阅读原文 转自博客园 知行思新
引言:在前两篇博文(数据库设计 Step by Step (5)和数据库设计 Step by Step (6) —— 提取业务规则)中,我们进行了数据库需求分析,着重讨论了两个主题:1.理解用户需求;2.提取业务规则。当需求分析完成后,我们就要进入到概念数据建模环节。本篇文章将使用之前介绍过的“基本实体关系模型构件”和“高级实体关系模型构件”作为建模的基本元素,大家可以回顾数据库设计 Step by Step (3)和数据库设计 Step by Step (4)中的模型构件及语义。
逻辑数据库设计有多种实现方式,包括:自顶至底,自底至顶以及混合方式。传统数据库设计是一个自底至顶的过程,从分析需求中的单个数据元素开始,把相关多个数据元素组合在一起转化为数据库中的表。这种方式较难应对复杂的大型数据库设计,这就需要结合自顶至底的设计方式。
使用ER模型进行概念数据建模方便了项目团队内部及与最终用户之间的交流与沟通。ER建模的高效性还体现在它是一种自顶至底的设计方法。一个数据库中的实体数量比数据元素少很多,因为大部分数据元素表示的是属性。辨别实体并关注实体之间的关系能大大减少需要分析的对象数量。
概念数据建模连接了两端,一端是需求分析,其能辅助捕获需求中的实体及之间的关系,便于人们的交流。另一端是关系型数据库,模型可以很容易的转化为范式化或接近范式化的SQL表。

概念数据建模步骤
让我们进一步仔细观察应在需求分析和概念设计阶段定义的基本数据元素和关系。一般需求分析与概念设计是同步完成的。
使用ER模型进行概念设计的步骤包括:
- 辨识实体与属性
- 识别泛化层次结构
- 定义关系
下面我们对这三个步骤一一进行讨论。
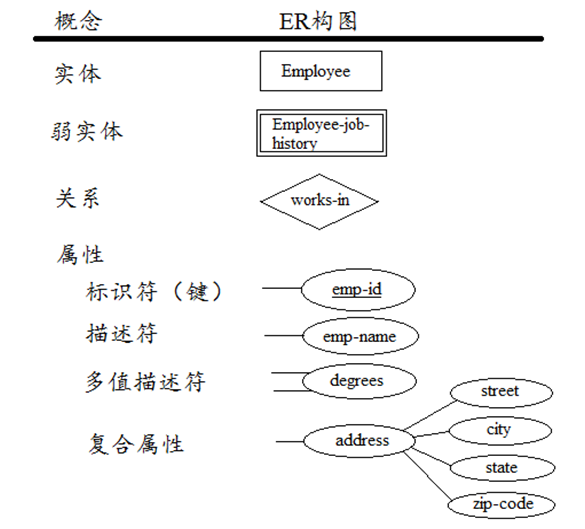
辨识实体与属性
实体和属性的概念及ER构图都很简单,但要在需求中区分实体和属性不是一件易事。例如:需求描述中有句话,“项目地址位于某个城市”。这句话中的城市是一个实体还是一个属性呢?又如:每一名员工有一份简历。这里的简历是一个实体还是一个属性呢?
辨别实体与属性可参考如下准则:
- 实体应包含描述性信息
- 多值属性应作为实体来处理
- 属性应附着在其直接描述的实体上
这些准则能引导开发人员得到符合范式的关系数据库设计。
如何理解上述的三条准则呢?
