分类: 数据库设计
数据库设计案列分析和经验总结
设计经验总结
掌握ER模型中的基本元素和概念,实体,关系,属性,关系,数据库范式,反范式
单人开发项目时,如果无法很快设计出全部的数据库,可以先设计简单的小部分,然后编码,这样可以提高开发效率效率,如果一直空想会浪费很多时间,任何设计都是逐步完善和迭代的,面对复杂的逻辑,大部分普通程序员都无法一下想出很好的设计方案
关系的度(Degree of a Relationship)
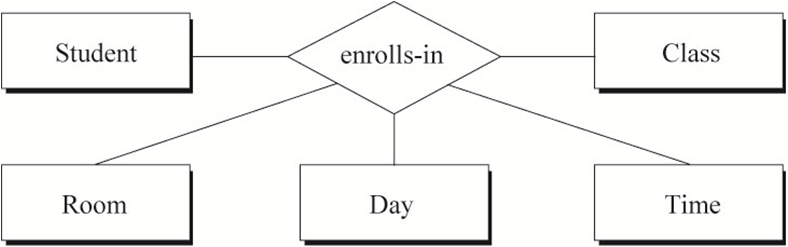
表示几个实体之间的关系,二元关系 ,三元关系,N元关系 ,二元回归关系(例子:无限级分类pid自关联);
在数据表中的体现是一张表中有几个外键;设计时要仔细确定各终端每个需求需要的是几元关系;
将项目拆分模块后,要对模块继续拆分,拆分到每一个页面的每个块数据,转化成具体查询思路
当一个中间表(关系)无法满足需求时,可能需要多个中间表实现;一个实体(表)可以参与到任意多个关系(中间表)中。每个关系可以联系任意多个元(实体 表),而且两个实体(表)之间也能有任意多个二元关系(中间表)。
关系的连通数(Connectivity of a Relationship)
二元(两个表) 的 一对一,一对多,多对多
多元(多个表)的一对一对一.. 一对一对多.. 一对多对多.. 多对多对多.. 可以用数学中的函数依赖表示
关系是强制的还是可以选的
数据库范式
第一范式(1NF)列值必须有具有原子性,不可分割,例如省市区或经纬度不能放到一个字段里
第二范式(2NF)一张表满足第一范式且每个非键属性完全依赖于主键。当一个属性出现在函数依赖式的右端,且函数依赖式的左端为表的主键或可由主键传递派生出的属性组,则该属性完全依赖于主键;通俗的说法就是
第三范式(3NF)一张表满足当且仅当其每个非平凡函数依赖X –> A,其中X和A可为简单或复合属性,必须满足以下两个条件之一。1. X为超键 或 2. A为某候选键的成员。若A为某候选键的成员,则A被称为主属性。注:平凡函数依赖的形式为YZ –> Z
Boyce-Codd范式(BCNF)一张表R满足Boyce-Codd范式(BCNF),若其每一条非平凡函数依赖X –> A中X为超键。
范式总结:
二三范式,多值属性,可变值属性,一张表中有多个事实描述,需要拆成多张表关联,解决插入和更新异常
bcnf范式,删除异常通过中间表加冗余字段来解决,比如删除商品后,订单中需要展示的封面图和商品名称字段不见了需要增加封面图和商品名称冗余字段来保存
范式设计是参考标准,最终以需求为准满足需求的设计才是最适合的设计,避免原教旨主义。
特殊需求反范式设计,提升查询性能
三种设置主键的思路:业务字段做主键、自增字段做主键和手动赋值字段做主键。
业务字段做主键
例用户表使用会员卡做主键,当业务需求发生变化,例如需要将A的会员卡号转给B,会造成用户关联表流水记录出现混乱,A的流水变成了B的流水
以业务字段做主键还有一个可能的后果就是,索引的叶子结点中的内容占用空间可能会比较大,一个页面可能能放入的数据更少了
自增字段做主键
单数据库应用通常使用自增id做主键,例如laravel框架默认使用自增id
当业务需求需要多个数据库分别保存数据库时,例如超市门店要求离线保存并定期最终汇总到一起,自增id就会出现冲突。
手动赋值字段做主键
手动赋值可以上述问题,在总部的数据库里保存一下当前最大id的值,然后插入之前先查询一下id的最大值
UUID和雪花ID能保证主键的唯一性,也可以解决上述需求,分布式系统常用
物理设计注意事项
varchar和char 最大行65535
text类型字段个数限制
案例分析
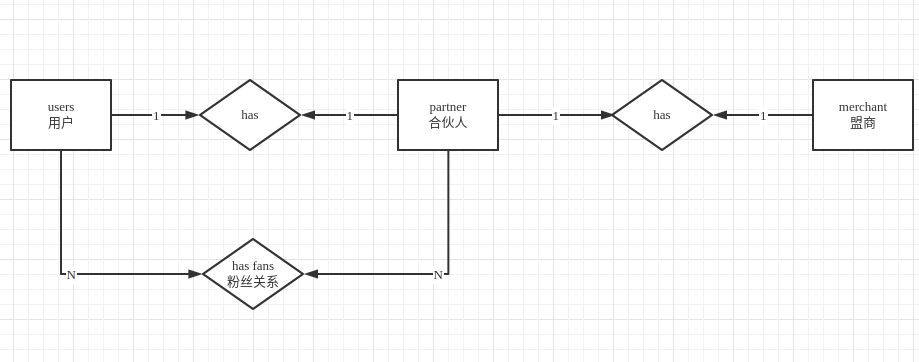
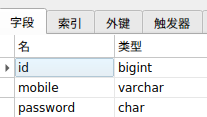
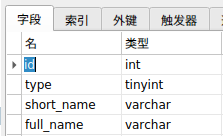
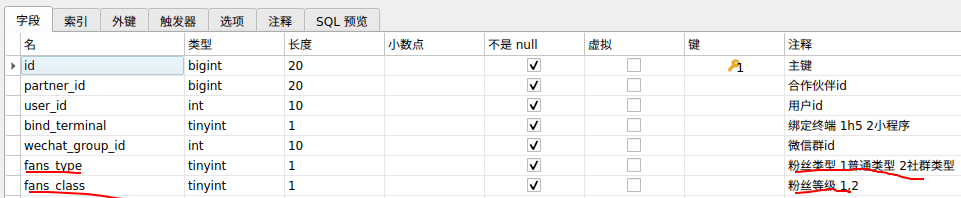
贝宝项目-分销
需求描述
用户和盟商创建时自动生成合伙人,合伙人分享给用户链接,用户点击分享链接时绑定为合伙人的粉丝

点餐项目-手环消息推送
需求描述
用户在餐桌呼叫服务,向餐桌绑定的手环逐个发送消息。如果第一个手环的使用者响应了消息则呼叫服务成功,否则继续向下一个手环发送消息,直至超过最大调度次数。
舍得租赁电商-相机排期
共好电商-多规格SKU
统计需求汇总
总结,
查询简单对性能要求不高的直接查询返回,
查询复杂的按照展示需求单独建表统计,可以基于复杂查询语句的查询结果整个写入统计表中
更复杂的统计用ES实现
点餐统计需求

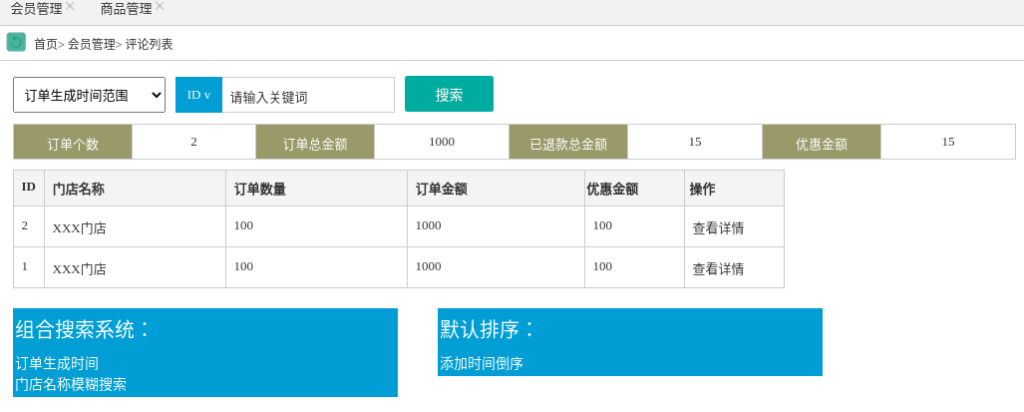
寻草订单交易量统计需求
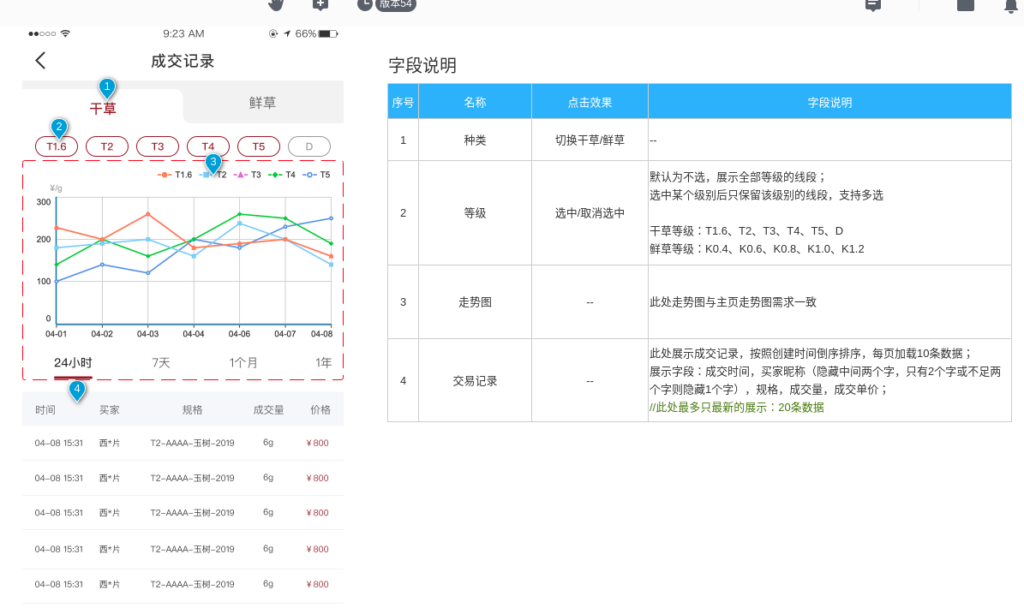
数据库设计Step by Step (11)——通用设计模式(系列完结篇)
阅读原文 转自博客园 知行思新
引言:前文(数据库设计Step by Step (10)——范式化)我们详细讨论了关系数据库范式,始于第一范式止于BCNF范式。至此我们完成了数据库的逻辑设计,如下图所示。

正如首篇博文数据库设计 Step by Step (1)——扬帆启航中介绍的,本系列博文关注通用于所有关系数据库的需求分析与逻辑设计部分。无论你使用的是Oracle,SQL Server,Sybase等商业数据库,亦或是如MySQL,SQLite等开源数据库都能运用这些设计方法来优化设计。数据库的物理设计及实现部分与数据库产品密切相关、各有差异,且内容也非常丰富,故不在本系列中讨论。
本篇博文将分为两个部分,第一部分将介绍数据库设计的一些通用模式,第二部分将对本系列的内容做一个整理并给出一些参考资料供大家参考。

这一小节我们将分析一些较为常见的业务场景,并给出对于这些场景的表结构设计方法。这些方法可以放入我们自己的数据库设计工具箱,当在面对现实需求时可灵活加以运用。
多值属性
多值属性很常见,如淘宝网中每个用户都可以设置多个送货地址,又如在CRM系统中客户可以有多个电话号,一个号码用于工作时间,另一个用于下班时间等。
以存储客户的联系电话为例。联系电话是客户的属性,所以首先可能想到的一种设计方案如下:

图1这一设计满足了当前的需求,但不久我们发现客户的联系电话比我们想象的多,他们还有移动电话,而且有些客户有不止一个办公电话号码,我们需要记录这些电话号码,并标识不同的办公室地点。
对于这种需求,我们可以在Customer表中增加列,但这样做会有两方面的问题:首先,每次增加新列都需要修改数据表结构,需要DBA从后台写脚本完成,且前台显示联系电话的功能模块也需要相应进行修改。其次,每个客户具有的联系电话类型及数量各不相同,大量的联系电话单元格都是空的,浪费了许多存储空间。
我们换一种设计方案。每个客户有多个不同类型的联系电话,可以把联系电话作为弱实体从原先Customer实体中分离出来,如图2所示:

Customer与Phones之间为“一对多”关系,即一个客户可以有多个不同类型的联系电话。当我们需要给某客户增加联系电话时,我们不再需要修改表结构,只需要在Phones表中增加记录就可以了。这完全可以作为前台的功能让业务操作人员来完成,而且现在的Customer不再会存在大量空单元格了。在关系数据库中增加行比增加列的代价要小很多。
实体Phones的主键是什么?
CustID肯定是主键的一部分。主键包含的其他列根据我们想表达的不同语义,可以有所不同。
语义1:一个客户不能有重复的联系类型。即一个客户的每个PhoneType不能重复,但多个不同的PhoneType可能对应相同的PhoneNum(如:PhoneType为“Office”和“Home”对应同一个号码)。符合该语义的主键为:CustID,PhoneType;
语义2:一个客户不能有重复的联系电话。即一个客户的每个PhoneNum不能重复,但多个不同的PhoneNum可能对应相同的PhoneType(如:PhoneType为“Office”有多个不同号码)。符合该语义的主键为:CustID,PhoneNum;
语义3:一个客户的一个联系类型能有多个不同的联系电话,一个联系电话可能对应不同的联系类型。符合该语义的主键为:CustID,PhoneType,PhoneNum;
举一反三,该多值属性设计方法同样适用于维护客户的多个地址或Email等场景。
历史追溯
说到历史就会涉及时间。例如:当前物价持续上涨,同一产品的售价每个月都有可能调整,若要追溯产品价格变化的情况,仅仅记录该产品当前的一个售价是不足够的。同样对于银行中的利率变化,购入原材料的单价变化等,都需要进行历史追溯。
要跟踪一个实体随时间的变化可以在该实体中增加属性列,指明实体中每个实例的有效日期。图3展示了可追溯产品价格的订单结构(已经过简化)。

