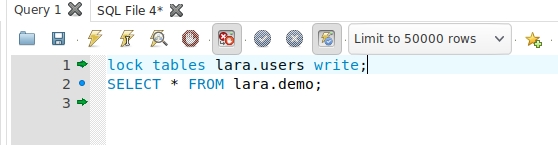
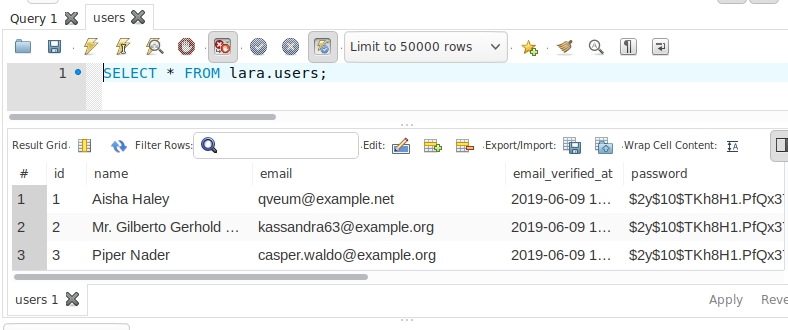
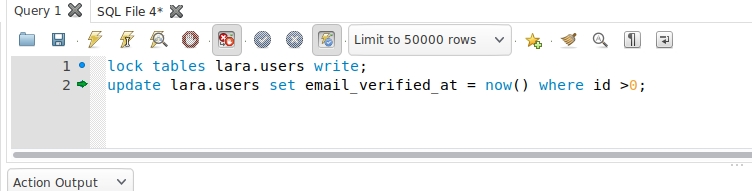
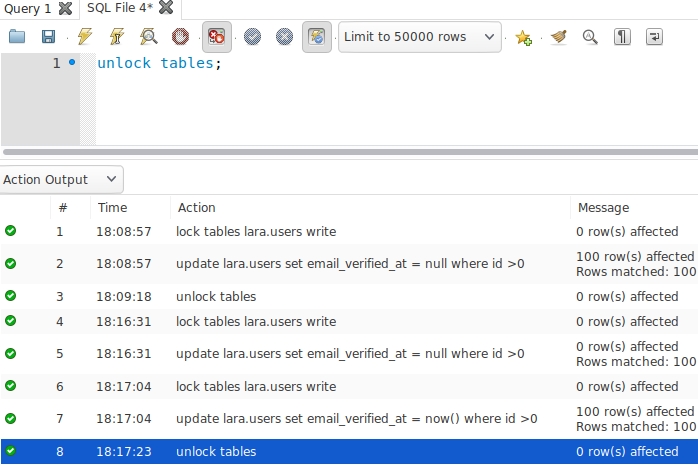
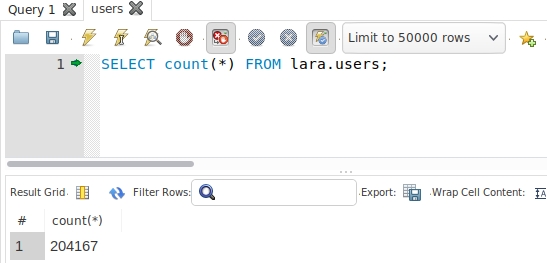
#创建用户 db_user 换成root表示root用户
MySQL [(none)]> create user db_user@'%' identified by 'db_pass';
#授权 db_name 用*替代表示访问所有数据库
MySQL [(none)]> grant all privileges on db_name.* to db_user@'%' with grant option;
#退出数据库控制台,特别注意有分号
MySQL [(none)]> exit;
Mysql 8.0以下
MySQL [(none)]> grant all privileges on db_name.* to db_user@'%' identified by 'db_pass';
#授权语句,特别注意有分号
MySQL [(none)]> flush privileges;
#退出数据库控制台,特别注意有分号
MySQL [(none)]> exit;
创建用户
create user 'username'@'%' identified by 'password';
username 用户名 %所有ip password 密码
授权所有数据库
