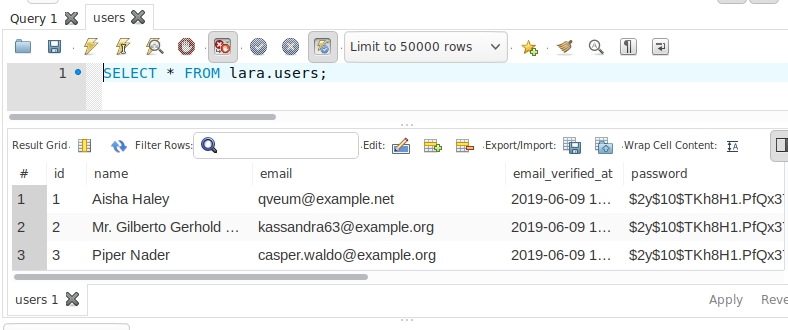
基本概念
程序是存储在硬盘上的编译生成的二级制可执行文件.不占用系统资源,是具体的.
进程是一个二进制程序(在内存中)的执行过程(运行实例).占用系统资源,是抽象的.
启动程序时,程序的文件会被加载到内存中,产生进程,结合系统分配的资源完成运行,程序关闭或退出时,进程会结束.
POSIX标准(可移植操作系统接口 Portable Operating System Interface),为了统一 类UNIX操作系统编程接口,方便跨平台编程和程序的可移植。参考:posix是什么都不知道,就别说你懂Linux了!
进程处理机制
1个单核CPU(或CPU的一个核心)在一个时间点只能处理一个进程.
我们用电脑同时运行多个程序,是因为操作系统的”多道程序设计”技术,内核控制CPU在多道进程间切换,它将CPU的整个生命周期划分为多个长度相同的时间片,在每个时间片内只处理一个进程。因为时间片很小,我们会感觉这些软件同时都在运行。这种分时间片实现的多任务系统,我们把它叫分时系统
CPU划分的时间片是微小的(比如纳秒),以及CPU的运算速度非常快,所以使用时感觉是同时运行多个程序.多核CPU在同时,多进程运行方面比单核CPU有优势.

多进程切换时。把当前任务状态先保存起来,把另一个任务的状态恢复,并把执行权交给它即可。俗称上下文切换。任务的状态就是一堆寄存器的值。要切换进程,只需要保存和恢复一堆寄存器的值即可。
进程的属性
OS内核能够区分进程并可获取进程属性,进程属性保存在名为进程控制块(Process Control Block)的中结构体中,内核为每个进程维护一个进程控制块,用于管理进程属性.
标识符
(1)进程标识符(Process Identifier)PID,32位非负无符号整形数据,进程的唯一标识,用来标识不同进程.
(2)父进程标识符(Parent Process Identifier)PPID,创建子进程的父进程对应的PID,在linux系统中,除init进程(编号为1)外,其余进程都有父进程. 吗
(3)用户标识符(User Identifier) UID ,标识创建这个进程的用户。PCB结构体中有euid概念(Effective User Identifier) ,即有效用户标识符,标识以有效权限发起进程的用户。例:用户yangliuan 以root权限发起进程,那么进程的uid对应的用户为yangliuan,进程的euid对应用户为root
(4)组标识符(Group Identifier)GID,标识创建进程的用户所属组。euid对应的组标识符为egid(Effective Group Identifier)
<?php