实体Orders记录订单的公共信息,包括订单号(OrderID),下订单的时间(OrderDate),客户编号(CustomerID)等。其中OrderID提供了到实体OrderItems的联接。实体OrderItems记录客户订购的产品条目,包括所属订单号(OrderID),产品编号(ProductID),订购数量(Quantity)等。其中ProductID能联接到实体Products。实体Products中包含每种产品的描述信息。实体ProductPrices记录了产品的价格,包括产品编号(ProductID)对应到Products实体,产品价格(Price),以及该价格的有效时间段(EffectiveStartDate,EffectiveEndDate)。
对于上述表结构,回溯历史某个订单的信息的步骤如下:
1. 根据订单号(OrderID)在Orders表中找到对应的记录,并记录下OrderDate
2. 在OrderItems表中根据OrderID找到对应的所有订单明细记录。对每一条明细,记录下Quantity和ProductID,之后:
a. 通过ProductID,在Products表中找到对应产品的产品描述(Description)
b. 在ProductPrices表中找到对应ProductID,且EffectiveStartDate <= OrderDate < EffectiveEndDate的记录。该记录中的Price为指定产品在历史下单时的价格。
这样我们就得到了该订单的历史“快照”信息。
需要注意的几点:
1. 如果我们只需要追溯订单中产品的历史价格,可省去上述步骤中的a。
2. 上述订单表结构在每次查看订单时都需要查询ProductPrices表。我们可以通过在OrderItems表中增加ItemPrice列,来避免对ProductPrices表的频繁查询。当创建订单明细记录时,把从ProductPrices中查询到的价格记录到ItemPrice列中,之后每次查看订单时就不需要再查询ProductPrices表了。
3. ProductPrices表的主键为ProductID,EffectiveStartDate。同时该表还隐含着约束:同一种产品的价格有效时间段不能重叠。
4. ProductPrices表结构中EffectiveEndDate列可省去,把该产品的下一个EffectiveStartDate作为上一个有效时间段的自然结束时间点。但这样做会增加查询的复杂度。
在举一个简单的例子,每个客户只有一个地址信息,但希望能跟踪客户地址的变更情况。我们能设计如下(图4)表结构:

类似的场景包括:跟踪员工薪资的变化情况,跟踪汇率的变化情况等等。还有一种场景可使用该技术,当我们通过系统前台试图删除某信息时,系统的后台数据库并不真正去做删除操作,而是通过EffectiveEndDate标识记录的无效时间。通过EffectiveStartDate和EffectiveEndDate可回溯任何历史时间点存在的记录“快照”。
树型结构
树型结构最典型的例子是员工组织机构图,如图5所示。
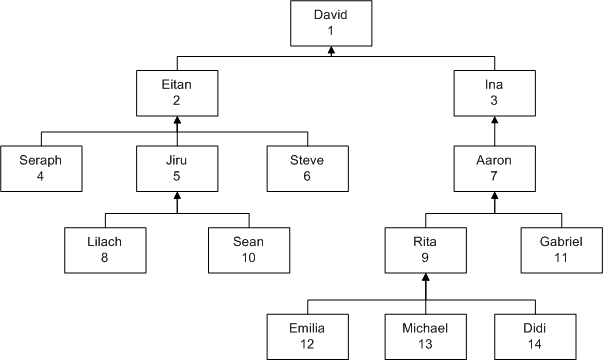
树型结构中除根节点之外,每一个子节点都有一个父节点。可以把节点建模为一个实体,父子之间的联系建模为“一对多回归关系”。图5中的员工组织结构可建模为图6所示的ER结构。
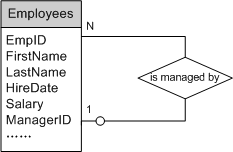
实体Employees中的EmpID,FirstName,LastName,HireDate,Salary等属性描述了员工的基本信息,树型层次关系通过ManagerID属性进行描述,该属性存储了该员工的经理ID,即指向其父节点。
在节点实体中存储指向父节点的属性已足够描述树型结构的语义,但为了提高查询的效率,设计中可增加树型结构层次(Lvl)和物化路径(Path)作为辅助信息。图5员工组织结构样例数据如下:
| EmpID | FirstName | LastName HireDate … | ManagerID | Lvl | Path |
| 1 | David | …… | NULL | 0 | .1. |
| 2 | Eitan | …… | 1 | 1 | .1.2. |
| 4 | Seraph | …… | 2 | 2 | .1.2.4. |
| 5 | Jiru | …… | 2 | 2 | .1.2.5. |
| 10 | Sean | …… | 5 | 3 | .1.2.5.10. |
| 8 | Lilach | …… | 5 | 3 | .1.2.5.8. |
| 6 | Steve | …… | 2 | 2 | .1.2.6. |
| 3 | Ina | …… | 1 | 1 | .1.3. |
| 7 | Aaron | …… | 3 | 2 | .1.3.7. |
| 11 | Gabriel | …… | 7 | 3 | .1.3.7.11. |
| 9 | Rita | …… | 7 | 3 | .1.3.7.9. |
| 12 | Emilia | …… | 9 | 4 | .1.3.7.9.12. |
| 13 | Michael | …… | 9 | 4 | .1.3.7.9.13. |
| 14 | Didi | …… | 9 | 4 | .1.3.7.9.14. |
(表1 员工组织结构数据,其中Lvl列,Path列可选,利用该两列能提升某些查询的性能)
注:如何对树型结构数据表进行查询、遍历在这里不进行展开,可参考《Inside Microsoft SQL Server 2005 T-SQL Querying》一书。本例及以下两小节中的例子,引用自《Inside Microsoft SQL Server 2005 T-SQL Querying》,但同样适用于其他关系数据库。
有向无环图结构
有向无环图(DAG)的典型应用场景是物料清单(BOM)。BOM记录了产品的组装零件或配置方式,下图为某咖啡店的BOM图,描述了配置每种饮料的原料及剂量。
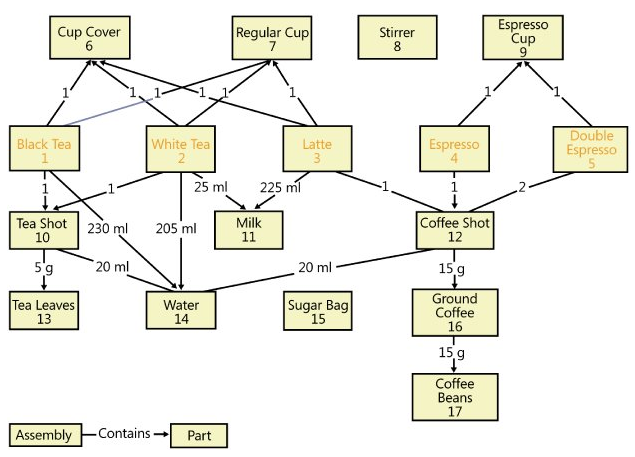
我们如何把这一BOM信息存储到数据库中呢?
BOM场景以有向无环图为模型。有向无环图与树型层次结构的差异之处在于,有向无环图中的一个节点能有多个父节点。故ER模型中,有向无环图需建模成两个实体,一个实体用于描述节点,另一个实体用于描述节点之间的边。咖啡店BOM场景的ER模型如图7所示,实体Parts表示咖啡店的原料及饮品,实体Assemble表示原料配置的方向(即“有向边”),其中还包括边的权值,此例中边的权值为qty,表示配料的剂量,unit为配料的剂量单位(如:g,ml等)。
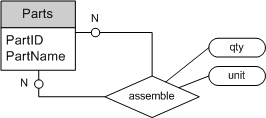
把咖啡店BOM的ER图转化为SQL:
create table Parts
(
PartID int not null primary key,
PartName varchar(25) not null
);
create table Assemble
(
PartID int not null references Parts,
AssemblyID int not null references Parts,
Unit varchar(3) not null,
Qty decimal(8,2) not null,
primary key(PartID, AssemblyID),
check(PartID <> AssemblyID)
);需要注意以下几点:
1. 上述代码在SQL Server 2008下测试通过。对于其他数据库产品,代码细节可能需稍作调整,但主体设计结构不变。
2. Assemble表的主键为:PartID,AssemblyID。
3. Assemble表的PartID列和AssemblyID列外键引用Parts表。
4. Assemble表的check约束保证其中任何记录的PartID与AssemblyID的值不会相同。
无向循环图结构
无向循环图的一个典型例子是城市道路系统。下图展示了美国主要城市之间的道路
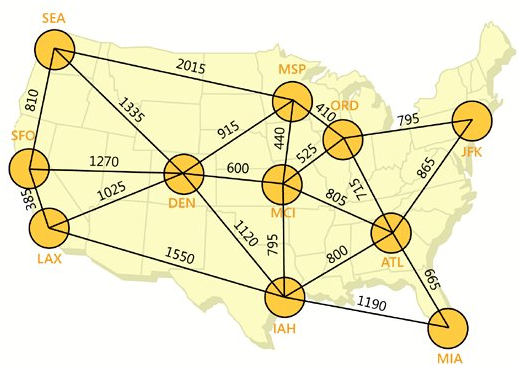
图8中每个节点表示一个城市,城市之间的连线代表城市之间的道路,连线上的数值表示距离。道路系统以无向循环图为模型,无向循环图中的节点能与任意数量的其他节点相连,且相连接的节点之间没有父子或先后关系(即“边”没有方向)。对图8中的道路系统进行ER建模得:
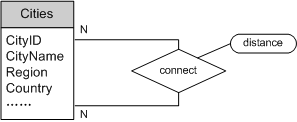
把图9中的ER模型转化为SQL:
create table Cities
(
CityID char(3) not null primary key,
CityName varchar(30) not null,
Region varchar(30) not null,
Country varchar(30) not null
);
create table Roads
(
CityID char(3) not null references Cities,
DestID char(3) not null references Cities,
Distance int not null,
primary key(CityID, DestID),
check(CityID < DestID),
check(Distance > 0)
);需要注意以下几点:
1. 上述代码在SQL Server 2008下测试通过。对于其他数据库产品,代码细节可能需稍作调整,但主体设计结构不变。
2. 为了更易于理解,图9道路系统ER模型中的关系connect,在转化为SQL表时更名为Roads。Roads表描述了一个无向循环赋权图。表中每一行表示一条边(道路)。Distance属性表示权值(城市间的距离)。
3. Roads表的CityID列和DestID列外键引用CityID表。
4. Roads表的主键为CityID,DestID。
5. Roads表中包含check约束(CityID < DestID),以避免存入两个相同的边(eg:“芝加哥到纽约”和“纽约到芝加哥”)。无向循环图中节点之间是平等的,故该约束很重要,避免冗余数据。
6. 若要扩展到“有向循环图”场景(如:道路系统中的单行道),我们只要去除check约束(CityID < DestID),此时不同方向的数据不再是冗余。

到这里整个系列将告一段落,希望大家能觉得该系列言之有物,读了能有些许收获。最后,对本系列博文作一个回顾,同时给出一些参考资料。
本系列篇目回顾
1. 数据库设计 Step by Step (1)——扬帆启航
2. 数据库设计 Step by Step (2)——数据库生命周期
3. 数据库设计 Step by Step (3)——基本ER模型构件
4. 数据库设计 Step by Step (4)——高级ER模型构件
5. 数据库设计 Step by Step (5)——理解用户需求
6. 数据库设计 Step by Step (6) —— 提取业务规则
7. 数据库设计Step by Step (7)——概念数据建模
8. 数据库设计 Step by Step (8)——视图集成
9. 数据库设计Step by Step (9)——ER-to-SQL转化
10. 数据库设计Step by Step (10)——范式化
11. 数据库设计Step by Step (11)——通用设计模式(系列完结篇)
参考资料
以下推荐的两本书虽然不是关于数据库设计,但对于程序开发人员会有帮助。熟练掌握数据库查询与编程能促进对数据库设计的理解与学习。
1. 《Inside Microsoft SQL Server 2005 T-SQL Querying》——这是我当初看的一本书,对于深入理解数据库查询很有帮助。现在已经出了《Inside Microsoft SQL Server 2008 T-SQL Querying》。
2. 《Inside Microsoft SQL Server 2005 T-SQL Programming》——对于学习T-SQL编程很有助益。
数据库设计Step by Step (10)——范式化
阅读原文 转自博客园 知行思新
引言:前文(数据库设计Step by Step (9)——ER-to-SQL转化)讨论了如何把ER图转化为关系表结构。本文将介绍数据库范式并讨论如何范式化候选表。我们先来看一下此刻处在数据库生命周期中的位置(如下图所示)。
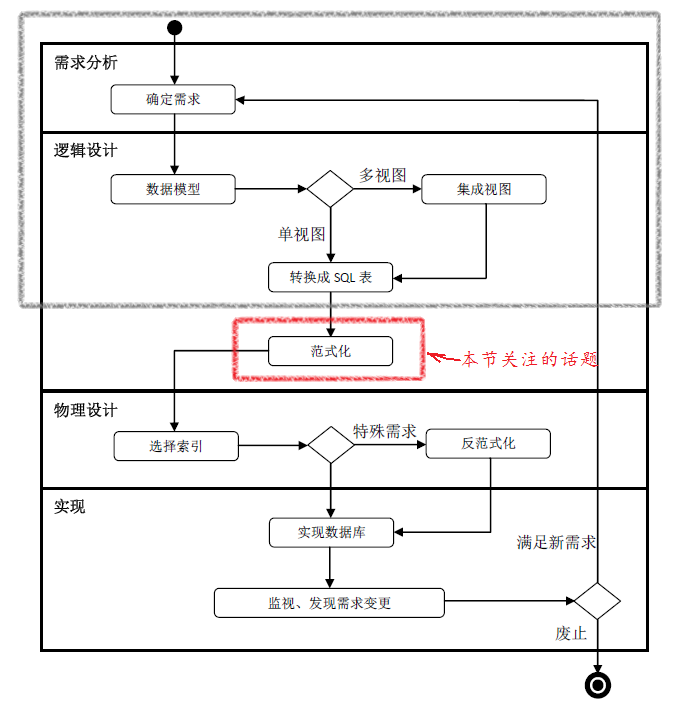
前几篇博文中我们详细的讨论了ER建模的方法。精心设计的ER模型将帮助我们直接得到范式化的表或只需稍许修改即为范式化的表,设计、绘制ER图的重要性也体现在这里。概念数据建模(ER建模)从一开始就潜移默化的引导着我们走向范式化的数据库表结构。
本文的讨论将始于第一范式,止于BCNF范式。在现实数据库设计中,一般需达到的范式化目标是第三或BCNF范式,更高级别的范式更多的是理论价值,本文也不将涉及。