grant all privileges on *.* to 'username'@'%';
flush privileges;
#创建用户
CREATE USER 'tongbu'@'192.168.%.%' IDENTIFIED BY '123456';
#配置账号同步权限
GRANT REPLICATION SLAVE ON *.* TO 'tongbu'@'192.168.%.%';
#刷新权限
flush privileges
MySQL [(none)]> show master status\G;
*************************** 1. row ***************************
File: mysql-bin.000320
Position: 154
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 2d8be082-e379-11e6-9e2c-d89d672bc9d4:1-759145,
48496646-e379-11e6-9e2d-008cfaf6f158:1-4,
7c64616c-23a4-11e7-809c-7cd30abda0c4:1-9629173,
98d692c9-07a7-11e7-8a1b-7cd30abd9f90:1-6919876
1 row in set (0.00 sec)
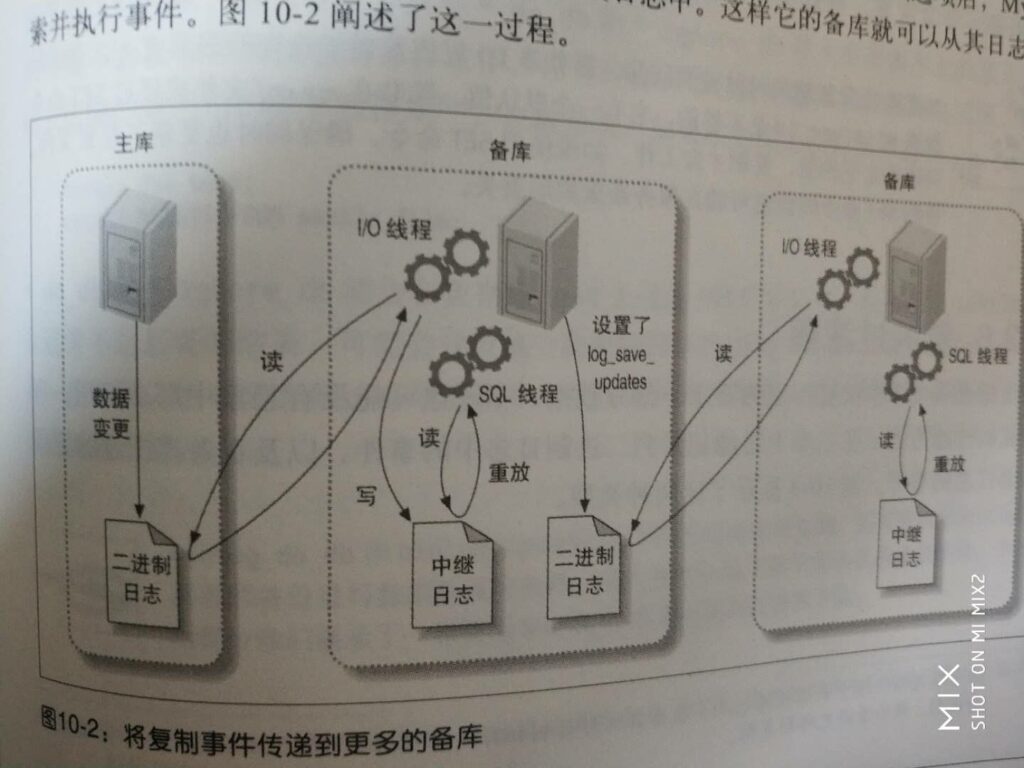
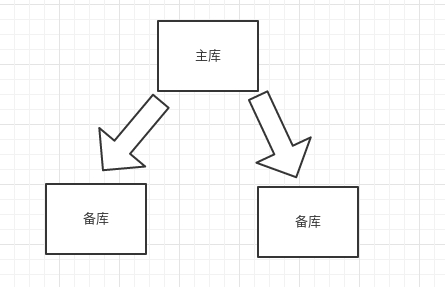
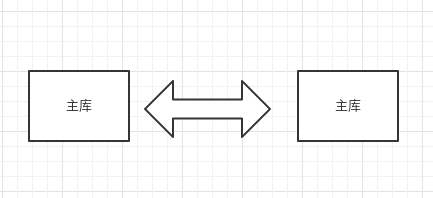
配置从库监听主库