实体内容:实体应包含描述信息。如果一个数据元素有描述型信息,该数据元素应被识别为实体。如果一个数据元素只有一个标识名,则其应被识别为属性。以前面的“城市”为例,如果对于“城市”有一些如所属国家、人口等描述信息,则“城市”应被识别为一个实体。如果需求中的“城市”只表示一个城市名,则把“城市”作为属性附属与其他实体,如附属Project实体。这一准则的例外是当值的标识是可枚举的有限集时,应作为实体来处理。例如把系统中有效的国家集合定义为实体。在现实世界中作为实体看待的数据元素有:Employee,Task,Project,Department,Customer等。
多值属性:把多值属性作为实体。如果一个实例的某个描述符包含多个对应值,则即使该描述符没有自己的描述信息也应作为实体进行建模。例如:一个人会有许多爱好,如:看电影、打游戏、大篮球等。爱好对于一个人来说就是多值属性,则爱好应作为实体来看待。
属性依附:把属性附加在其最直接描述的实体上。例如:“office-building-name”作为“Department”属性比作为“Employee”的属性合适。识别实体与属性,并把属性附加到实体中是一个循环迭代的过程。
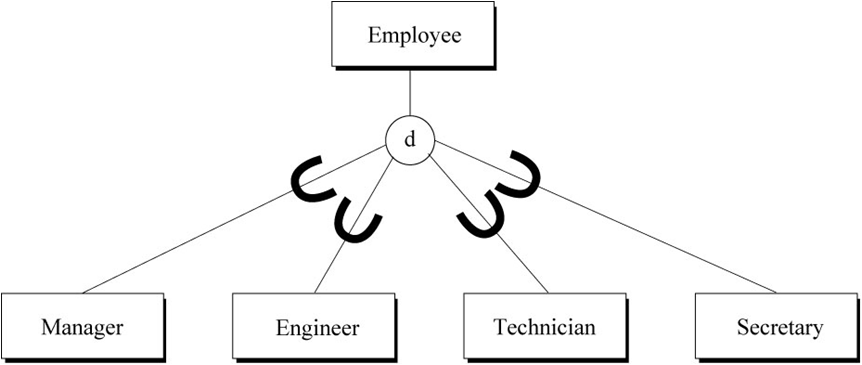
识别泛化层次
如果实体之间有泛化层次关系,则把标识符和公共的描述符(属性)放在超类实体中,把相同的标识符和特有的描述符放在子类实体中。举例来说,在ER模型中有5个实体,分别是Employee、Manager、Engineer、Technician、Secretary。其中Employee可以作为Manager、Engineer、Technician、Secretary的超类实体。我们可以把标识符empno,公共描述符empname、address、date-of-birth放在超类实体中。子类实体Manager中放empno,特有描述符jobtitle。Engineer实体中放empno,特有描述符jobtitle,highest-degree等。