范式基础
关系数据库中的表有时会面对性能、一致性和可维护性方面的问题。举例来说,把整个数据库中的数据都定义在一张表中将导致大量冗余的数据,低效的查询和更新性能,对某些数据的删除将造成有用数据的丢失等。如图1所示,products, salespersons, customers, orders都存储在一张名为Sales的表中。
| product_name | order_no | cust_name | cust_addr | credit | date | sales_name |
| vacuum cleaner | 1435 | Dave | Austin | 6 | 2010-03-01 | Carl |
| computer | 2730 | Qiang | Plymouth | 10 | 2011-04-15 | Ted |
| refrigerator | 2460 | Mike | Ann Arbor | 8 | 2010-09-12 | Dick |
| DVD player | 519 | Peter | Detroit | 3 | 2010-12-05 | Fred |
| radio | 1986 | Charles | Chicago | 7 | 2011-05-10 | Richard |
| CD player | 1817 | Eric | Mumbai | 8 | 2010-08-03 | Paul |
| vacuum cleaner | 1865 | Charles | Chicago | 7 | 2010-10-01 | Carl |
| vacuum cleaner | 1885 | Betsy | Detroit | 8 | 2009-04-19 | Carl |
| refrigerator | 1943 | Dave | Austin | 6 | 2011-01-04 | Dick |
| television | 2315 | Sakti | East Lansing | 6 | 2011-03-15 | Fred |
(图1 Sales表)
在这张表中,某些产品和客户信息是冗余的,浪费了存储空间。某些查询如“上个月哪些客户订购了吸尘器”需要搜索整张表。当要修改客户Dave的地址需要更新该表的多条记录。最后删除客户Qiang的订单(2730)将造成该客户姓名、地址、信用级别信息的丢失,因为该客户只有唯一这个订单。
如果我们通过一些方法把该大表拆分成多个小表,从而消除上述这些问题使数据库更为高效和可靠,范式化就是为了达到这一目标。范式化是指通过分析表中各属性之间的互相依赖,并把大表映射为多个小表的过程。
第一范式(1NF)
定义:当且仅当一张表的所有列只包含原子值时,即表中每行中的每一个列只有一个值,则该表符合第一范式。
图1中的Sales表的每一行、每一列中只有原子值,故Sales表满足第一范式。
为了更好的理解第一范式,我们讨论一下域、属性、列之间的差异。
域是某属性所有可能值的集合,但同一个域可能被用于多个属性上。举例来说,人名的域包含所有可能的姓名集合,在图1的表中可用于cust_name或sales_name属性。每一列代表一个属性,有些情况下代表不同属性的多个列具有相同的域,这并不会违反第一范式,因为表中的值仍是原子的。
仅符合第一范式的表常会遇到数据重复、更新性能以及更新一致性等问题。为了更好的理解这些问题,我们必须定义键的概念。
超键是一个或多个属性的集合,其能帮助我们唯一确定一条记录。若组成超键属性列的子集仍为一个超键,但该子集少了任何一个属性都将使其不再是一个超键,则该属性列子集称为候选键。主键是从一张表的候选键集合中任意挑选出的,作为该表的一个索引。
作为一个例子,图2中表的所有属性组成一个超键。
| report_no | editor | dept_no | dept_name | dept_addr | author_id | author_name | author_addr |
| 4216 | woolf | 15 | design | argus1 | 53 | mantei | cs-tor |
| 4216 | woolf | 15 | design | argus1 | 44 | bolton | mathrev |
| 4216 | woolf | 15 | design | argus1 | 71 | koenig | mathrev |
| 5789 | koenig | 27 | analysis | argus2 | 26 | fry | folkstone |
| 5789 | koenig | 27 | analysis | argus2 | 38 | umar | prise |
| 5789 | koenig | 27 | analysis | argus2 | 71 | koenig | mathrev |
(图2 Report表)
在关系模型中不允许有重复的行,因此一个明显的超键是表的所有列(属性)的组合。假设表中每一个部门的地址(dept_addr)都相同,则除dept_addr之外的属性仍然是一个超键。对其他属性作类似的假设,逐步缩小属性的组合。我们发现属性组合report_no, author_id能唯一确定表中的其他属性,即是一个超键。同时report_no或author_id中的任意一个都无法唯一确定表中的一行,故属性组合report_no, author_id是一个候选键。由于它们是该表的唯一候选键,它们也是该表的主键。
一张表能有多个候选键。举例来说,在图2中,若有附加列author_ssn(SSN:社会保险号),属性组合report_no, author_ssn也能唯一确定表中的其他属性。因此属性组合(report_no, author_id)和(report_no, author_ssn)都是候选键,可以任选其一作为主键。
第二范式(2NF)
为了解释第二以及更高级别范式。我们需引入函数依赖的概念。一个或多个属性值能唯一确定一个或多个其他属性值称为函数依赖。给定某表(R),一组属性(B)函数依赖于另一组属性(A),即在任意时刻每个A值只与唯一的B值相关联。这一函数依赖用A –> B表示。以图2中的表为例,表report的函数依赖如下:
report: report_no –> editor, dept_no
dept_no –> dept_name, dept_addr
author_id –> author_name, author_addr
定义:一张表满足第二范式(2NF)的条件是当且仅当该表满足第一范式且每个非键属性完全依赖于主键。当一个属性出现在函数依赖式的右端,且函数依赖式的左端为表的主键或可由主键传递派生出的属性组,则该属性完全依赖于主键。
report表中一个传递函数依赖的例子:
report_no –> dept_no
dept_no –> dept_name
因为我们能派生出函数依赖(report_no –> dept_name),即dept_name传递依赖于report_no。
继续我们的例子,图2中表的复合键(report_no, author_id)是唯一的候选键,即为表的主键。该表存在一个FD(dept_no –> dept_name, dept_addr),其左端没有主键的任何组成部分。该表的另两个FD(report_no –> editor, dept_no和author_id –> author_name, author_addr)的左端包含主键的一部分但不是全部。故report表的任何一条FD都不满足第二范式的条件。
思考一下仅满足第一范式的report表的缺陷。report_no, editor和dept_no对该Report的每一位author都需要重复,故当Report的editor需要变更时,多条记录必须同步修改。这就是所谓的更新异常(update anomaly),冗余的更新会降低性能。当没有把所有符合条件的记录同步更新时,还会造成数据的不一致。若要在表中加入一位新的author,只有在该author参与了某Report的撰写才能插入该author的记录,这就是所谓的插入异常(insert anomaly)。最后,若某一张Report无效了,所有与该Report相关联的记录必须一起删除。这可能造成author信息的丢失(与该Report相关联的author_id, author_name, author_addr也被删除了)。这一副作用被称为删除异常(delete anomaly),使数据丧失了完整性。
上述这些缺陷可通过把仅满足第一范式的表转化为多张满足第二范式的表来克服。在保留原先函数依赖和语义关系的前提下,把Report表映射为三张小表(report1, report2, report3),其中包含的数据如图3所示。
Report 1
| report_no | editor | dept_no | dept_name | dept_addr |
| 4216 | woolf | 15 | design | argus 1 |
| 5789 | koenig | 27 | analysis | argus 2 |
Report 2
| author_id | author_name | author_addr |
| 53 | mantei | cs-tor |
| 44 | bolton | mathrev |
| 71 | koenig | mathrev |
| 26 | fry | folkstone |
| 38 | umar | prise |
| 71 | koenig | mathrev |
Report 3
| report_no | author_id |
| 4216 | 53 |
| 4216 | 44 |
| 4216 | 71 |
| 5789 | 26 |
| 5789 | 38 |
| 5789 | 71 |
(图3 2NF表)
这些满足第二范式表的函数依赖为:
report1: report_no –> editor, dept_no
dept_no –> dept_name, dept_addr
report2: author_id –> author_name, author_addr
report3: report_no, author_id为候选键,无函数依赖
现在我们已得到了三张满足第二范式的表,消除了第一范式表存在的最糟糕的问题。第一、editor, dept_no, dept_name, dept_addr不再需要为每一位author重复。第二、更改一位editor只需要更新report1的一条记录。第三、删除report不再会造成author信息丢失的副作用。
我们可以注意到这三张满足第二范式的表可以直接从ER图转化得到。ER图中的Author、Report实体以及之间的“多对多”关系可根据上一篇博文(数据库设计Step by Step (9)——ER-to-SQL转化)的规则很自然的转化为三张表。
第三范式(3NF)
第二范式相对于第一范式已经有了巨大的进步,但由于存在传递依赖(transitive dependency),满足第二范式的表仍会存在数据操作异常(anomaly)。当一张表中存在传递依赖,其意味着该表中描述了两个单独的事实。每个事实对应于一条函数依赖,函数依赖的左侧各不相同。举例来说,删除一个report,其包含删除report1和report3表中的相应记录(如图3所示),该删除动作的副作用是dept_no, dept_name, dept_addr信息也被删除了。如果把表report1映射为包含列report_no, editor, dept_no的表report11和包含列dept_no, dept_name, dept_addr的表report12(如图4所示),我们就能消除上述问题。
Report11
| report_no | editor | dept_no |
| 4216 | woolf | 15 |
| 5789 | koenig | 27 |
Report12
| dept_no | dept_name | dept_addr |
| 15 | design | argus 1 |
| 27 | analysis | argus 2 |
Report 2
| author_id | author_name | author_addr |
| 53 | mantei | cs-tor |
| 44 | bolton | mathrev |
| 71 | koenig | mathrev |
| 26 | fry | folkstone |
| 38 | umar | prise |
| 71 | koenig | mathrev |
Report 3
| report_no | author_id |
| 4216 | 53 |
| 4216 | 44 |
| 4216 | 71 |
| 5789 | 26 |
| 5789 | 38 |
| 5789 | 71 |
(图4 3NF表)
定义:一张表满足第三范式(3NF)当且仅当其每个非平凡函数依赖X –> A,其中X和A可为简单或复合属性,必须满足以下两个条件之一。1. X为超键 或 2. A为某候选键的成员。若A为某候选键的成员,则A被称为主属性。注:平凡函数依赖的形式为YZ –> Z。
在上述例子中通过把report1映射为report11和report12,消除了传递依赖report_no –> dept_no –> dept_name, dept_addr,我们得到了如图4所示的第三范式表及函数依赖:
report11: repot_no –> editor, dept_no
report12: dept_no –> dept_name, dept_addr
report2: author_id –> author_name, author_addr
report3: report_no, author_id为候选键(无函数依赖)
Boyce-Codd范式(BCNF)
第三范式消除了大部分的异常,也是商业数据库设计中达到的最普遍的标准。剩下的异常情况可通过Boyce-Codd范式(BCNF)或更高级别范式来消除。BCNF范式可看作加强的第三范式。
定义:一张表R满足Boyce-Codd范式(BCNF),若其每一条非平凡函数依赖X –> A中X为超键。
BCNF范式是比第三范式更高级别的范式因为其去除了第三范式中的第二种条件(允许函数依赖右侧为主属性),即表的每一条函数依赖的左侧必须为超键。每一张满足BCNF范式的表同时满足第三范式、第二范式和第一范式。
以下的例子展示了一张满足第三范式但不满足BCNF范式的表。这样的表和那些仅满足较低范式的表一样存在删除异常。
断言1:一个小组里的每一名员工只由一位领导来管理。一个小组可能有多位领导。
emp_name, team_name –> leader_name
断言2:每一位领导只会参与一个组的管理。
leader_name –> team_name
| emp_name | team_name | leader_name |
| Sutton | Hawks | Wei |
| Sutton | Condors | Bachmann |
| Niven | Hawks | Wei |
| Niven | Eagles | Makowski |
| Wilson | Eagles | DeSmith |
(图5 team表)
team表满足第三范式,具有复合候选键emp_name, team_name
team表有如下删除异常:若Sutton离开了Condors组,Bachmann为Condors组的领导这一信息将丢失。
消除这一删除异常最简单的方法是根据两条断言创建两张表,通过两张表中冗余的信息来消除删除异常。这一分解是无损的并保持了所有原先的函数依赖,但这降低了更新性能,并需要更多存储空间。为了避免删除异常,这样做是值得的。
注:无损分解是指把一张表分解为两张小表后,通过对两张小表进行natural join得到的表与原始表相同,不会产生任何多余行。

