和关系名已经能清楚的反应角色的概念,但有些情况下我们需标出角色名来避免歧义。
属性(Attributes):属性为实体提供详细的描述信息。一个特定实体的某个属性被称为属性值。Employee实体的属性可能有:emp-id, emp-name, emp-address, phone-no……。属性一般以椭圆形表示,并与描述的实体连接。属性可被分为两类:标识符(identifiers),描述符(descriptors)。Identifiers可以唯一标识实体的一个实例(key),可以由多个属性组成。ER图中通过在属性名下加上下划线来标识。多值属性(multivalued attributes)用两条线与实体连接,eg:hobbies属性(一个人可能有多个hobby,如reading,movies…)。复合属性(Complex attributes)本身还有其它属性。
辨别强实体与弱实体:强实体内部有唯一的标识符。弱实体(weak entities)的标识符来自于一个或多个其它强实体。弱实体用双线长方形框表示,依赖于强实体而存在。
深入理解关系
关系在ER模型中扮演了非常重要的角色。通过ER图可以描述实体间关系的度、连通数、存在性信息。
我们一一来解释这些概念。首先我们来看一下关系在ER图中的各种语义。

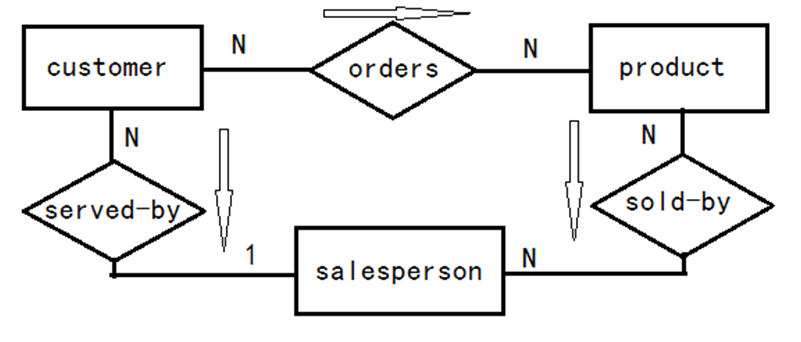
图2 关系的度、连通数、存在性
关系的度(Degree of a Relationship)
表示关系所关联的实体数量。二元关系与三元关系的度分别为2和3,以此可以类推至n元。二元关系是最常见的关系。
一个Employee与另一个Employee之间的领导关系称为二元回归关系。如图2中所示,Employee实体通过关系manages与自身连接。由于Employee在这一关系中扮演两个角色,故标出了角色名(manager和subordinate)。
三元关系联系三个实体。当二元关系无法准确描述关联的语义时,就需要使用三元关系。我们来看下面这个例子,下图(1)能反映出一个Employee在某个Project中使用了什么Skill。下图(2)只能看出Employee有什么Skill,参与了哪些Project,但无法知道在某个Project中使用的特定Skill。
图3 三元关系蕴含的语义
需要注意的是有些情况下会错误的定义三元关系。这些三元关系可分解为2个或3个二元关系,来达到化简与语义的纯净。以后的博文中会进一步详细讨论三元关系。
一个实体可以参与到任意多个关系中。每个关系可以联系任意多个元(实体),而且两个实体之间也能有任意多个二元关系。