echo '进程标识[PID]:', posix_getpid(), PHP_EOL;
echo '父进程标识符[PPID]:', posix_getppid(), PHP_EOL;
echo '用户标识符[UID]:', posix_getuid(), PHP_EOL;
echo '有效用户标识符[EUID]:', posix_geteuid(), PHP_EOL;
echo '组标识符[GID]:', posix_getgid(), PHP_EOL;
echo '有效组标识符[EGID]:', posix_getegid(), PHP_EOL;进程的状态
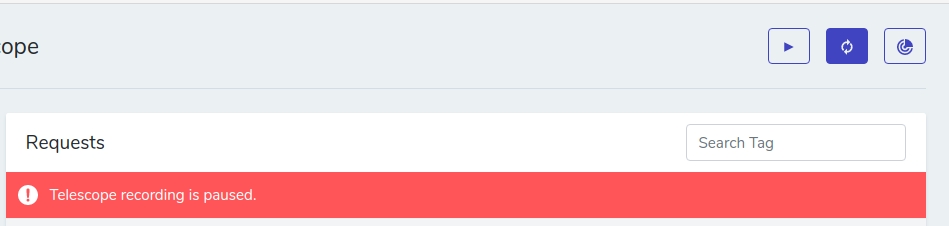
(1)就绪态
进程所需资源已经分配到位,只等待CPU,当可以使用CPU时,进程会立即变为运行态,内核会维护一个运行对列,用来装载所有就绪态的进程,当CPU空闲时,内核会从队列中选择一个进程,为其分配CPU
(2)运行态
进程处于此状态时会占用CPU,处于此状态的进程数量必定小于等于处理器数量,因为每个CPU在一个时间点只能运行一个进程
(3)睡眠态
此状态的进程不能占用CPU
不可中断睡眠态,是由外部I/O调用造成,等待外部I/O硬件设备响应,此状态不可中断,即我们常说的阻塞。举例进程向硬盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态
可终端睡眠态,进程对应的当前用户请求已处理完毕,暂时退出退出CPU,当用户再次发出请求,会立即被唤醒,这种状态被称为挂起,程序中常用的方法是sleep() (php为例) ,类比可以理解为汽车已点火,但是没有往前开。
(4)终止态
进程已运行完毕,此时进程不会被调度,也不再占用CPU
寄存器信息
寄存器的数量是有限的,cpu在进行进程切换时,会保存当前进程的数据,以边下次切换回来的时候从中断处继续进行。该过程称为cpu的上下文切换。在服务端多进程编程模型中,进程数和cpu核数该如何匹配
页表指针
程序运行时,系统会为其开辟一段虚拟内存,虚拟内存和物理内存映射时,各个虚拟内存中的地址相同的数据会被MMU(Memory Managenment 内存管理单元) 映射的到内存中的不同物理地址,PCB会存储虚拟地址和内存地址的对应关系
linux采用分页存储方式管理内存,进程载入到内存之前,系统将用户进程的逻辑空间分成若干个大小相等的片(称 页面或页)并编号,为进程分配内存时,以块为单位将进程中的若干页装入多个可以不相邻的物理块中,linux使用页面表来存储逻辑地址和物理地址的对应关系,页表的实质是一个结构体,每个进程的PCB中都有一个进项页表的指针。
进程组与会话