数据库范式化示例
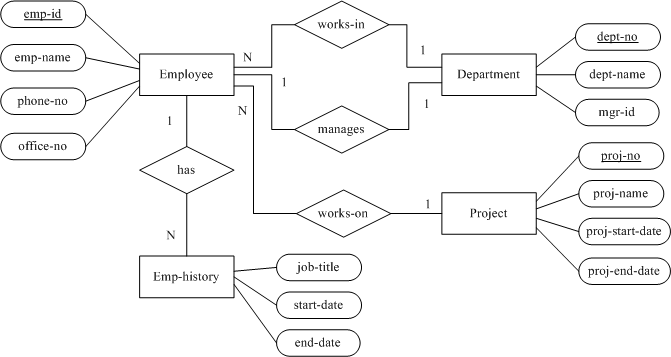
该案例基于图6中的ER模型和以下相关函数依赖。一般而言,函数依赖可通过分析ER图及业务经验推得。
- emp_id, start_date –> job_title, end_date
- emp_id –> emp_name, phone_no, office_no, proj_no, proj_name, dept_no
- phone_no –> office_no
- proj_no –> proj_name, proj_start_date, proj_end_date
- dept_no –> dept_name, mgr_id
- mgr_id –> dept_no
我们的目标是设计至少能达到第三范式(3NF)的关系数据库表结构,并尽可能减少表的数量。
如果将函数依赖1至6放入一张表,并设置复合主键:emp_id, start_date,那么我们违反了第三范式,因为函数依赖2至6的等式左侧不是超键。因此,我们需要把函数依赖1从其余的函数依赖中分离出来。如果将函数依赖2至6进行合并,我们将得到很多传递依赖。故函数依赖2、3、4、5必须分到不同的表中。我们再来考虑函数依赖5和6是否能在不违反第三范式的前提下进行合并。因为mgr_id和dept_no是相互依赖的,这两个属性在表中都是超键,所以可以合并。
通过合理的映射函数依赖1至6,我们能得到如下表:
emp_hist: emp_id, start_date –> job_title, end_date
employee: emp_id –> emp_name, phone_no, proj_no, dept_no
phone: phone_no –> office_no
project: proj_no –> proj_name, proj_start_date, proj_end_date
department: dept_no –> dept_name, mgr_id
mgr_id –> dept_no
这一解决方案涵盖了所有函数依赖。满足第三范式和BCNF范式,同时该方案创建了最少数量的表。
范式化从ER图得到的候选表
在数据库生命周期中,对表的范式化是通过分析表的函数依赖完成的。这些函数依赖包括:从需求分析中得到的函数依赖;从ER图中得到的函数依赖;从直觉中得到的函数依赖。
主函数依赖代表了实体键之间的依赖。次函数依赖代表实体内数据元素间的依赖。一般来说,主函数依赖可从ER图中得到,次函数依赖可从需求分析中得到。表1展示了每种基本ER构件所能得到的主函数依赖。
| 关系的度(Degree) | 关系的连通数(Connectivity) | 主函数依赖 |
| 二元或二元回归 | “一对一” “一对多” “多对多” | 2个:键(“一”侧) –> 键(“一”侧) 1个:键(“多”侧) –> 键(“一”侧) 无(由两侧键组成的组合键) |
| 三元 | “一对一对一” “一对一对多” “一对多对多” “多对多对多” | 3个:键(“一”),键(“一”) –> 键(“一”) 2个:键(“一”),键(“多”) –> 键(“一”) 1个:键(“多”),键(“多”) –> 键(“一”) 无(有三侧键组成的组合键) |
| 泛化 | 无 | 无 |
每个候选表一般会有多个主函数依赖和次函数依赖,这决定了当前表的范式化程度。对每个表采用各种技术使其达到需求规格中要求的范式化程度,在范式化过程中要保证数据完整性,即范式化后得到的表应包含原先候选表的所有函数依赖。精心设计的概念数据模型通常能得到基本已范式化的表,后期的范式化处理不会很困难,所以概念数据建模非常重要。

主要内容回顾
1. 不良的表结构设计将导致表数据的更新异常(update anomaly)、插入异常(insert anomaly)、删除异常(delete anomaly)
2. 范式化通过消除冗余数据,来解决数据库存在的一致性、完整性和可维护性等方面的问题。
3. 在实际数据库设计中,范式化的目标一般是达到第三范式或BCNF范式。
4. 精心设计的概念数据模型(ER模型)能帮助我们得到范式化的表。
数据库范式化参考资料
1. Database Normalization(http://en.wikipedia.org/wiki/Database_normalization)
2. 3 Normal Forms Database Tutorial(http://www.phlonx.com/resources/nf3/)
数据库设计Step by Step (9)——ER-to-SQL转化
阅读原文 转自博客园 知行思新
引言:前文(数据库设计 Step by Step (8)——视图集成)讨论了如何把局部ER图集成为全局ER图。有了全局ER图后,我们就可以把ER图转化为关系数据库中的SQL表了。俯瞰整个数据库生命周期(如下图所示),找到我们的“坐标”。
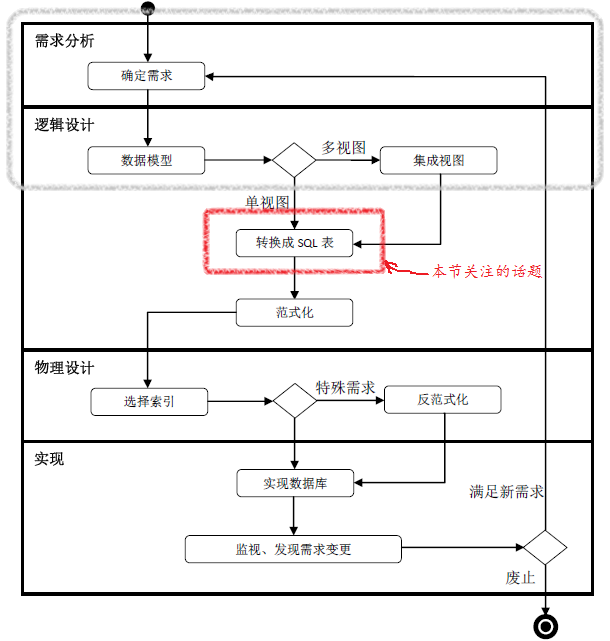
把ER图转化为关系数据库中的表结构是一个非常自然的过程。许多ER建模工具除了辅助绘制ER图外,还能自动地把ER图转化为SQL表。

从ER模型到SQL表
从ER图转化得到关系数据库中的SQL表,一般可分为3类。
1. 转化得到的SQL表与原始实体包含相同信息内容。该类转化一般适用于:
二元“多对多”关系中,任何一端的实体
二元“一对多”关系中,“一”一端的实体
二元“一对一”关系中,某一端的实体
二元“多对多”回归关系中,任何一端的实体(注:关系两端都指向同一个实体)
三元或n元关系中,任何一端的实体
层次泛化关系中,超类实体
2. 转化得到的SQL表除了包含原始实体的信息内容之外,还包含原始实体父实体的外键。该类转化一般适用于:
二元“一对多”关系中,“多”一端的实体
二元“一对一”关系中,某一端的实体
二元“一对一”或“一对多”回归关系中,任何一端的实体
该转化是处理关系的常用方法之一,即在子表中增加指向父表中主键的外键信息。
3. 由“关系”转化得到的SQL表,该表包含“关系”所涉及的所有实体的外键,以及该“关系”自身的属性信息。该类转化一般适用于:
二元“多对多”关系
二元“多对多”回归关系
三元或n元关系
该转化是另一种常用的关系处理方法。对于“多对多”关系需要定义为一张包含两个相关实体主键的独立表,该表还能包含关系的属性信息。
转化过程中对于NULL值的处理规则
1. 当实体之间的关系是可选的,SQL表中的外键列允许为NULL。
2. 当实体之间的关系是强制的,SQL表中的外键列不允许为NULL。
3. 由“多对多”关系转化得到的SQL表,其中的任意外键列都不允许为NULL。
一般二元关系的转化
1. “一对一”,两实体都为强制存在
当两个实体都是强制存在的(如图1所示),每一个实体都对应转化为一张SQL表,并选择两个实体中任意一个作为主表,把它的主键放入另一个实体对应的SQL表中作为外键,该表称为从表。
 (图1 “一对一”,两实体都为强制存在)
(图1 “一对一”,两实体都为强制存在)
图1表示的语义为:每一张报表都有一个缩写,每一缩写只代表一张报表。转化得到的SQL表定义如下:

注:本节中所有SQL代码在SQL Server 2008环境中测试通过。
2. “一对一”,一实体可选存在,另一实体强制存在
当两个实体中有一个为“可选的”,则“可选的”实体对应的SQL表一般作为从表,包含指向另一实体的外键(如图2所示)

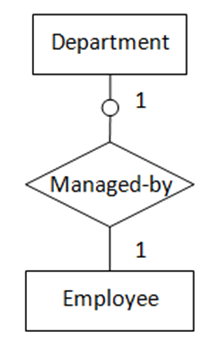
图2表示的语义为:每一个部门必须有一位经理,大部分员工不是经理,一名员工最多只能是一个部门的经理。转化得到的SQL表定义如下:
create table employee
(
emp_id char(10),
emp_name char(20),
primary key(emp_id)
);
create table department
(
dept_no integer,
dept_name char(20),
mgr_id char(10) not null unique,
primary key(dept_no),
foreign key(mgr_id) references employee
on update cascade
);另一种转化方式是把“可选的”实体作为主表,让“强制存在的”实体作为从表,包含外键指向“可选的”实体,这种方式外键列允许为NULL。以图2为例,可把实体Employee转化为从表,包含外键列dept_no指向实体Department,该外键列将允许为NULL。因为Employee的数量远大于Department的数量,故会占用更多的存储空间。
3. “一对一”,两实体都为可选存在
当两个实体都是可选的(如图3所示),可选任意一个实体包含外键指向另一实体,外键列允许为NULL值。
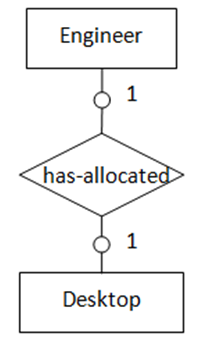
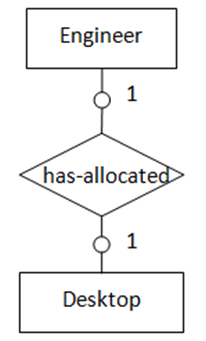 (图3 “一对一”,两实体都为可选存在)
(图3 “一对一”,两实体都为可选存在)图3表示的语义为:部分台式电脑被分配给部分工程师,一台电脑只能分配给一名工程师,一名工程师最多只能分配到一台电脑。转化得到的SQL表定义如下:
create table engineer
(
emp_id char(10),
emp_name char(20),
primary key(emp_id)
);
create table desktop
(
desktop_no integer,
emp_id char(10),
primary key(desktop_no),
foreign key(emp_id) references engineer
on delete set null on update cascade
);4. “一对多”,两实体都为强制存在
在“一对多”关系中,无论“多”端是强制存在的还是可选存在的都不会影响其转化形式,外键必须出现在“多”端,即“多”端转化为从表。当“一”端实体是可选存在时,“多”端实体表中的外键列允许为NULL。
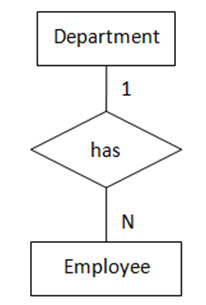
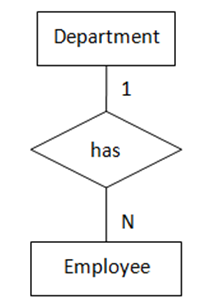 (图4 “一对多”,两实体都为强制存在)
(图4 “一对多”,两实体都为强制存在)图4表示的语义为:每名员工都属于一个部门,每个部门至少有一名员工。转化得到的SQL表定义如下:
create table department
(
dept_no integer,
dept_name char(20),
primary key(dept_no)
);
create table employee
(
emp_id char(10),
emp_name char(20),
dept_no integer not null,
primary key(emp_id),
foreign key(dept_no) references department
on update cascade
);5. “一对多”,一实体可选存在,另一实体强制存在
 (图5 “一对多”,一实体可选存在,另一实体强制存在)
(图5 “一对多”,一实体可选存在,另一实体强制存在)
图5表示的语义为:每个部门至少发布一张报表,一张报表不一定由某个部门来发布。转化得到的SQL表定义如下:
create table department
(
dept_no integer,
dept_name char(20),
primary key(dept_no)
);
create table report
(
report_no integer,
dept_no integer,
primary key(report_no),
foreign key(dept_no) references department
on delete set null on update cascade
);
注:解释一下report表创建脚本的最后一行“on delete set null on update cascade”的用处。当没有这一行时,更新department表中dept_no字段会失败,删除department中记录也会失败,报出与外键约束冲突的提示。如果有了最后一行,更新department表中dept_no字段,report表中对应记录的dept_no也会同步更改,删除department中记录,会使report表中对应记录的dept_no值变为NULL。6. “多对多”,两实体都为可选存在
在“多对多”关系中,需要一张新关系表包含两个实体的主键。无论两边实体是否为可选存在的,其转化形式一致,关系表中的外键列不能为NULL。实体可选存在,在关系表中表现为是否存在对应记录,而与外键是否允许NULL值无关。
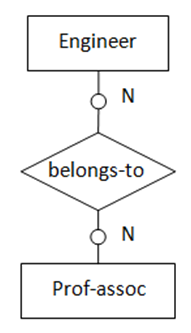
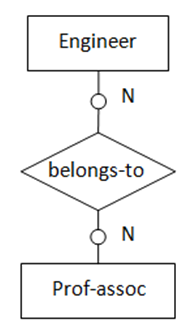 (图6 “多对多”,两实体都为可选存在)
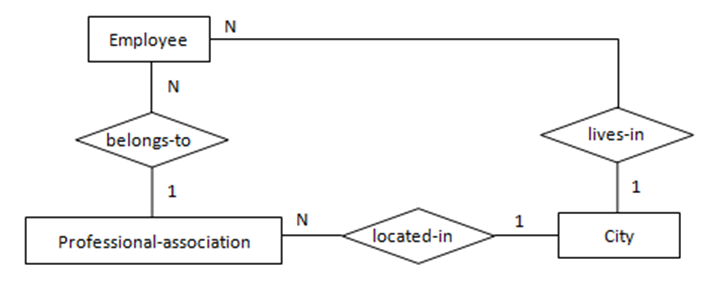
(图6 “多对多”,两实体都为可选存在)图6表示的语义为:一名工程师可能是专业协会的会员且可参加多个专业协会。每一个专业协会可能有多位工程师参加。转化得到的SQL表定义如下:
create table engineer
(
emp_id char(10),
primary key(emp_id)
);
create table prof_assoc
(
assoc_name varchar(256),
primary key(assoc_name)
);
create table belongs_to
(
emp_id char(10),
assoc_name varchar(256),
primary key(emp_id, assoc_name),
foreign key(emp_id) references engineer
on delete cascade on update cascade,
foreign key(assoc_name) references prof_assoc
on delete cascade on update cascade
);二元回归关系的转化
对于“一对一”或“一对多”回归关系的转化都是在SQL表中增加一列与主键列类型、长度相同的外键列指向实体本身。外键列的命名需与主键列不同,表明其用意。外键列的约束根据语义进行确定。
7. “一对一”,两实体都为可选存在
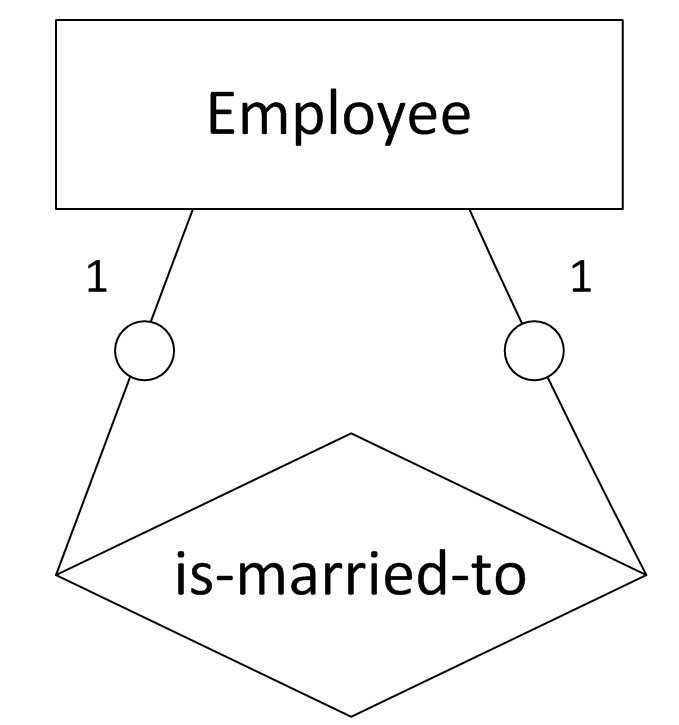
图7表示的语义为:公司员工之间可能存在夫妻关系。转化得到的SQL表定义如下:
create table employee
(
emp_id char(10),
emp_name char(20),
spouse_id char(10),
primary key(emp_id),
foreign key(spouse_id) references employee
);8. “一对多”,“一”端为强制存在,“多”端为可选存在
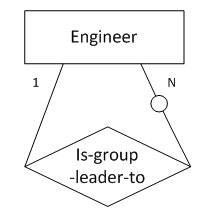
(图8 “一对多”,“一”端为强制存在,“多”端为可选存在)
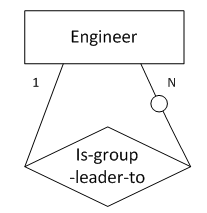
图8表示的语义为:工程师被分为多个组,每个组有一名组长。
转化得到的SQL表定义如下:
create table engineer
(
emp_id char(10),
leader_id char(10) not null,
primary key(emp_id),
foreign key(leader_id) references engineer
);
“多对多”回归关系无论是可选存在的还是强制存在的都需新增一张关系表,表中的外键列须为NOT NULL。
9. “多对多”,两端都为可选存在