定义关系
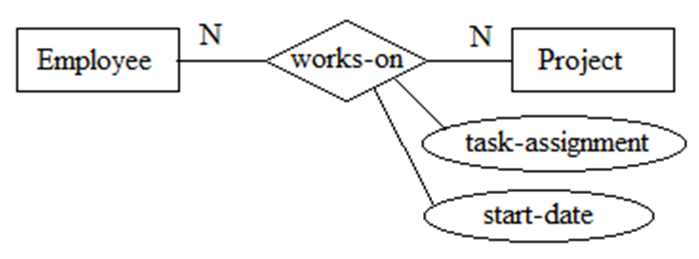
在识别实体和属性之后我们可以处理代表实体之间联系的数据元素即关系。关系在需求描述中一般是一些动词如:works-in、works-for、purchases、drives,这些动词联系了不同的实体。
对于任何关系,需要明确以下几个方面。
- 关系的度(二元、三元等);
- 关系的连通数(一对一、一对多等);
- 关系是强制的还是可选的;
- 关系本身有些什么属性。
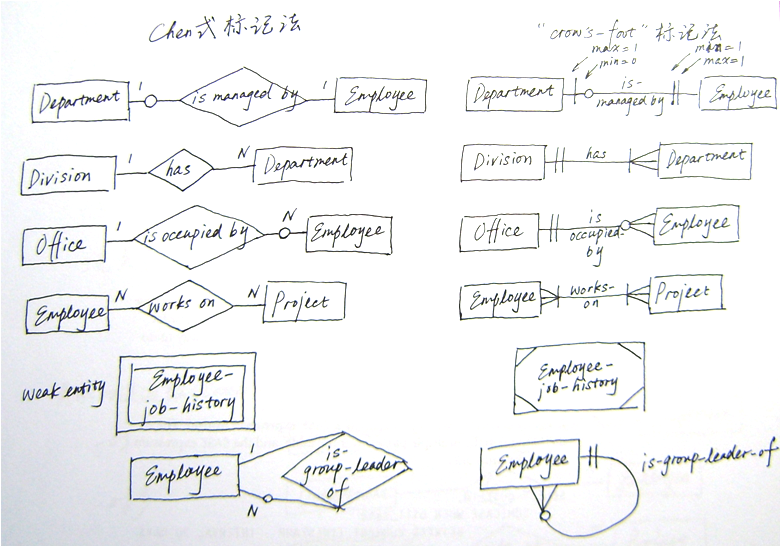
注:关系的这些概念可参看数据库设计 Step by Step (3),这里不再赘述。
冗余关系
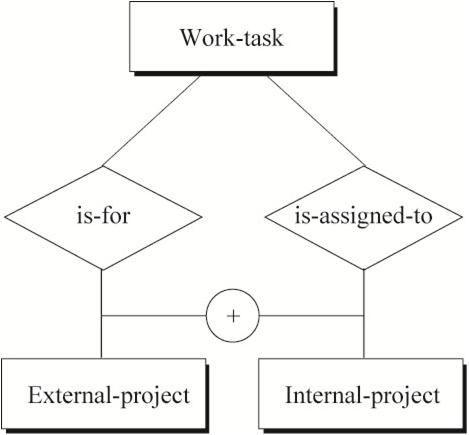
仔细分析冗余的关系。描述同一概念的两个或多个关系被认为是冗余的。当把ER模型转化为关系数据库中的表时,冗余的关系可能造成非范式化的表。需要注意的是两个实体间允许两个或更多关系的存在,只要这些关系具有不同的含义。在这种情况下这些关系不是冗余的。
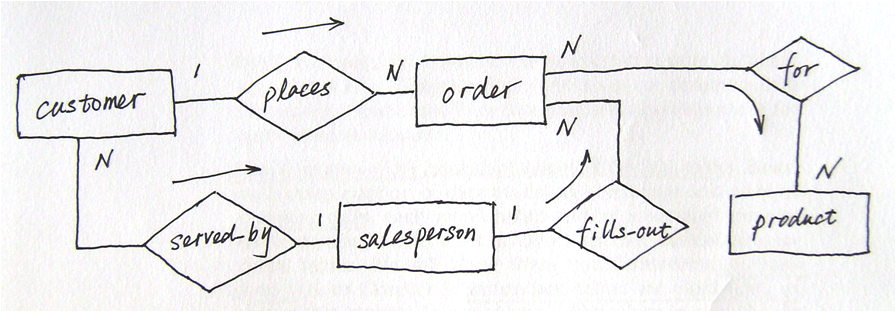
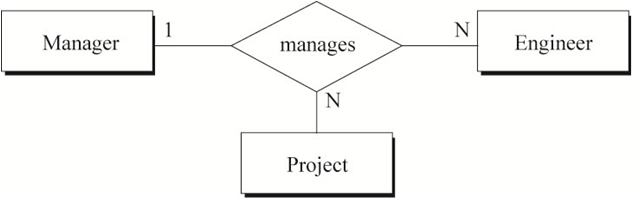
举例来说,如下图1中Employee生活的City与该Employee所属的Professional-association的所在City可以不同(两种含义),故关系lives-in非冗余。
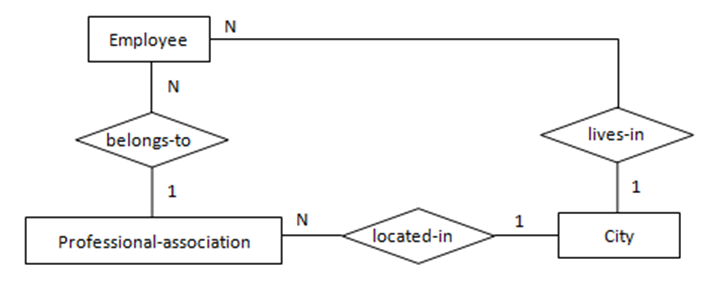