同一个进程组(process group)的进程 ,进程组由用户启动的进程创建,用户启动进程是进程组的领导进程(process group leader) ,进程组中的领导进程pid是识别进程组id,即pgid
会话(session)是进程组的集合,会话中的每一个进程组称为一个工作job,
进程控制
linux启动时创建一个init进程,进程pid为1,是所有进程的父进程,负责启动getty进程,设置进程运行级别 回收孤儿进程。
linux系统对进程的控制主要包含:进程创建,进程任务转变,进程同步,退出进程
1.创建进程
多道程序环境(多任务处理操作系统,可以同时运行多个程序)中需要创建进程的情况通常有4种:用户登录,作业调度,用户请求,应用请求。
当一个程序执行时,可能需要申请一些资源,如打开某个文件、请求某项服务 ,根据cpu运行的机制此时进程会进入睡眠态并放弃占用cpu,若要申请的资源与之后操作并不冲突,为了保障当前进程的持续进行(走完当前时间片),此时可以内存中在创建一个进程,让新的进程代替原进程执行资源申请的工作。
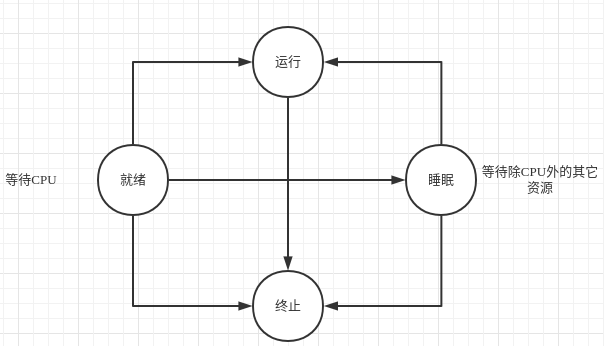
linux使用fork函数创建进程,系统会创建一个与原进程近乎相同的进程,之后父子进程都继续往下执行。如图
2.创建多个进程
fork函数创建进程时,系统会复制原程序,因此在通过父进程循环创建子进程时,要判断是不是父进程,只有父进程才能fork。
数据共享机制
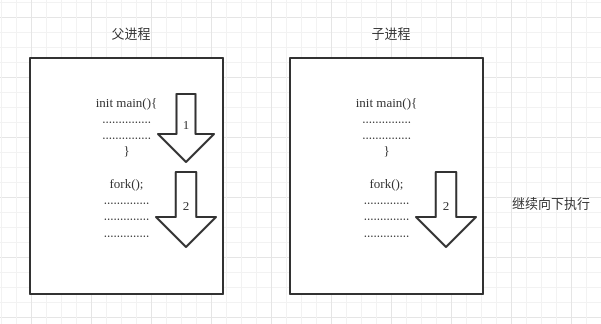
子进程可以访问到与父进程完全相同的代码信息、数据信息和堆栈信息,在调用fork()函数时,遵循“读时共享,写时复制”原则。
fork()函数创建子进程后,子进程获得父进程的数据空间,堆栈,页表,等副本,此时父子进程中变量的虚拟地址相同,虚拟地址对应的物理地址也相同,父子进程共享物理内存的页面信息,为了防止一方修改导致另一方出现访问异常,系统将页面信息标记为制度,fork()函数执行完毕。
之后父子进程都继续向下执行:此时子进程拥有与父进程相同的页表,若进程只需要进行数据访问,则到对应的物理地址中便能获取到数据,因为父子进程相同虚拟空间对应相同的物理地址,其访问机制如图。
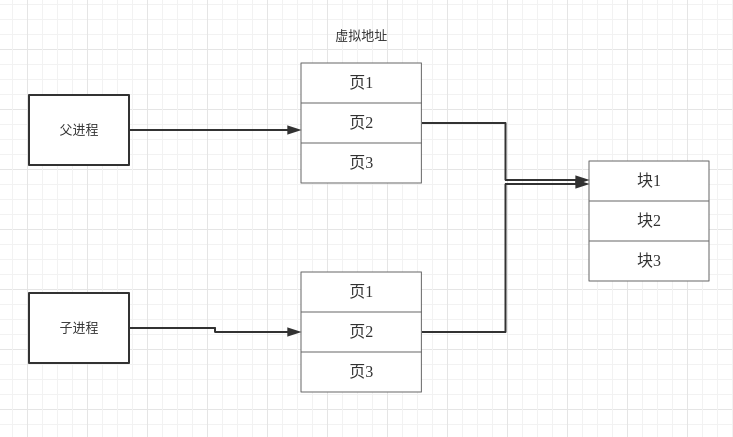
若子进程要对数据段,堆栈中的数据进行修改, 系统会将待操作数据复制到内存中一块新的区域,修改副本数据为可写。之后子进程修改数据副本,因此父子进程可以保存各自的数据,父子进程中相同的虚拟地址对应内存中不同的物理地址。访问机制如图
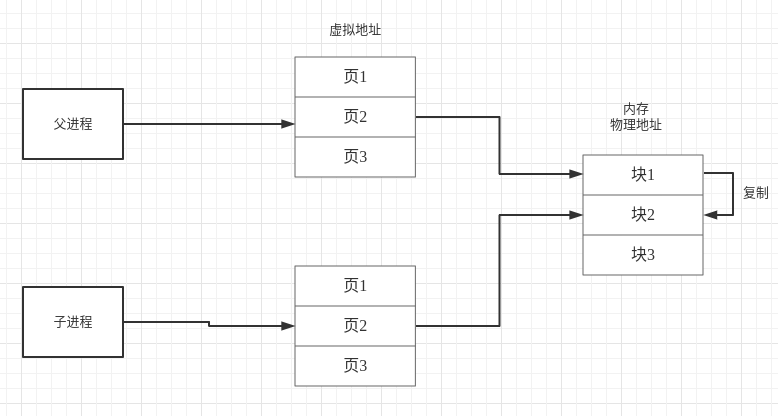
