所有存储引擎都支持每个表至少 16 个索引,总索引长度至少为 256 字节。
组合索引KEY(col1,col2) 联合主键索引 PARIMARY KEY( col1,col2)
最左匹配原则
创建了key(k1,k2,k3),相当于创建了(k1)、(k1,k2) 和 (k1,k2,k3) 三个索引
索引全部命中的情况where条件不区分顺序 where k1 = xxx and k2 = xxx and k3 = xxx 等同于 where k3 = xxx and k2 = xxx and k1 = xxx 查询优化器会处理并使用索引
where k1 = xxx 或 where k1 = xxx and k2 = xxx 使用索引 where k2 = xxx 或 where k3 = xxx 无法使用索引
当查询优化器发现最优索引时,并不会遵循最左匹配原则,而是使用最优查询,如下图k1,k2,k3为连续字段时,不按最左匹配查询还是会命中索引,此时k1,k2,k3被查询优化器当成了一个字段,单次查询k1,k2,k3都会命中
EXPLAIN select * from 3k where k2 = 'sdfdsa'

当k1,k2,k3不在连续中间被其它字段隔开时
相同的查询语句将不会命中索引

联合索引,那么 key 也由多个列组成,同时,索引只能用于查找 key 是否存在(相等),遇到 范围查询(>、<、between、like 左匹配)等就不能进一步匹配了,后续退化为线性查找。因此,列的排列顺序决定了可命中索引的列数。
如有索引 (a, b, c, d),查询条件 a = 1 and b = 2 and c = 3 and d > 4,则会在每个节点依次命中 a、b、c,无法命中 d。也就是最左前缀匹配原则。
不需要考虑 =、in 等的顺序,MySQL 会自动优化这些条件的顺序,以匹配尽可能多的索引列。
如有索引 (a, b, c, d),查询条件 c > 3 and b = 2 and a = 1 and d < 4 与 a = 1 and c > 3 and b = 2 and d < 4 等顺序都是可以的,MySQL 会自动优化为 a = 1 and b = 2 and c > 3 and d < 4,依次命中 a、b。
离散度高原则,选择性(离散性)高的优先,即数据重复率低的列,像性别字段只有男/女两个值,因此选择性很差
离散度的公式是 count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是 1,而一些状态、性别字段可能在大数据面前区分度就是 0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要 join 的字段我们都要求是 0.1 以上,即平均 1 条扫描 10 条记录。
字符串字段过长时可以使用,索引前缀,截取字段前一部分的值作为索引
CREATE TABLE test (blob_col BLOB, INDEX(blob_col(10)));Range类型 要使用单字段索引
当使用 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE 或 IN() 运算符中的任何一个将键列与常量进行比较时,可以使用范围
where min <= 1 and max >= 1 语句使用min和max联合索引并不会生效,应该使用min和max的两个单字段索引索引失效情况总结
查询条件包含 or,会导致索引失效
隐式类型转换,会导致索引失效,where条件左边字段类型为字符串类型时,传入其他类型会触发
like 通配符会导致索引失效,注意:”ABC%” 不会失效,会走 range 索引,”% ABC” 或 “%ABC%” 索引会失效
联合索引,最左匹配原则被中断时
对索引字段进行函数运算,列运算(算术,逻辑,移位等) 注意是对字段做运算,对字段的值做运算时并不影响,如下图
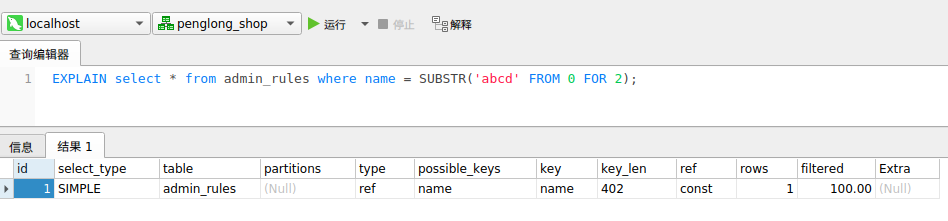
索引字段上使用(!= 或者 < >,not in)时,会导致索引失效
索引字段上使用 is null, is not null,可能导致索引失效
相 join 的两个表的字符编码不同,不能命中索引,会导致笛卡尔积的循环计算
mysql 优化器判断使用全表扫描要比使用索引快,则不使用索引
简单索引和联合索引如何抉择?
能扩展就不要新建索引。如果已有索引 (a),想建立索引 (a, b),尽量选择修改索引 (a) 为索引 (a, b),这样占用空间最小效果一致。
如果已有索引 (a, b),则不需要再建立索引 (a),但是如果有必要,则仍然需考虑建立索引 (b)。
索引尽量少原则
虽说索引可以加速查询,但索引未必是越多越好,因为:
- 第一点、数据的增删都会涉及到随索引的修改,索引越多维护成本越高,所以频繁进行数据操作的表,不要建立太多的索引;
- 第二点、索引越多也意味着存储空间需要越大;
因为索引是有代价的,所以用不到的索引,也需要清理掉。
如何定位哪些页面和接口需要加索引?
最简单直接方法是:往数据库里生成 100 万条数据,然后做黑盒测试。
数据有了以后,假装你是一个正常的用户,然后不断地点来点去,做各种操作,点赞、收藏、发文章、评论等,看看哪个动作或者页面加载很慢,就记录下来
如果使用laravel框架可以用telescope或者debug工具查看执行的sql语句,对访问频率高的接口和页面,增加索引,优化查询
参考