关系的连通数(Connectivity of a Relationship)
表示关系所关联的实例数量的约束。
连通数的值可以是“一”或“多”。“一”这一端,在ER图中通过在实体与关系间标记“1”表示。“多”一端标记“N”表示。如图2中关系连通数部分,“一”对“一”:Department is managed by Employee;“一”对“多”:Department has Employees;“多”对“多”:Employee may work on many Projects and each Project may have many Employees。
有些情况下最大连通数是确定的,可以用数值代替N。如:田径队队员有12人。
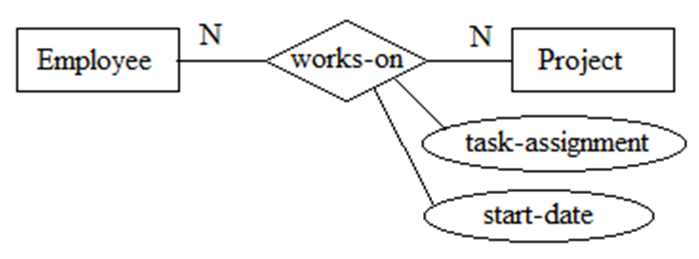
关系的属性
关系也能有属性。如下图4所示,某员工参与某项目的起始日期,某员工在某项目中被分配的任务只有放在关系works-on上才有意义。
图4 关系的属性
需要注意的是关系的属性一般出现在“多”对“多”的二元关系或三元关系上。一般“一”对“一”或“一”对“多”关系上不会放属性(会引起歧义,通俗说法就是没有中间表)。而且这些属性可以移至一端的实体中。如下图5所示,如果部门与员工(经理)之间是“一”对“一”关系,在建模中可能把start-date作为关系is managed by的属性(表示被接管的时间),这个属性可以移至Department或Employee实体中。
大家可以思考一下如果部门和经理之间是“多”对“多”关系,即交叉管理,那又会怎样?
关系中实体的存在性(Existence of an Entity in a Relationship)
关系中实体的存在性可以是强制的或可选的。当关系中的某一边实体(无论是“一”或“多”端)必须总是存在,则该实体为强制的。反之,该实体为可选的。
在实体与关系之间的连接线上标识“0”来表示可选存在性。含义是最小连通数为0。
强制存在性表示最小连通数为1。在存在性不确定或不可知的情况下,默认最小连通数为1。
在ER图中最大连通数显式地标识在实体旁边。如图6所示,其蕴含的语义为一个Department有且只有一个Employee来当经理,一个Employee可能是一个Department的经理,也可能不是。

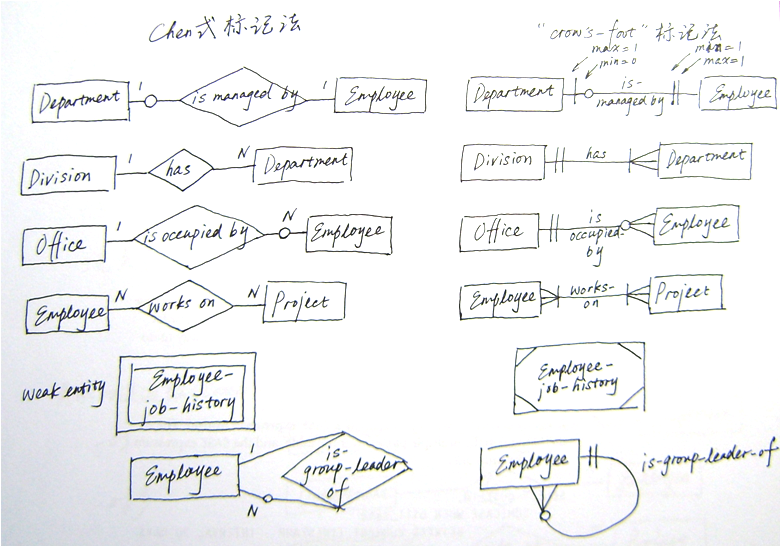
其他概念数据模型标记法
前文中使用的ER构图方法是Peter Chen 1976年提出的。在现代数据库设计领域,还有其他多种ER模型标记法。
我们来看一下另一种使用较多的标记法,“crow’s-foot”(鱼尾纹)标记法,并与前面介绍的标记法进行一个简单对比。
学习每一种标记法没有意义。在你的组织中推广应用一种标记法,使其成为大家共通的“语言”。

主要内容回顾
1. 组成ER模型的基本元素包括:实体、关系、属性
2. 深入理解关系中包含的语义:关系的度、关系的连通数、关系的存在性
3. 了解ER模型的不同标记法,掌握其中一种标记法,并在你的项目中推广使用
实体关系模型参考
1. Entity-relationship model(http://en.wikipedia.org/wiki/Entity-relationship_model)
2. Entity-relationship modelling(http://www.inf.unibz.it/~franconi/teaching/2000/ct481/er-modelling/)











{kind=link}