注意事项,同样的虚拟地址对应不通的物理地址,因为虚拟地址适合进程关联的,每个进程都有一段0~4G的虚拟内存,因此多个进程中会有数据处于相同虚拟地址 ,但虚拟内存只是系统的内存管理的一种技术,目的是使进程认为自己有一段连续的地址空间,方便分配与数据管理,他不是“实际”的,进程中的数据实际存在于内存对应的物理地址
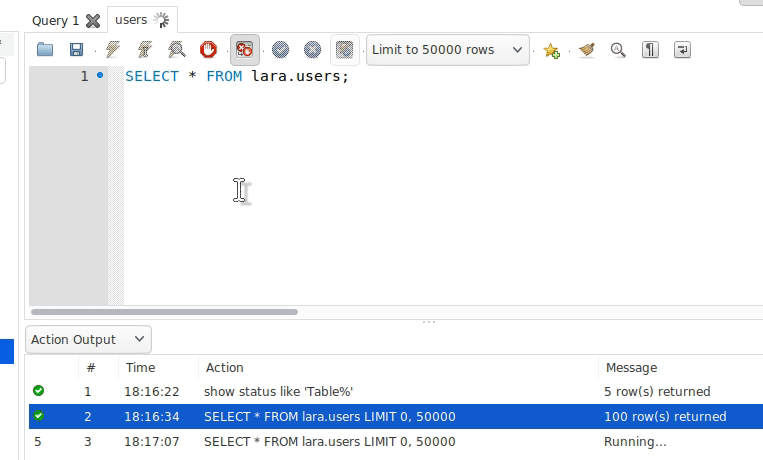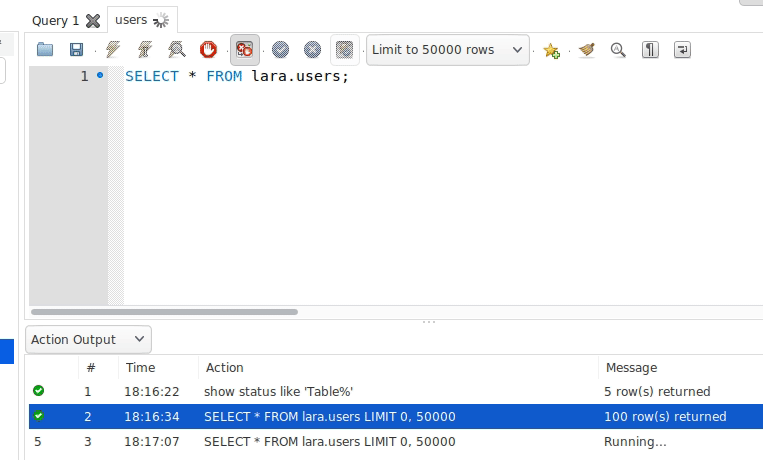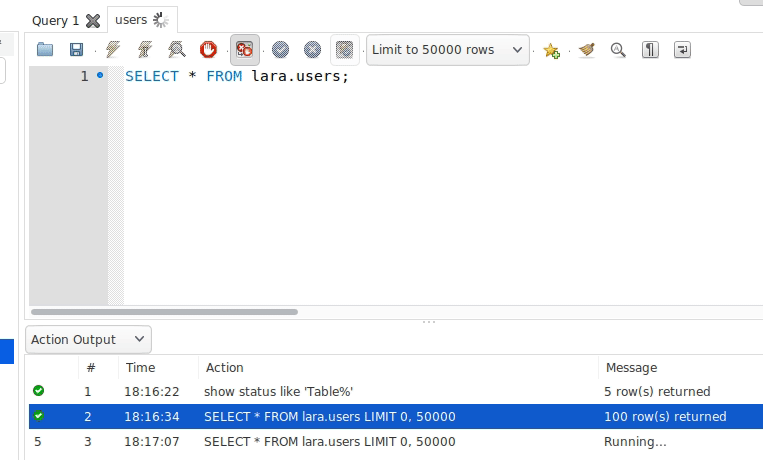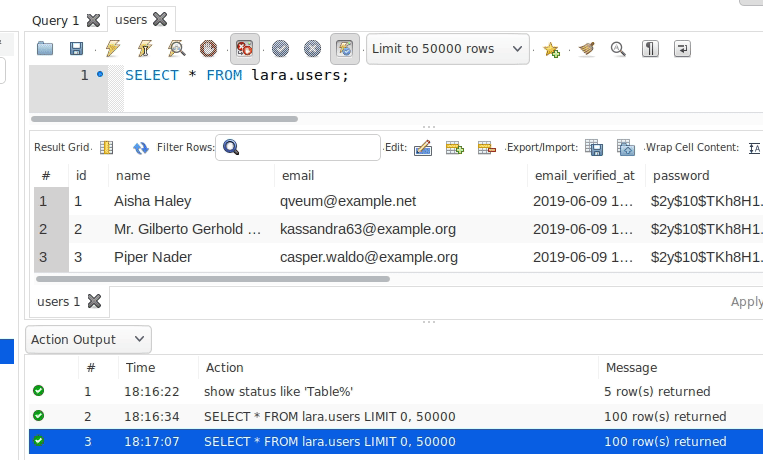
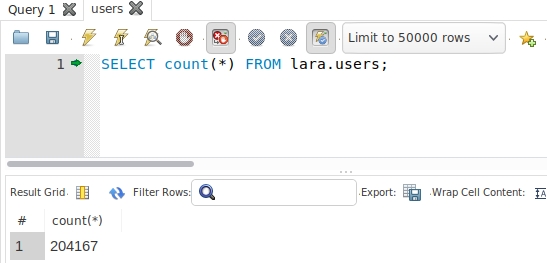
<?php//获取当期那进程id$pid = posix_getpid();echo "my pid: {$pid}", PHP_EOL;$childNum = 5;global $a;$a = 1;for ($i = 1; $i <= $childNum; ++$i) { //fork一个进程 $pid = pcntl_fork(); //创建失败 if (-1 === $pid) { echo "failt to fork!", PHP_EOL; exit; } elseif( $pid == 0 ) { //当前进程pid $mypid = posix_getpid(); //父进程pid $parentpid = posix_getppid(); //子进程中操作父进程变量并显示结果 $a++; echo "I'm the {$i}th child and my pid:{$mypid},parentpid:{$parentpid} a={$a}", PHP_EOL; sleep($childNum); exit; } elseif ($pid > 0) { //parent code echo "fork the {$i}th child,pid:{$pid} a={$a}", PHP_EOL; }}代码运行结果,全局变量a的值始终为2说明,无法修改父进程的值s
my pid: 37018
fork the 1th child,pid:37019 a=1
I'm the 1th child and my pid:37019,parentpid:37018 a=2
fork the 2th child,pid:37020 a=1
I'm the 2th child and my pid:37020,parentpid:37018 a=2
fork the 3th child,pid:37021 a=1
I'm the 3th child and my pid:37021,parentpid:37018 a=2
fork the 4th child,pid:37022 a=1