三元关系
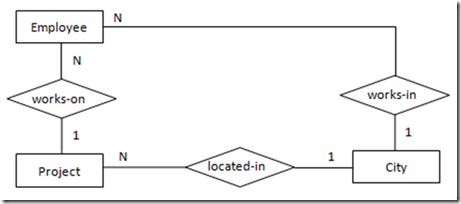
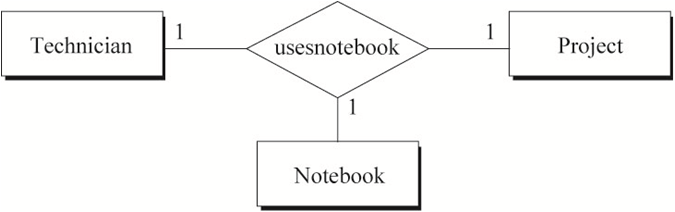
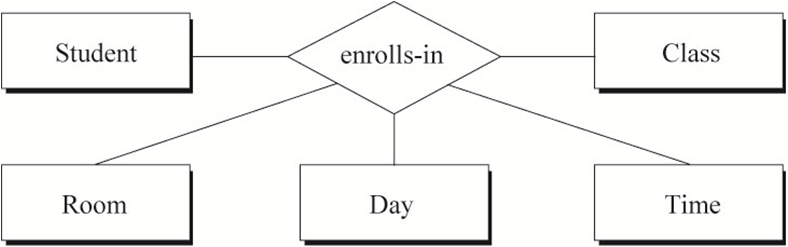
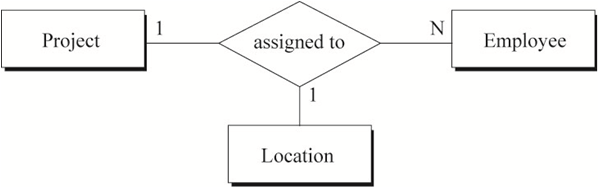
非常小心的定义三元关系,只有当使用多个二元关系也无法充分描述多个实体间的语义时,我们才会定义三元关系。以Technician、Project、Notebook为例。
例1:如果 一个Technician只做一个Project,一个Project只有一个Technician,每个Project会被独立记录在一本Notebook中。
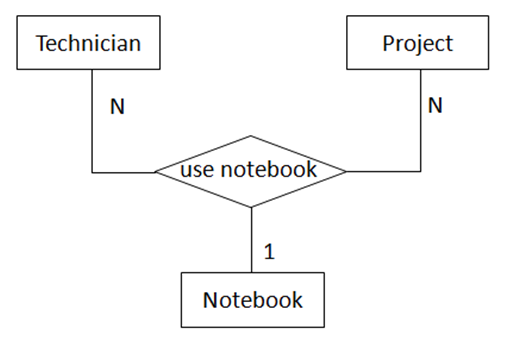
例2:如果一个Technician能同时做多个Project,一个Project可以有多个Technician同时参与,每个Project有一本Notebook(多个做同一个Project的Technician共用一本Notebook)

例3:如果一个Technician能同时做多个Project,一个Project可以有多个Technician同时参与,一个Technician在一个Project中使用独立的一本Notebook。
注:三元关系的语义分析可参看数据库设计 Step by Step (4),这里不再赘述。

我们假设要为一家工程项目公司设计一个数据库来跟踪所有的全职员工,包括员工被分配的项目,所拥有的技能,所在的部门和事业部,所属于的专业协会,被分配的电脑。
单个视图的ER建模
通过需求收集与分析过程,我们获得了数据库的3个视图。