图9表示的语义为:社交网站中人之间的朋友关系,每个人都可能有很多朋友。转化得到的SQL表定义如下:
create table person
(
person_id char(10),
person_name char(20),
primary key(person_id)
);
create table friend
(
person_id char(10),
friend_id char(10),
primary key(person_id, friend_id),
foreign key(person_id) references person,
foreign key(friend_id) references person,
check(person_id < friend_id) );
}三元和n元关系的转化 无论哪种形式的三元关系在转化时都会创建一张关系表包含所有实体的主键。三元关系中,“一”端实体的个数决定了函数依赖的数量。因此,“一对一对一”关系有三个函数依赖式,“一对一对多”关系有两个函数依赖式,“一对多对多”关系有一个函数依赖式。“多对多对多”关系的主键为所有外键的联合。 10. “一对一对一”三元关系

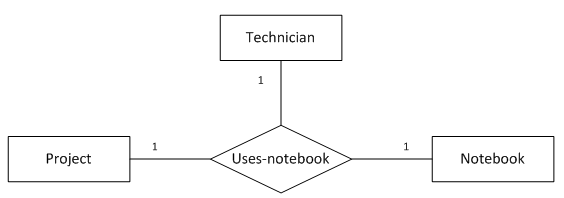
图10表示的语义为:
1名技术员在1个项目中使用特定的1本记事簿
1本记事簿在1个项目中只属于1名技术员
1名技术员的1本记事簿只用于记录1个项目
注:1名技术员仍可以做多个项目,对于不同的项目维护不同的记事簿。
转化得到的SQL表定义如下:
create table technician (
emp_id char(10),
primary key(emp_id)
);
create table project (
project_name char(20),
primary key(project_name)
);
create table notebook (
notebook_no integer,
primary key(notebook_no)
);
create table uses_notebook (
emp_id char(10),
project_name char(20),
notebook_no integer not null,
primary key(emp_id, project_name),
foreign key(emp_id) references technician on delete cascade on update cascade,
foreign key(project_name) references project on delete cascade on update cascade,
foreign key(notebook_no) references notebook on delete cascade on update cascade,
unique(emp_id, notebook_no), unique(project_name, notebook_no)
);函数依赖
emp_id, project_name -> notebook_no
emp_id, notebook_no -> project_name
project_name, notebook_no -> emp_id
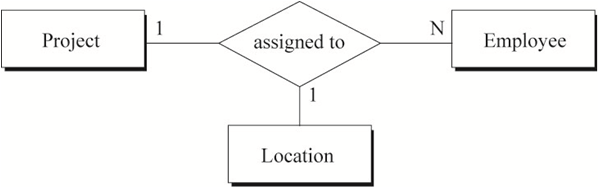
11. “一对一对多”三元关系
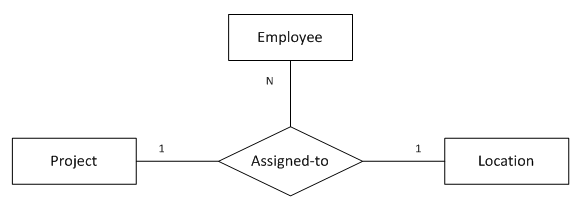
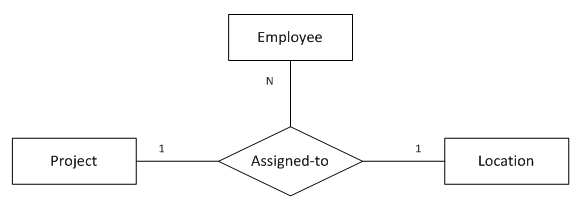
图11表示的语义为:
参与1个项目的1名员工只会在1个地点做该项目
1名员工在1个地点只能做1个项目
1个地点的1个项目可能有多名员工参与
注:1名员工可以在不同的地点做不同的项目
转化得到的SQL表定义如下:
create table employee
(
emp_id char(10),
emp_name char(20),
primary key(emp_id)
);
create table project
(
project_name char(20),
primary key(project_name)
);
create table location
(
loc_name char(15),
primary key(loc_name)
);
create table assigned_to
(
emp_id char(10),
project_name char(20),
loc_name char(15) not null,
primary key(emp_id, project_name),
foreign key(emp_id) references employee
on delete cascade on update cascade,
foreign key(project_name) references project
on delete cascade on update cascade,
foreign key(loc_name) references location
on delete cascade on update cascade,
unique(emp_id, loc_name)
);函数依赖:
emp_id, loc_name -> project_nameemp_id, project_name -> loc_name
12. “一对多对多”三元关系
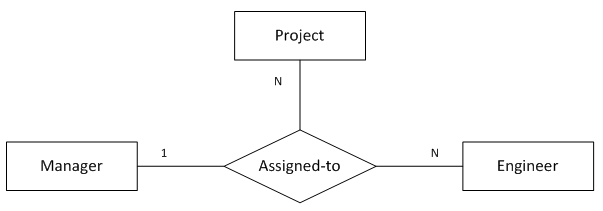
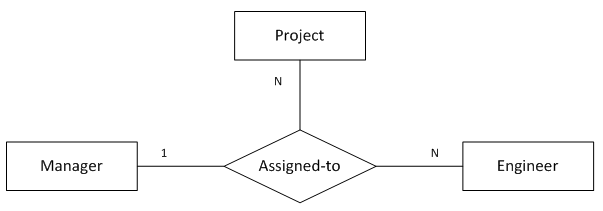
图12表示的语义为:
1个项目中的1名工程师只会有1名经理
1个项目中的1名经理会带领多名工程师做该项目
1名经理和他手下的1名工程师可能参与多个项目
转化得到的SQL表定义如下:
create table project
(
project_name char(20),
primary key(project_name)
);
create table manager
(
mgr_id char(10),
primary key(mgr_id)
);
create table engineer
(
emp_id char(10),
primary key(emp_id)
);
create table manages
(
project_name char(20),
mgr_id char(10) not null,
emp_id char(10),
primary key(project_name, emp_id),
foreign key(project_name) references project
on delete cascade on update cascade,
foreign key(mgr_id) references manager
on delete cascade on update cascade,
foreign key(emp_id) references engineer
on delete cascade on update cascade
);函数依赖:
project_name, emp_id -> mgr_id
13. “多对多对多”三元关系
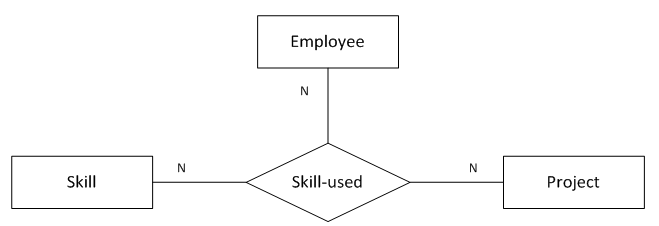
图13表示的语义为:
1名员工在1个项目中可以运用多种技能
1名员工的1项技能可以在多个项目中运用
1个项目中的1项技能可以被参与该项目的多名员工运用
转化得到的SQL表定义如下:
create table employee
(
emp_id char(10),
emp_name char(20),
primary key(emp_id)
);
create table skill
(
skill_type char(15),
primary key(skill_type)
);
create table project
(
project_name char(20),
primary key(project_name)
);
create table sill_used
(
emp_id char(10),
skill_type char(15),
project_name char(20),
primary key(emp_id, skill_type, project_name),
foreign key(emp_id) references employee
on delete cascade on update cascade,
foreign key(skill_type) references skill
on delete cascade on update cascade,
foreign key(project_name) references project
on delete cascade on update cascade
);函数依赖:
无
泛化与聚合
泛化抽象结构中的超类实体和各子类实体分别转化为对应的SQL表。超类实体转化得到的表包含超类实体的键和所有公共属性。子类实体转化得到的表包含超类实体的键和子类实体特有的属性。
要保证泛化层次中数据的完整性就必须保证某些操作在超类表和子类表的之间的同步。若超类表的主键需做更新,则子类表中对应记录的外键必须一起更新。若需删除超类表中的记录,子类表中对应记录也需一起删除。我们可以在定义子类表时加入外键级联约束。这一规则对于覆盖与非覆盖的子类泛化都适用。
14. 泛化层次关系
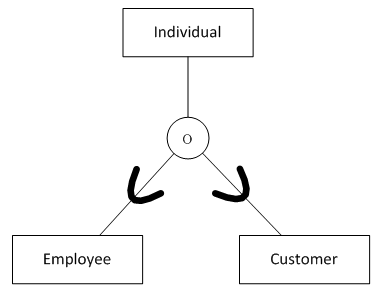
图14表示的语义为:
个人可能是一名员工,或是一位顾客,或同时是员工与顾客,或两者都不是
转化得到的SQL表定义如下:
create table individual
(
indiv_id char(10),
indiv_name char(20),
indiv_addr char(20),
primary key(indiv_id)
);
create table employee
(
emp_id char(10),
job_title char(15),
primary key(emp_id),
foreign key(emp_id) references individual
on delete cascade on update cascade
);
create table customer
(
cust_no char(10),
cust_credit char(12),
primary key(cust_no),
foreign key(cust_no) references individual
on delete cascade on update cascade
);有些数据库开发者还会在超类表中增加一个鉴别属性。鉴别属性对于每一种子类有不同的值,表示从哪一个子类中能获得进一步的信息。
聚合抽象的转化方式也是为超类实体和每一个子类实体生成SQL表,但聚合中的超类与子类没有公共属性和完整性约束。聚合的主要功能是提供一种抽象来辅助视图集成的过程。