change master to master_host='192.168.31.106',master_port=3306,master_user='tongbu',master_password='123456',master_log_file='mysql-bin.000320',master_log_pos=154;
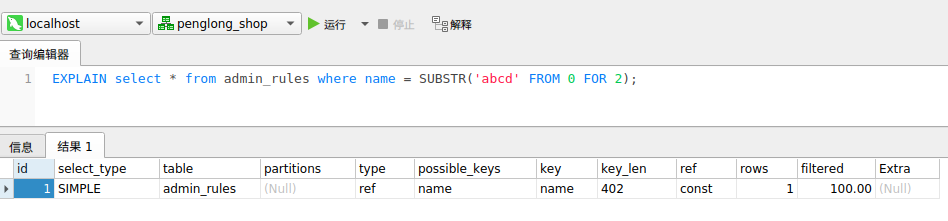
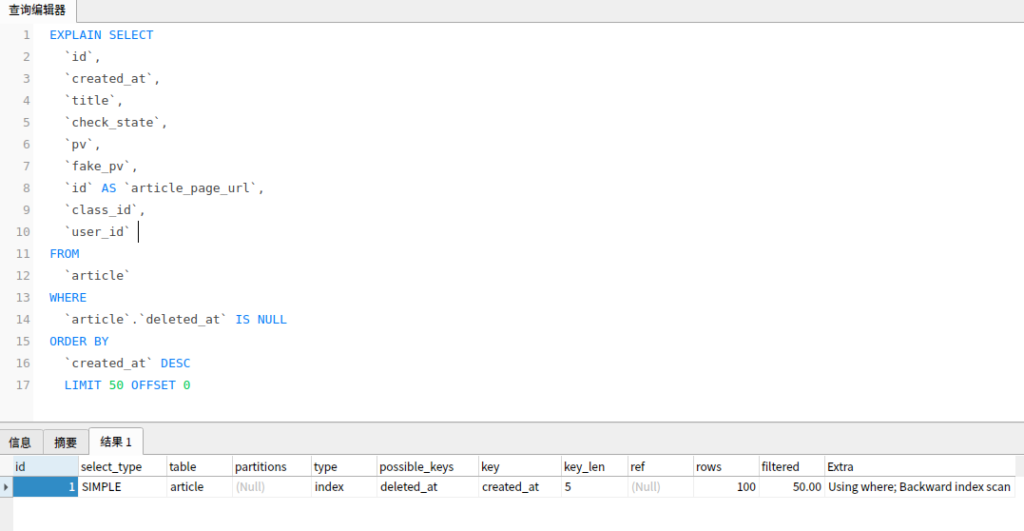
如有索引 (a, b, c, d),查询条件 a = 1 and b = 2 and c = 3 and d > 4,则会在每个节点依次命中 a、b、c,无法命中 d。也就是最左前缀匹配原则。
不需要考虑 =、in 等的顺序,MySQL 会自动优化这些条件的顺序,以匹配尽可能多的索引列。
如有索引 (a, b, c, d),查询条件 c > 3 and b = 2 and a = 1 and d < 4 与 a = 1 and c > 3 and b = 2 and d < 4 等顺序都是可以的,MySQL 会自动优化为 a = 1 and b = 2 and c > 3 and d < 4,依次命中 a、b。
当使用 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE 或 IN() 运算符中的任何一个将键列与常量进行比较时,可以使用范围:
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1 = 10 AND key_part2 IN (10,20,30);