I'm the 4th child and my pid:37022,parentpid:37018 a=2
fork the 5th child,pid:37023 a=1
I'm the 5th child and my pid:37023,parentpid:37018 a=2进程的执行顺序
在linux系统中,子进程应该由父进程回收,但是当在子进程被创建后,他与父进程及其他进程共同竞争系统资源,所以父子进程执行顺序是不确定 ,终止的先后顺序也是不确定。(在没有人为控制的情况下,比如在父进程使用wait sleep函数
fork函数在执行时,会复制父进程的代码,当分支较多时,代码比较庞大,每次fork时都要将所有代码复制一次,如此代码冗余造成的空间浪费不可忽视。可以将多于代码封装起来,在需要时使用exec函数族调用执行。
孤儿进程
父进程应该负责子进程的回收工作,但父子进程是异步运行的,若父进程在子进程退出之前退出,子进程就会变成孤儿进程,此时子进程会被init进程收养,之后init会替代原来的父进程完成状态收集工作。避免孤儿的方法:sleep()函数 wait()函数
僵尸进程
当进程调用了exit()函数之后,该进程并不是马上消失,而是留下一个称为僵尸进程的数据结构,僵尸进程是linux系统中另一种特殊进程,它几乎放弃了进程退出之前占用的所有内存,即没有可执行代码,也不能被调度,只能在进程列表中保留一个位置,记载进程的退出状态等信息供父进程收集。若父进程中没有回收子进程的代码,子进程将会一直处于僵尸态。
守护进程(daemon process) 后台进程、
在后台运行的一种特殊进程,通常在系统启动时启动,并在系统关闭时终止。它们通常不与用户交互,而是在后台执行某些任务,例如监视文件系统或网络连接,或者执行定期任务。它们通常以超级用户(root)权限运行,以便可以执行需要特权的任务。原理,fork一个子进程,父进程退出与前台终端的交互,设置子进程为会话领导者。可以通过信号来控制启动关闭。
daemon希腊神话半人半精灵守护神
进程同步
在多道程序环境中,进程是并行执行的,父进程与子进程可能没有交集,各自独立执行,子进程的执行结果是父进程的下一步操作的先决条件,此时父进程必须等待子进程执行。我们把异步环境下的一组并发进程因相互制约而互相发送消息、互相合作、互相等待、使各个进程按一定的速度和顺序执行称为进程间的同步。
sleep()函数来控制进程的执行顺序,但这种方法是一种权益之计,系统中进程的执行顺序是由内核决定的,这种方法很难做到对进程精确控制
linux系统中提供了wait()函数 waitpid()函数(php中PCNTL提供了这两个函数)来获取进程状态,实现进程同步。调用wait()函数的进程
参考