设计经验总结
掌握ER模型中的基本元素和概念,实体,关系,属性,关系,数据库范式,反范式
单人开发项目时,如果无法很快设计出全部的数据库,可以先设计简单的小部分,然后编码,这样可以提高开发效率效率,如果一直空想会浪费很多时间,任何设计都是逐步完善和迭代的,面对复杂的逻辑,大部分普通程序员都无法一下想出很好的设计方案
关系的度(Degree of a Relationship)
表示几个实体之间的关系,二元关系 ,三元关系,N元关系 ,二元回归关系(例子:无限级分类pid自关联);
在数据表中的体现是一张表中有几个外键;设计时要仔细确定各终端每个需求需要的是几元关系;
将项目拆分模块后,要对模块继续拆分,拆分到每一个页面的每个块数据,转化成具体查询思路
当一个中间表(关系)无法满足需求时,可能需要多个中间表实现;一个实体(表)可以参与到任意多个关系(中间表)中。每个关系可以联系任意多个元(实体 表),而且两个实体(表)之间也能有任意多个二元关系(中间表)。
关系的连通数(Connectivity of a Relationship)
二元(两个表) 的 一对一,一对多,多对多
多元(多个表)的一对一对一.. 一对一对多.. 一对多对多.. 多对多对多.. 可以用数学中的函数依赖表示
关系是强制的还是可以选的
数据库范式
第一范式(1NF)列值必须有具有原子性,不可分割,例如省市区或经纬度不能放到一个字段里
第二范式(2NF)一张表满足第一范式且每个非键属性完全依赖于主键。当一个属性出现在函数依赖式的右端,且函数依赖式的左端为表的主键或可由主键传递派生出的属性组,则该属性完全依赖于主键;通俗的说法就是
第三范式(3NF)一张表满足当且仅当其每个非平凡函数依赖X –> A,其中X和A可为简单或复合属性,必须满足以下两个条件之一。1. X为超键 或 2. A为某候选键的成员。若A为某候选键的成员,则A被称为主属性。注:平凡函数依赖的形式为YZ –> Z
Boyce-Codd范式(BCNF)一张表R满足Boyce-Codd范式(BCNF),若其每一条非平凡函数依赖X –> A中X为超键。
范式总结:
二三范式,多值属性,可变值属性,一张表中有多个事实描述,需要拆成多张表关联,解决插入和更新异常
bcnf范式,删除异常通过中间表加冗余字段来解决,比如删除商品后,订单中需要展示的封面图和商品名称字段不见了需要增加封面图和商品名称冗余字段来保存