转化步骤
以下总结了从ER图到SQL表的基本转化步骤
1. 把每一个实体转化为一张表,其中包含键和非键属性。
2. 把每一个“多对多”二元或二元回归关系转化为一张表,其中包含实体的键和关系的属性。
3. 把三元及更高元(n元)关系转化为一张表。
让我们一一对这三个步骤进行讨论。
实体转化
若两个实体之间是“一对多”关系,把“一”端实体的主键加入到“多”端实体表中作为外键。若两实体间是“一对一”关系,把某个“一”端实体的主键放入另一实体表中作为外键,加入外键的实体理论上可以任选,但一般会遵循如下原则:按照实体间最为自然的父子关系,把父实体的键放入子实体中;另一种策略是基于效率,把外键加入到具有较少行的表中。
把泛化层次中的每一个实体转化为一张表。每张表都会包含超类实体的键。事实上子类实体的主键同时也是外键。超类表中还包含所有相关实体的公共非键属性,其他表包含每一子类实体特有的非键属性。
转化得到的SQL表可能会包含not null, unique, foreign key等约束。每一张表必须有一个主键(primary key),主键隐含着not null和unique约束。
“多对多”二元关系转化
每一个“多对多”二元关系能转化为一张表,包含两个实体的键和关系的属性。
这一转化得到的SQL表可能包含not null约束。在这里没有使用unique约束的原因是关系表的主键是由各实体的外键复合组成的,unique约束已隐含。
三元关系转化
每一个三元(或n元)关系转化为一张表,包含相关实体的n个主键以及该关系的属性。
这一转化得到的表必须包含not null约束。关系表的主键由各实体的外键复合组成。n元关系表具有n个外键。除主键约束外,其他候选键(candidate key)也应加上unique约束。
ER-to-SQL转化步骤示例
把数据库设计Step by Step (7)——概念数据建模中最后得到的公司人事和项目数据库的全局ER图(图9)转化为SQL表。
1. 直接由实体生成的SQL表有:
Division Department Employee Manager Secretary Engineer
Technician Skill Project Location Prof_assoc Desktop
Workstation
2. 由“多对多”二元关系及“多对多”二元回归关系生成的SQL表有:
belongs_to
3. 由三元关系生成的SQL表有:
skill_used assigned_to

总结与回顾
1. 通过一些简单的规则就能把ER模型中的实体、属性和关系转化为SQL表。
2. 实体在转化为表的过程中,其中的属性一一被映射为表的属性。
3. “一对一”或“一对多”关系中的“子”端实体转化成的SQL表必须包含另一端实体的主键,作为外键。
4. “多对多”关系转化为一张表,包含相关实体的主键,复合组成其自身的主键。同时这些键在SQL中定义为外键分别指向各自的实体。
5. 三元或n元关系被转化为一张表,包含相关实体的主键。这些键在SQL中定义为外键。这些键中的子集定义为主键,其基于该关系的函数依赖。
6. 泛化层次的转化规则要求子类实体从超类实体继承主键。
7. ER图中的可选约束在转化为SQL时,表现为关系的某一端实体允许为null。在ER图中没有明确标识可选约束时,创建表时默认not null约束。
数据库设计 Step by Step (8)——视图集成
阅读原文 转自博客园 知行思新
引言:在前文(数据库设计Step by Step (7)——概念数据建模)最后的案例中,我们通过集成多个局部的实体关系(ER)模型最终得到了全局ER图。在现实项目中视图集成可能并不会那么容易。
俯瞰整个数据库生命周期(如下图所示)。在前面的内容中,我们已完成了“确定需求”和“数据模型”(图中以灰色标出),本小节我们将详细讨论“视图集成”(图中以红色标出)
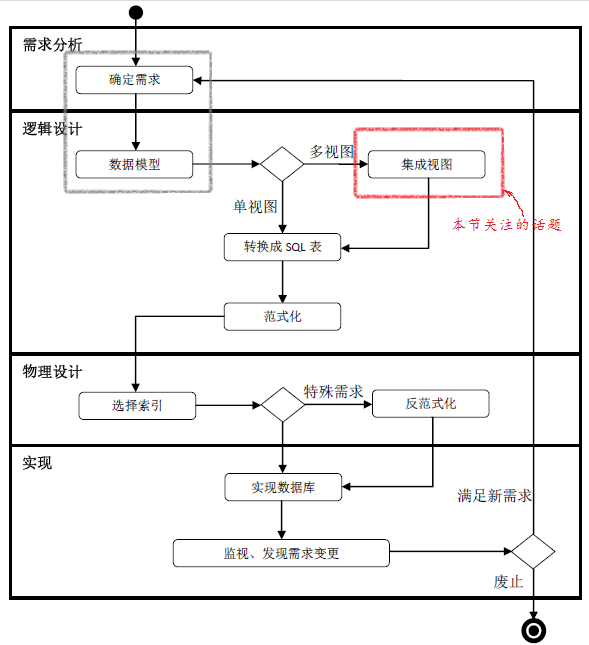
把基于不同用户视角的局部ER图集成为一个统一的、没有冗余的全局ER图在数据库设计流程中非常重要。单个局部ER图是通过分析用户需求进行概念数据建模得到的;全局ER图是通过对各个局部ER图进行分析,解决其中存在的视角和术语差异,最终进行组合得到的。

为什么会产生不一致的局部ER图
当不同的用户或用户组从各自的视角来看业务时就会产生各异的ER图。举例来说市场部趋向于把整个产品作为销售的基本单元,但工程部可能更关注组成产品的单个零件。另一个例子,一个用户可能关注项目的目标和产生的价值,而另一个用户则关心项目需要占用的资源和所涉及的人员。上述的这些差异造成了各个ER图之间不一致的关系和术语。ER图的不一致性会表现为:不同的泛化程度;不同的关系连通数(一对多、多对多等);不同用户视角定义的实体、属性或关系(相同的概念,不同的人使用了不同的名称与建模形式)。
举例来说,同一个现实场景(客户下订单,订购产品),从三个不同视角建模得到的ER图如下。

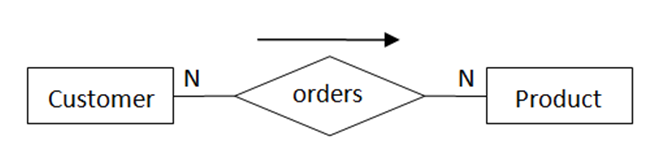
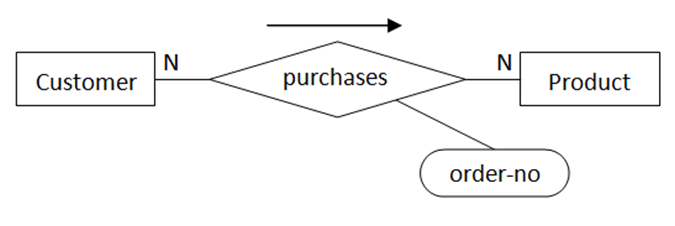
图1中,Customer、Order、Product描述为实体,把“places”和“for-a”描述为关系。
图2中,“orders”定义为Customer和Product之间的关系。
图3中,“orders”关系被另一个关系“purchases”代替。“order-no”被作为关系“purchases”的一个属性。
同是订单(order),从不同视角出发在ER图中被表示为实体、关系、属性。
视图集成的步骤
局部ER图(概念数据模型)的集成一般有如下四个步骤。
- 集成策略选择
- 比较实体关系图
- 统一实体关系元素
- 合并、重构实体关系图
我们一一对这四个步骤进行讨论。
集成策略选择
通常的集成策略有:
1.每次集成2个局部ER图。
2.每次集成n个局部ER图(n大于2且小于等于总ER图数)。
相对来说第一种集成策略每次所涉及的实体、关系数量较少,也更容易掌控。
比较实体关系图
设计者需要仔细观察不同ER图中的对应实体,发现其中因视角不同而存在的冲突。
命名上的冲突包括“同物异名”和“异物同名”。“同物异名”是指同一个概念使用了不同的名称,可以通过检视数据字典(命名及其描述对应表)来发现。“异物同名”是指对不同的概念使用了相同的名称,需要通过检视不同ER图中相同的名称来发现。
结构性冲突的表现形式更多。类型冲突包括使用不同的构造方式建模同一概念。以图1、2、3为例,order这一概念可以建模为一个实体,一个关系或一个属性。依赖冲突是指类似或相同的关系在不同的局部ER图中被建模成不同的连通数。解决这种冲突的一种方法是使用最一般的连通数约束,如多对多。若这样做会造成语义上的错误,则说明两种关系概念不同不能合并,应进行改名并让每个关系保持各自的连通数。键冲突是指在不同的局部ER图中,同一概念的实体被分配了不同的键。举例来说,当一名员工的全名、员工号、员工身份证号在不同的局部ER图中被作为员工的键时,就出现了键冲突。
统一实体关系元素
基本目标是解决各局部ER图中的冲突,使这些元素一致化,为最终的ER图集成做准备。要解决各局部ER图之间的冲突通常需要设计开发人员与用户进行积极的沟通,了解、分析、理解冲突元素的真实语义。
我们可能需要对某些ER图中的实体及键属性进行改名。各局部ER图中被建模为实体、关系或属性的同一概念需要统一转化为三种形式之一。
集成具有相同的度、角色和连通数属性的关系相对较为容易,但集成上述特征不同的关系就较为困难。若同一关系在不同局部ER图中表现形式不一致,则必须进行统一。如:某一关系在一局部ER图中为泛化层次关系,在另一局部ER图中为排他性或(exclusive OR)关系,这种情况必须统一。
合并、重构实体关系图
合成和重构局部ER图,最终得到完整、最简约和可理解的全局ER图。
完整是要求在全局ER图中所有组件的语义完整。
最简约是要求去除全局ER图中的冗余。冗余的概念包括:重叠的实体、多余的语义关系等。例如“社会车辆”和“私家车”可能是重叠的两个实体;教授与学生之间的“指导”和“建议”关系可能代表了同一种活动,需要进一步确定是否存在冗余。
可理解要求全局ER图能被整个项目组成员和最终用户理解。
在进行ER图集成过程中,我们可以首先将相同概念的组件进行集成,之后对获得的初步全局ER图进行重构以使其满足上述三方面的要求。举例来说,集成后的ER图包含超类实体与子类实体的层次组合,若超类实体中的属性已涵盖子类实体中的某些属性,则子类实体的这些属性可以去除。

了解目标
让我们看一下两张具有重叠数据的局部ER图。这两张ER图是对两组不同用户访谈后画出的。
图4是一张以报表为关注点的ER图,其中包含发布报表的部门、报表中的主题和报表提交的对象。

图5的ER图以发布作为关注中心,把发布内容中的关键词建模为另一个实体。

我们的目标是整合这两张ER图,并保证合成后的ER图语义完整、形式最简约且易理解。
集成步骤
首先,在两张局部ER图中寻找是否存在“同物异名”与“异物同名”现象。图4中的实体Topic-area与图5中的实体Keyword为“同物异名”,虽然两个实体的属性不完全相同,但两者属性是兼容的,可以进行统一化。对图5进行修改,可得到图6。

其次,再来看两张ER图之间的结构性冲突。图4中的实体Department与图5中的属性dept-name为类型冲突。解决该冲突的方法是保留强类型(实体Department),把属性dept-name移至实体Department中。解决该冲突,把ER图6转化为ER图7。
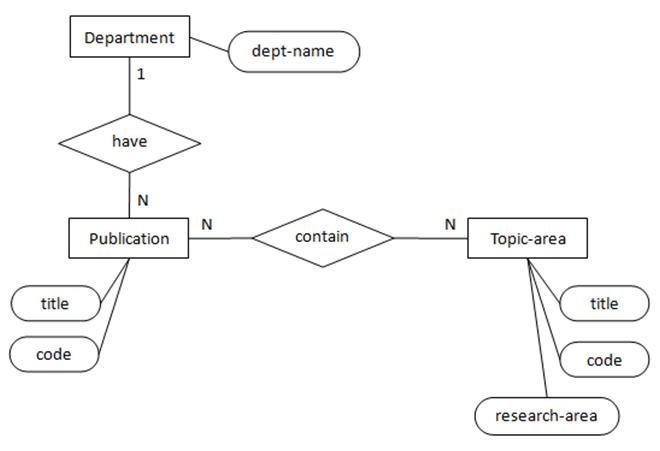
比较变化后的各局部ER图,寻找之间的“共同之处”进行合并。 在真正合并之前必须确认这些“共同之处”的语义概念完全等同,这也保证了合并后语义的完整性。在ER图4与ER图7中有两个共同实体:Department和Topic-area,且语义一致。初步合并后的全局ER图如图8所示。
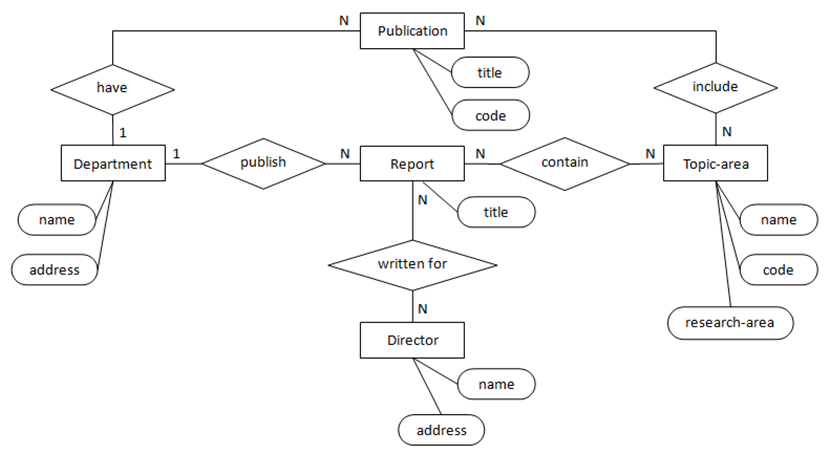
{kind=link}
图8中实体Publication和Report与实体Department和Topic-area之间的关系存在冗余。通过与用户的再次确认,了解到Publication是Report的泛化(报表只是发布材料中的一种),故不能简单的去除实体Publication及关系have和include来消除冗余,而可以引入泛化关系并去除冗余关系publish和contain。
图9展示了增加泛化关系后的ER图(Publication为超类型,Report为子类型)
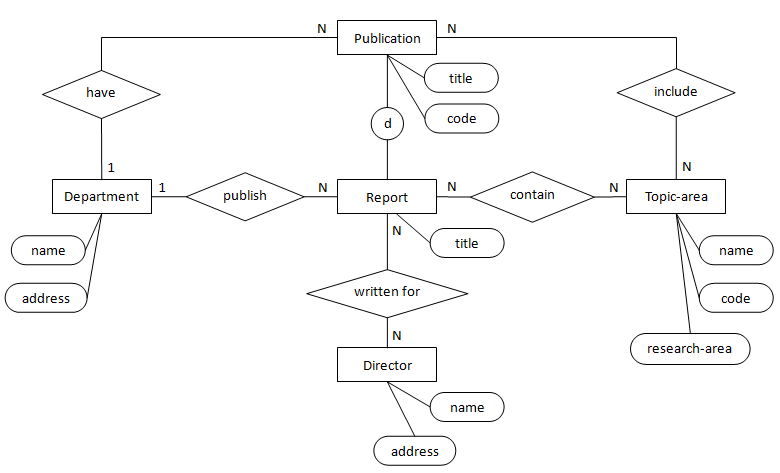
图10中实体Report与实体Department和Topic-area之间的冗余关系publish和contain被去除了。Report中的属性title也被去除了,因为该属性已经出现在其超类型实体Publication中了。