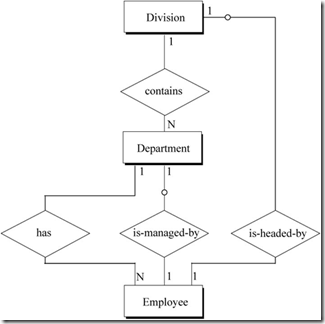
第一个视图是人力资源管理视图。每一个员工属于一个部门。事业部是公司的基本单元,每个事业部包含多个部门。每一个部门和事业部都有一个经理,我们需要跟踪每一个经理。这一视图的ER模型如图6所示。
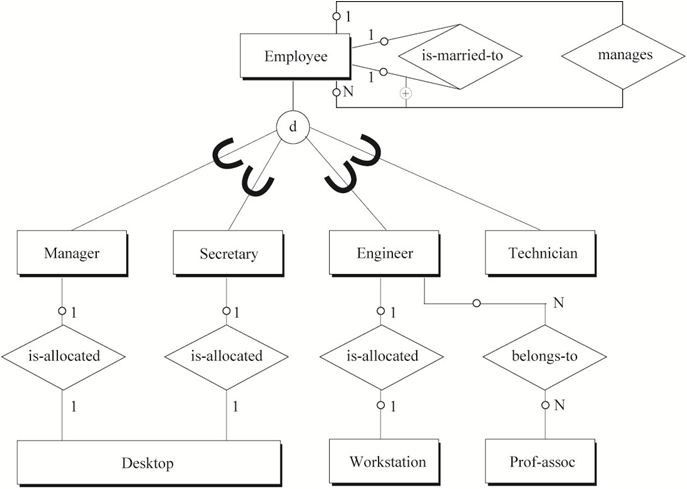
第二个视图定义了每个员工的头衔,如工程师、技术员、秘书、经理等。工程师一般属于某个专业协会,并可能被分配一台工作站。秘书和经理会被分配台式电脑。公司会储备一些台式电脑和工作站,以分配给新员工或当员工的电脑送修时进行出借。员工之间可能有夫妻关系,这也需要在系统中进行跟踪,以防止夫妻员工之间有直接领导关系。这一视图的ER模型如图7所示。
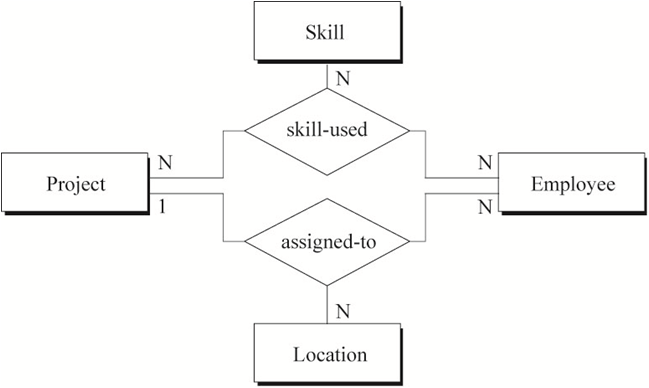
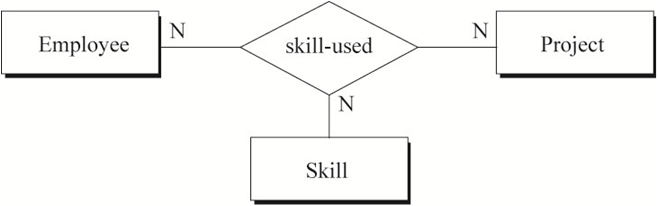
第三个视图如图8所示,包含员工(工程师、技术员)分配项目的信息。员工可以同时参与多个项目,每一个项目可以在不同的地方(城市)设有总部。但一个员工在指定的地点只能做当地的一个项目。员工在不同的项目中可以选用不同的技能。
全局ER图
对三个视图的简单集成可得到全局ER图,如图9所示,它是构造范式化表的基础。全局ER图中的每一个关系都是基于企业中实际数据的一个可验证断言。对这些断言进行分析导出了从ER图到关系数据库表的转化。
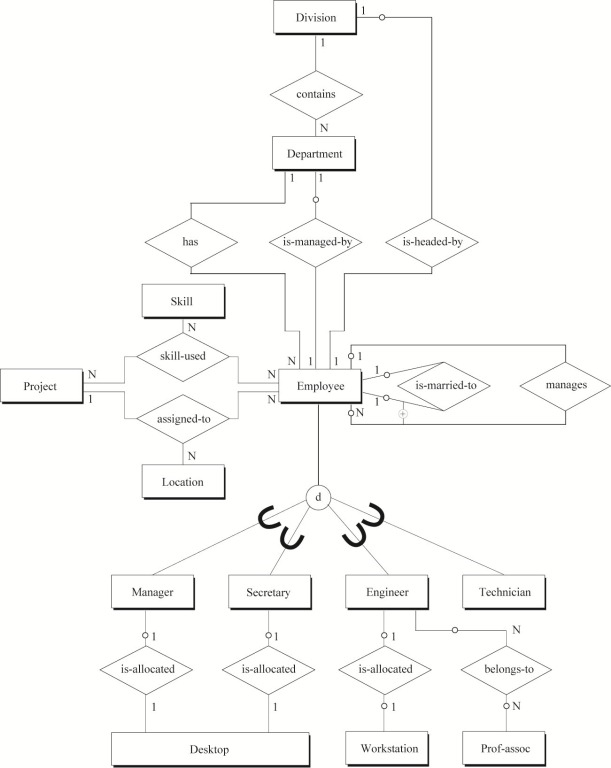
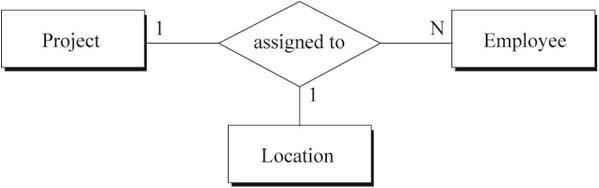
从全局ER图中可以看到二元、三元和二元回归关系;可选和强制存在性关系;泛化的分解约束。图9中三元关系“skill-used”和“assigned-to”是必须的,因为使用二元关系无法描述相同的语义。