范式设计是参考标准,最终以需求为准满足需求的设计才是最适合的设计,避免原教旨主义。
特殊需求反范式设计,提升查询性能
三种设置主键的思路:业务字段做主键、自增字段做主键和手动赋值字段做主键。
业务字段做主键
例用户表使用会员卡做主键,当业务需求发生变化,例如需要将A的会员卡号转给B,会造成用户关联表流水记录出现混乱,A的流水变成了B的流水
以业务字段做主键还有一个可能的后果就是,索引的叶子结点中的内容占用空间可能会比较大,一个页面可能能放入的数据更少了
自增字段做主键
单数据库应用通常使用自增id做主键,例如laravel框架默认使用自增id
当业务需求需要多个数据库分别保存数据库时,例如超市门店要求离线保存并定期最终汇总到一起,自增id就会出现冲突。
手动赋值字段做主键
手动赋值可以上述问题,在总部的数据库里保存一下当前最大id的值,然后插入之前先查询一下id的最大值
UUID和雪花ID能保证主键的唯一性,也可以解决上述需求,分布式系统常用
物理设计注意事项
varchar和char 最大行65535
text类型字段个数限制
案例分析
贝宝项目-分销
需求描述
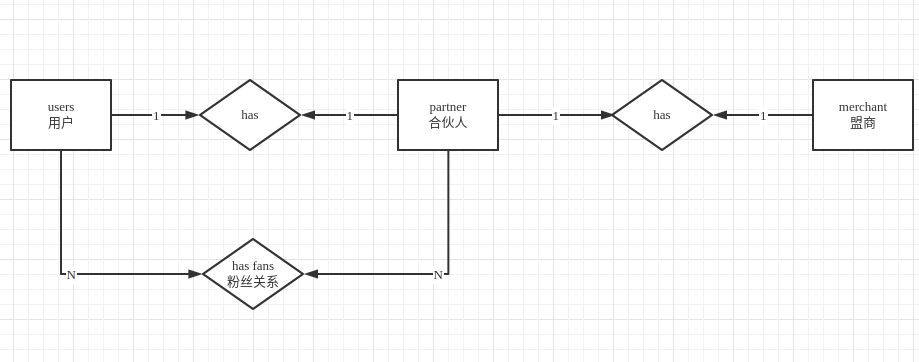
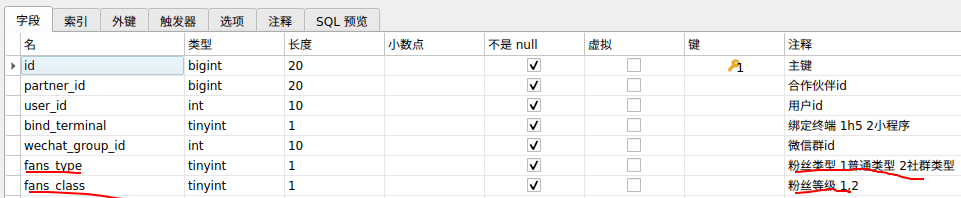
用户和盟商创建时自动生成合伙人,合伙人分享给用户链接,用户点击分享链接时绑定为合伙人的粉丝

点餐项目-手环消息推送
需求描述
用户在餐桌呼叫服务,向餐桌绑定的手环逐个发送消息。如果第一个手环的使用者响应了消息则呼叫服务成功,否则继续向下一个手环发送消息,直至超过最大调度次数。
舍得租赁电商-相机排期
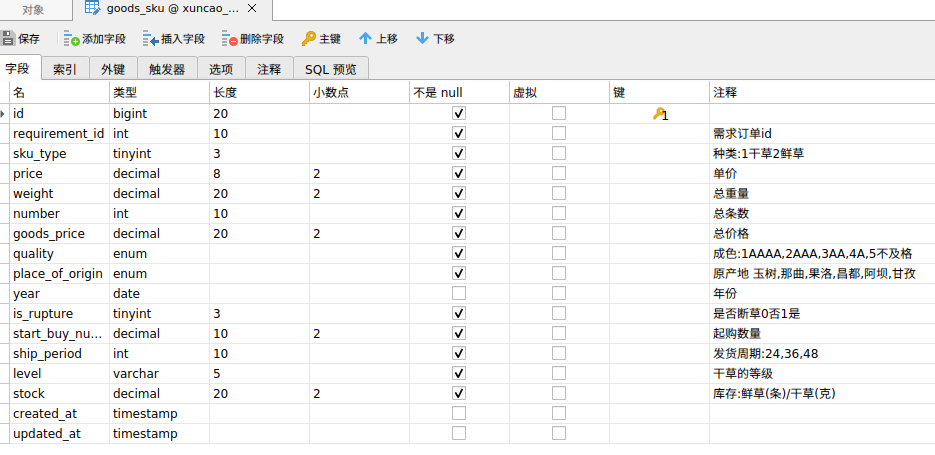
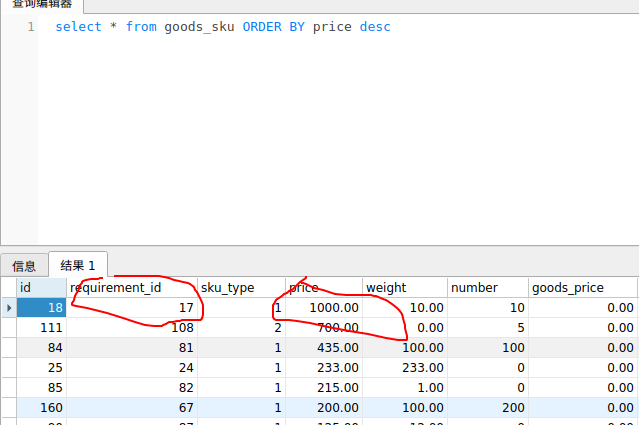
共好电商-多规格SKU
统计需求汇总
总结,
查询简单对性能要求不高的直接查询返回,
查询复杂的按照展示需求单独建表统计,可以基于复杂查询语句的查询结果整个写入统计表中
更复杂的统计用ES实现
点餐统计需求

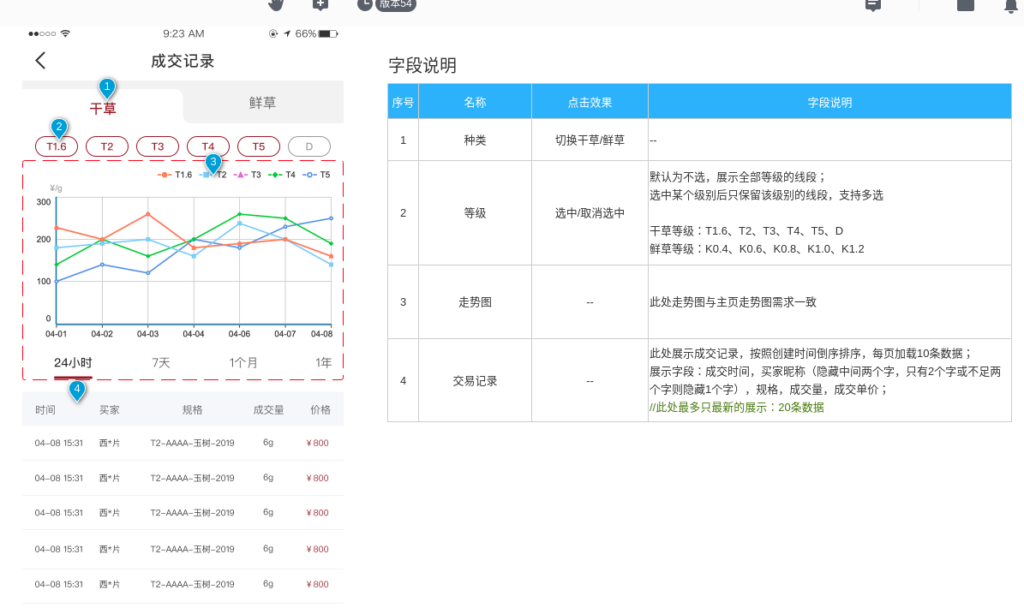
寻草订单交易量统计需求