最终得到的ER图10达到了语义完整、最简约、易理解的目标。ER图集成是一个持续优化和评估的过程。需要注意的是“最简约”未必会最高效。如ER图10中去除的“publish”和“contain”关系,保留它们可能对性能有帮助。在后期的分析或测试过程中可根据需要重构ER图。

1. 不同的用户或用户组视角将产生不同的局部ER图
2. 局部ER图之间的冲突包括:命名冲突、类型冲突、依赖冲突、键冲突
3. 视图集成的目标是得到语义完整、形式简约且易于理解的全局ER图
4. 视图集成能进一步加强项目组对系统整体需求的理解与把握
数据库设计Step by Step (7)——概念数据建模
阅读原文 转自博客园 知行思新
引言:在前两篇博文(数据库设计 Step by Step (5)和数据库设计 Step by Step (6) —— 提取业务规则)中,我们进行了数据库需求分析,着重讨论了两个主题:1.理解用户需求;2.提取业务规则。当需求分析完成后,我们就要进入到概念数据建模环节。本篇文章将使用之前介绍过的“基本实体关系模型构件”和“高级实体关系模型构件”作为建模的基本元素,大家可以回顾数据库设计 Step by Step (3)和数据库设计 Step by Step (4)中的模型构件及语义。
逻辑数据库设计有多种实现方式,包括:自顶至底,自底至顶以及混合方式。传统数据库设计是一个自底至顶的过程,从分析需求中的单个数据元素开始,把相关多个数据元素组合在一起转化为数据库中的表。这种方式较难应对复杂的大型数据库设计,这就需要结合自顶至底的设计方式。
使用ER模型进行概念数据建模方便了项目团队内部及与最终用户之间的交流与沟通。ER建模的高效性还体现在它是一种自顶至底的设计方法。一个数据库中的实体数量比数据元素少很多,因为大部分数据元素表示的是属性。辨别实体并关注实体之间的关系能大大减少需要分析的对象数量。
概念数据建模连接了两端,一端是需求分析,其能辅助捕获需求中的实体及之间的关系,便于人们的交流。另一端是关系型数据库,模型可以很容易的转化为范式化或接近范式化的SQL表。

概念数据建模步骤
让我们进一步仔细观察应在需求分析和概念设计阶段定义的基本数据元素和关系。一般需求分析与概念设计是同步完成的。
使用ER模型进行概念设计的步骤包括:
- 辨识实体与属性
- 识别泛化层次结构
- 定义关系
下面我们对这三个步骤一一进行讨论。
辨识实体与属性
实体和属性的概念及ER构图都很简单,但要在需求中区分实体和属性不是一件易事。例如:需求描述中有句话,“项目地址位于某个城市”。这句话中的城市是一个实体还是一个属性呢?又如:每一名员工有一份简历。这里的简历是一个实体还是一个属性呢?
辨别实体与属性可参考如下准则:
- 实体应包含描述性信息
- 多值属性应作为实体来处理
- 属性应附着在其直接描述的实体上
这些准则能引导开发人员得到符合范式的关系数据库设计。
如何理解上述的三条准则呢?
实体内容:实体应包含描述信息。如果一个数据元素有描述型信息,该数据元素应被识别为实体。如果一个数据元素只有一个标识名,则其应被识别为属性。以前面的“城市”为例,如果对于“城市”有一些如所属国家、人口等描述信息,则“城市”应被识别为一个实体。如果需求中的“城市”只表示一个城市名,则把“城市”作为属性附属与其他实体,如附属Project实体。这一准则的例外是当值的标识是可枚举的有限集时,应作为实体来处理。例如把系统中有效的国家集合定义为实体。在现实世界中作为实体看待的数据元素有:Employee,Task,Project,Department,Customer等。
多值属性:把多值属性作为实体。如果一个实例的某个描述符包含多个对应值,则即使该描述符没有自己的描述信息也应作为实体进行建模。例如:一个人会有许多爱好,如:看电影、打游戏、大篮球等。爱好对于一个人来说就是多值属性,则爱好应作为实体来看待。
属性依附:把属性附加在其最直接描述的实体上。例如:“office-building-name”作为“Department”属性比作为“Employee”的属性合适。识别实体与属性,并把属性附加到实体中是一个循环迭代的过程。
识别泛化层次
如果实体之间有泛化层次关系,则把标识符和公共的描述符(属性)放在超类实体中,把相同的标识符和特有的描述符放在子类实体中。举例来说,在ER模型中有5个实体,分别是Employee、Manager、Engineer、Technician、Secretary。其中Employee可以作为Manager、Engineer、Technician、Secretary的超类实体。我们可以把标识符empno,公共描述符empname、address、date-of-birth放在超类实体中。子类实体Manager中放empno,特有描述符jobtitle。Engineer实体中放empno,特有描述符jobtitle,highest-degree等。
定义关系
在识别实体和属性之后我们可以处理代表实体之间联系的数据元素即关系。关系在需求描述中一般是一些动词如:works-in、works-for、purchases、drives,这些动词联系了不同的实体。
对于任何关系,需要明确以下几个方面。
- 关系的度(二元、三元等);
- 关系的连通数(一对一、一对多等);
- 关系是强制的还是可选的;
- 关系本身有些什么属性。
注:关系的这些概念可参看数据库设计 Step by Step (3),这里不再赘述。
冗余关系
仔细分析冗余的关系。描述同一概念的两个或多个关系被认为是冗余的。当把ER模型转化为关系数据库中的表时,冗余的关系可能造成非范式化的表。需要注意的是两个实体间允许两个或更多关系的存在,只要这些关系具有不同的含义。在这种情况下这些关系不是冗余的。
举例来说,如下图1中Employee生活的City与该Employee所属的Professional-association的所在City可以不同(两种含义),故关系lives-in非冗余。
三元关系
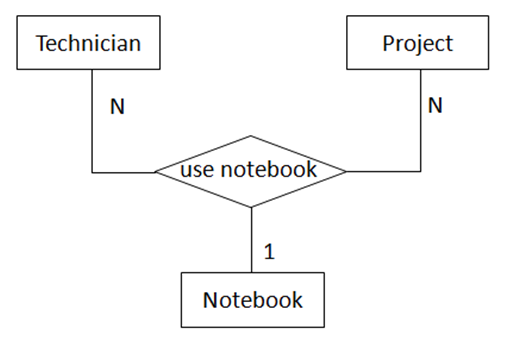
非常小心的定义三元关系,只有当使用多个二元关系也无法充分描述多个实体间的语义时,我们才会定义三元关系。以Technician、Project、Notebook为例。
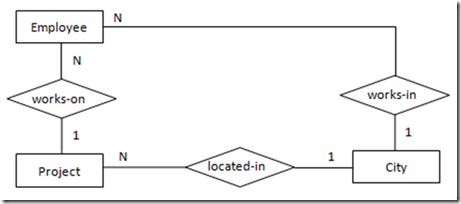
例1:如果 一个Technician只做一个Project,一个Project只有一个Technician,每个Project会被独立记录在一本Notebook中。
例2:如果一个Technician能同时做多个Project,一个Project可以有多个Technician同时参与,每个Project有一本Notebook(多个做同一个Project的Technician共用一本Notebook)

例3:如果一个Technician能同时做多个Project,一个Project可以有多个Technician同时参与,一个Technician在一个Project中使用独立的一本Notebook。
注:三元关系的语义分析可参看数据库设计 Step by Step (4),这里不再赘述。

我们假设要为一家工程项目公司设计一个数据库来跟踪所有的全职员工,包括员工被分配的项目,所拥有的技能,所在的部门和事业部,所属于的专业协会,被分配的电脑。
单个视图的ER建模
通过需求收集与分析过程,我们获得了数据库的3个视图。
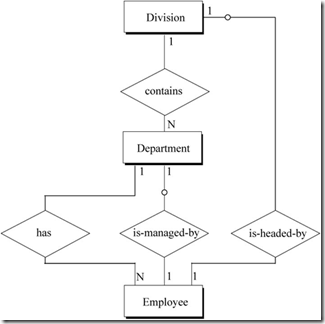
第一个视图是人力资源管理视图。每一个员工属于一个部门。事业部是公司的基本单元,每个事业部包含多个部门。每一个部门和事业部都有一个经理,我们需要跟踪每一个经理。这一视图的ER模型如图6所示。
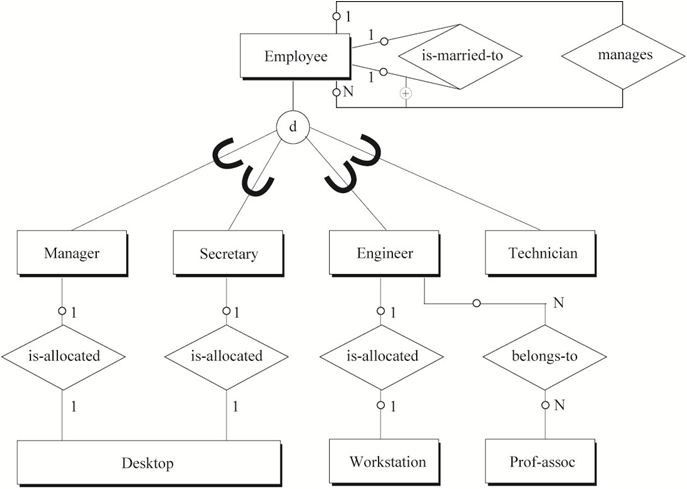
第二个视图定义了每个员工的头衔,如工程师、技术员、秘书、经理等。工程师一般属于某个专业协会,并可能被分配一台工作站。秘书和经理会被分配台式电脑。公司会储备一些台式电脑和工作站,以分配给新员工或当员工的电脑送修时进行出借。员工之间可能有夫妻关系,这也需要在系统中进行跟踪,以防止夫妻员工之间有直接领导关系。这一视图的ER模型如图7所示。
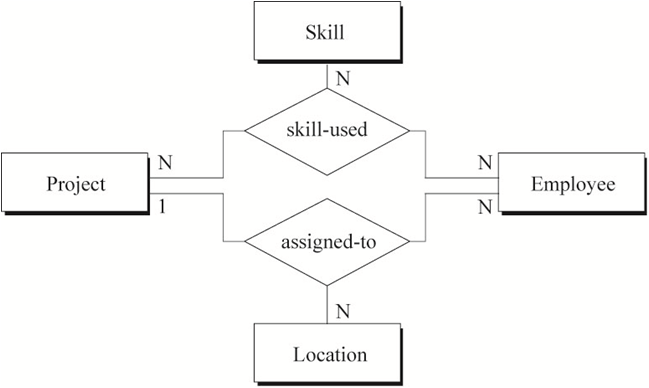
第三个视图如图8所示,包含员工(工程师、技术员)分配项目的信息。员工可以同时参与多个项目,每一个项目可以在不同的地方(城市)设有总部。但一个员工在指定的地点只能做当地的一个项目。员工在不同的项目中可以选用不同的技能。
全局ER图
对三个视图的简单集成可得到全局ER图,如图9所示,它是构造范式化表的基础。全局ER图中的每一个关系都是基于企业中实际数据的一个可验证断言。对这些断言进行分析导出了从ER图到关系数据库表的转化。
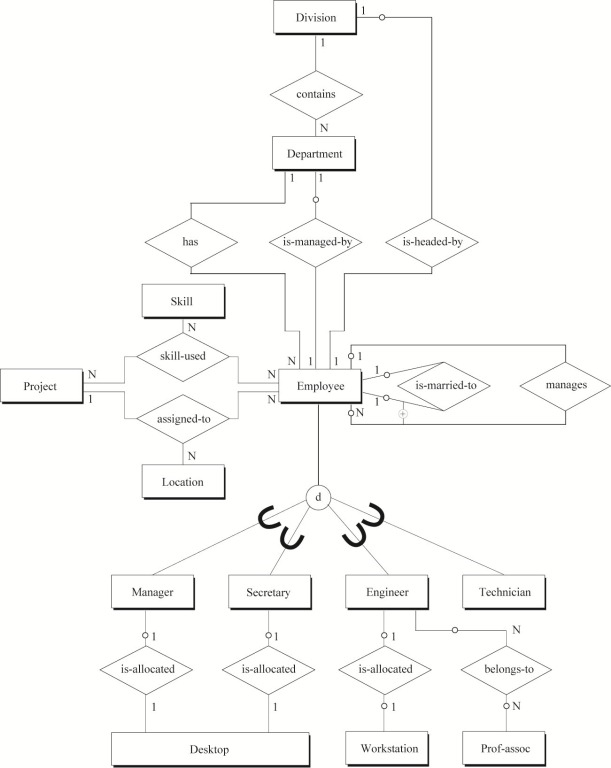
从全局ER图中可以看到二元、三元和二元回归关系;可选和强制存在性关系;泛化的分解约束。图9中三元关系“skill-used”和“assigned-to”是必须的,因为使用二元关系无法描述相同的语义。
可选存在性的使用,Employee与Division或与Department之间是基于常识:大多数Employee不会是Division或Department的经理。另一个可选存在性的例子是desktop或workstation的分配,每一台desktop或workstation未必都会分配给一个人。总而言之,在把ER模型转化为SQL表之前,所有的关系、可选约束、泛化层次都需要与系统的最终用户进行确认。