可选存在性的使用,Employee与Division或与Department之间是基于常识:大多数Employee不会是Division或Department的经理。另一个可选存在性的例子是desktop或workstation的分配,每一台desktop或workstation未必都会分配给一个人。总而言之,在把ER模型转化为SQL表之前,所有的关系、可选约束、泛化层次都需要与系统的最终用户进行确认。

总结来说,在关系数据库设计中应用ER模型会带来如下好处
1. 使用ER模型可帮助项目成员专注在讨论实体之间的重要关系上,而不受其他细节的干扰。
2. ER模型把大量复杂的语言描述转化为精简的、易理解的图形化描述。
3. 对原始ER模型的扩展,如可选和强制存在性关系,泛化关系等加强了ER模型对现实语义的描述能力。
4. 从ER模型转化为SQL表有完整的规则,且易于使用。
实体关系(ER)模型参考资料
1. 基本实体关系模型构件——实体、关系、属性、关系的度、关系的连通数、关系的属性、关系中实体的存在性(http://www.cnblogs.com/DBFocus/archive/2011/04/24/2026142.html)
2. 高级实体关系模型构件——泛化、聚合、三元关系(http://www.cnblogs.com/DBFocus/archive/2011/05/07/2039674.html)

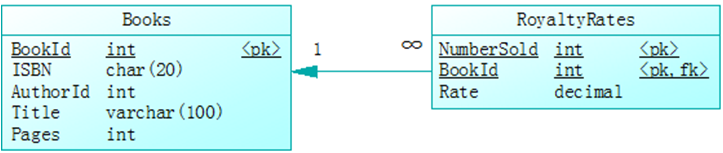 图1 参数表RoyaltyRates与Books表的关系
图1 参数表RoyaltyRates与Books表的关系





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}