总结来说,在关系数据库设计中应用ER模型会带来如下好处
1. 使用ER模型可帮助项目成员专注在讨论实体之间的重要关系上,而不受其他细节的干扰。
2. ER模型把大量复杂的语言描述转化为精简的、易理解的图形化描述。
3. 对原始ER模型的扩展,如可选和强制存在性关系,泛化关系等加强了ER模型对现实语义的描述能力。
4. 从ER模型转化为SQL表有完整的规则,且易于使用。
实体关系(ER)模型参考资料
1. 基本实体关系模型构件——实体、关系、属性、关系的度、关系的连通数、关系的属性、关系中实体的存在性(http://www.cnblogs.com/DBFocus/archive/2011/04/24/2026142.html)
2. 高级实体关系模型构件——泛化、聚合、三元关系(http://www.cnblogs.com/DBFocus/archive/2011/05/07/2039674.html)
数据库设计 Step by Step (6) —— 提取业务规则
阅读原文 转自博客园 知行思新
引言:数据库设计 Step by Step (5)中我们通过多种方法来理解客户的需求并撰写了需求文档。本文我们将回答三个问题。1. 为什么业务规则非常重要。2. 怎样识别业务规则。3. 如何修改关系模型并隔离出业务规则。

什么是业务规则
业务规则描述了业务过程中重要的且值得记录的对象、关系和活动。其中包括业务操作中的流程、规范与策略。业务规则保证了业务能满足其目标和义务。
生活中的一些业务规则可能是:
当顾客进入店内,最近的员工须向顾客打招呼说:“欢迎来到×××”。
当客户兑换超过200元的奖券时,柜员须要求查看客户的身份证并复印。当兑换的奖券金额小于25元时,无需客户签字。
早上第一个进办公室的人需要把饮水机加热按钮打开。
本系列我们关注数据库相关的业务规则,一些例子如下:
只有当客户产生第一个订单时才创建该客户的记录。
若一名学生没有选任何一门课程,把他的状态字段设为Inactive。
若销售员在一个月中卖出10套沙发,奖励500元。
一个联系人必须至少有1个电话号码和1个email邮箱。
若一个订单的除税总额超过1000元则能有5%的折扣。
若一个订单的除税总额超过500元则免运费。
员工购买本公司商品能有5%的折扣。
若仓库中某货品的存量低于上月卖出的总量时,则需要进货。
从数据库的视角来看,业务规则是一种约束。简单的约束如:
所有订单必须有一个联系电话。
上述这类简单的规则可以很容易的映射到关系数据库定义中,为字段确定数据类型或设定某字段为必填(不能为NULL)。某些业务规则表达的约束会复杂些,如:
学生每天的上课时间加上项目时间必须在1至14小时之间。
我们可以通过check约束或外键约束来实现这类业务规则。对于一些非常复杂的业务规则,如:
一名教员每周不能少于30小时工作量,其中分为办公时间、实验时间和上课时间。每1小时的课需要0.5小时办公时间进行备课。每1小时实验需1小时办公准备。每周指导学生论文时间不少于2小时。
类似上述的业务规则需要从多个表中收集数据,故在程序代码中实现最为合适。
识别关键业务规则
记录所有的业务规则并对这些规则进行分类能帮助我们更好的在系统中实现业务逻辑。
如何实现业务规则不仅与当前的业务逻辑有关,而且与该业务逻辑将来如何变化有关。当一个规则在将来很可能变化时,我们需要使用更复杂但更灵活的方式构建该规则。
举例来说,假设公司只能向当地设有仓库的城市发货,这些城市包括:南京、长沙、西安、广州。业务规则要求订单中的发货城市字段必须为NJ、CS、XA、GZ之一。
我们可以把该规则简单的实现为check约束。但将来公司若在上海有了一个新仓库,就必须从后台数据库端修改该check约束。若公司随后设立更多新仓库或业务规则变化为可以向没有仓库的城市发货,每次我们都需要修改该约束。
考虑另一种实现该业务规则的方法——使用外键。我们创建一张ShippingCities表,其中存放值:NJ、CS、XA、GZ,并让订单表中的发货城市字段外键引用ShippingCities表中的主键。这样订单的发货城市列只能接受ShippingCities中存在的城市。当支持的发货城市增加或减少时,只需要在ShippingCities中插入或删除记录。
两种方式的实现难度差异不大,但前一种方式每次都需要修改数据库结构,后一种只需要修改数据。修改数据不仅更省力而且技术要求也更低。
上述业务规则实现为check约束可能如下:
ShippingCity = ‘NJ’ or ShippingCity = ‘CS’ or ShippingCity = ‘XA’ or ShippingCity = ‘GZ’
上述代码并不复杂,但只有熟悉数据库的程序员从后台才能修改。ShippingCitis表中的数据相对更易于理解,我们可以提供一个界面来让用户自己维护其中的城市。
要识别关键业务规则,我们可以问自己两个问题。
第一、修改规则会有多困难。越是复杂的规则,修改起来越困难且更容易出错。
第二、规则变化的可能性有多大。变化频繁的规则需要额外的设计来更好的应对将来的变化。
需要特别注意的规则(关键业务规则):
枚举值。例如:有效的发货城市,订单状态(Pending, Approved, Shipped)等。
计算参数。例如:对500元以上的订单免运费。这一数值可能在将来会调整为300元或600元。
有效参数。例如:项目组可由2至5人组成。某些项目是否可能由1个人完成或有更多人参与。
交叉记录和交叉表检查。例如:订单中可订购的货品数量不能超过该货品的当前库存数。
可概括性约束。如果可预见到将来需应用一些类似的约束,我们可以考虑把这些约束抽象出来进行管理。例如:某保险公司最近主推保险产品A。对每月能卖出20份A产品的销售人员给予1000元奖金。对于不同的保险产品在不同的时间段可能有不同的推广奖励规则。我们可以把产品名称、编号、销售量、奖金数额、促销时间段提取出来放到一张独立的表中作为计算奖金的参数。
非常复杂的检查。有些检查规则非常复杂,把这些规则放到程序代码中实现更为容易和清晰。例如:学生选择理学院的谓词演算课程的前提是已通过理学院的命题演算课程或已通过社科院的逻辑I和II课程或者需要导师的允许。该规则在某些数据库产品中可以通过表级的check约束实现,但放到程序中更易于维护和理解。
一些直接可以在数据库中实现的业务规则:
固定枚举值。例如:性别(男、女),用手习惯(左撇子、右撇子)。
数据类型要求。每个字段具有确定的数据类型是关系型数据库的重要特性之一。滥用通用的数据类型(如string)对性能和数据防错都会带来损害。
必填值。例如:会员必须有手机联系方式。
合理性检查。合理性检查设定的范围基本不会变化。例如:商品的价格大于等于0。
作为软件从业人员不要拒绝或回避变化。世界上唯一不变的就是变化。在收集业务规则时多去了解该规则的业务背景与历史变化历程,而不是逼迫客户保证规则不会变化。尽可能发现所有的业务规则并记录下来。对这些业务规则按变化的可能性和修改难度进行分类,精心设计那些将来可能变化且修改困难的规则。
提取关键业务规则
识别并分类业务规则之后,我们需要在数据库中或数据库外来实现关键业务规则。我们可以参考如下方法:
1. 若规则为检验一组有效值时,把该规则转化为外键约束。先前举例中的有效发货城市就是一个很好的例子。创建ShippingCities表,填入允许的发货城市。然后把Orders表的ShippingCity列设为外键,引用ShippingCities表的主键。
2. 若规则为参数可能变化的计算式时,把这些参数提取到一张表中。例如:一个月内卖出总价超过100万元汽车的销售员能获得500元奖金。把参数100万元和500元提取到一张表中,如果需要甚至可以把一个月的时间段也作为参数提取出来。
我还见过一些软件系统在数据库中有一张通用的参数表。该通用参数表中存放系统需要的各种参数,一些是用于计算、一些是作为检验、另一些决定系统的行为。每一条记录有两个字段:Name和Value。例如需要确定一名销售员能获得多少奖金,我们先要查找Name字段为BonusSales的记录,检查该销售员的销售额是否达到了Value字段的金额,若答案是肯定的再查找Name字段为BonusAward的记录来确定奖金数额。这种设计另有一好处,在程序启动时可以把通用参数表读入内存的某集合中,此后使用参数值时就无需再次连接数据库。
3. 若逻辑或计算规则很复杂时,则提取到代码中进行实现。这里说的代码可以是应用程序端代码,还可以是数据库端存储过程。把规则放到代码中实现的意义在于业务规则与数据库表结构分离了,规则的变化不会影响到数据库表结构。通过结构化编程或面向对象编程来实现复杂的规则更易于维护。
举一个综合性的例子:
一本关于数据库设计的书籍卖出前5000本的版税为5%,5000本至10000本之间的版税为7%,超过10000本后的版税为10%,不同类型书籍的版税可能不同。
上述规则比较复杂且包含多个可能变化的参数,故使用第1、2条方法。我们可以通过存储过程来实现该规则,并把参数隔离到一张参数表中进行维护。创建的参数表为RoyaltyRates,并通过BookId与Books关联(如图1所示)。这样为不同书籍创建新的版税规则就非常容易了。
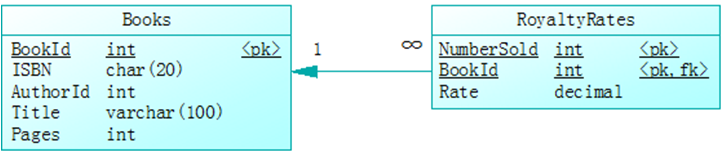
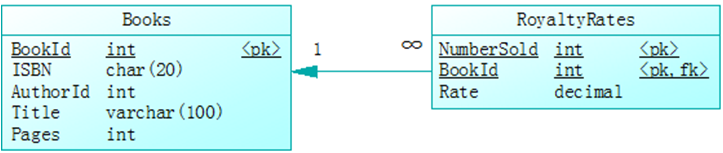 图1 参数表RoyaltyRates与Books表的关系
图1 参数表RoyaltyRates与Books表的关系多层应用的概念大家都不会陌生。三层应用是最常见的分层方法。对于复杂的业务逻辑一般会在中间层(即业务层)中实现。对于一些基本的验证,如必填信息、数字有效区间等,需要在最上层用户界面以及最底层数据库端进行双重检验。数据库端的约束是阻隔脏数据进入系统的最后一道防线,而用户界面处的检验可以避免错误数据传输到系统后端才被拒绝,节省了系统资源。
注:关于多层应用的更多资料请参见最后的“总结与参考”部分。
Summary

主要内容回顾
1. 业务规则决定了业务如何运行,其涵盖从简单明了的入门打卡到复杂的奖金计算公式。
2. 对于数据库而言,业务规则将影响到数据模型。业务规则确定了每个字段的域(值的类型和范围),是否是必须的,以及该字段要满足的其他条件。
3. 理解业务规则并识别那些需要特别处理的关键规则至关重要。
4. 有些规则简单且基本不变,它们可以很容易的用数据库特性来实现。其他的一些规则可能复杂或时常变化,我们可以把它们从数据库中逻辑的或物理的隔离出来(隔离到参数表、存储过程或业务层中),使它们易于修改。
多层应用参考
1. 谈谈对于企业级系统架构的理解(http://www.cnblogs.com/liping13599168/archive/2011/05/11/2043127.html)
2. Multitier architecture(http://en.wikipedia.org/wiki/Multitier_architecture)
3. Software Architecture, Architects and Architecting(http://www.bredemeyer.com/)
数据库设计 Step by Step (5)——理解用户需求
阅读原文 转自博客园 知行思新
引言:数据库设计 Step by Step (4)中我们讨论了泛化关系、聚合关系、三元关系等高级实体关系模型构件及其语义。从本次讲座开始我将引领大家开始数据库设计之旅,我们将从需求分析开始,途中将经过概念数据建模、多视图集成、ER模型转化为SQL、范式化等过程,最终得到完整、可用的SQL表。
需求分析在数据库生命周期中至关重要,通常也是涉及人员最多的步骤。数据库设计师在这个阶段必须走访最终用户,与他们进行访谈,从而确定用户想在系统中存储什么数据以及想怎样使用这些数据。我们将需求分析分为两个步骤:1.理解用户需求;2.提取业务规则。这次我们先讨论“理解用户需求”。

设计定制化产品——无论是一个数据库、一幅平面广告或一个玩具,都是一个“翻译”的过程。我们需要把浮现在客户脑海中的模糊想法、愿望挖掘出来,并“翻译”成满足他们需求的现实产品。
这个“翻译”过程的第一步就是理解用户的需求。设计最好的订单处理系统对于需要一个电路设计工具的客户来说毫无意义。对客户需求理解的不完全会造成错误或无用的设计与开发,这浪费了你、你的团队还有客户的时间与金钱。(牢记数据库是整个应用开发的根基)
制定一个计划
我们首先制定了一个计划,其中包含挖掘客户需求的一系列步骤。遵循这些步骤能更好地理解客户需求,但在一些项目中我们不需要遵循所有的步骤。举例来说,如果客户是单个人且需求很明确时,我们就不需要进行“搞清谁是谁”与“头脑风暴”了。当客户的数据需要保密时,我们就不能“尝试客户的工作”了。在另一些项目中,调整这些步骤的顺序会更为合适。例如我们可能在去拜访客户和观察他们工作之前先进行“头脑风暴”。
以下按照最普遍的顺序列出了各个步骤。大家根据不同项目的情况可进行灵活调整,目标只有一个就是更好地理解用户需求。
- 列出问题清单
- 拜访客户
- 搞清谁是谁
- 挖掘客户大脑
- 尝试客户的工作
- 学习现有操作
- 头脑风暴
- 展望未来
- 理解客户的质疑
- 弄清客户的真正需求
- 优先级
- 确认你的理解
- 撰写需求文档
下面我们将一一解释每一个步骤。
列出问题清单
我们需要思考,向客户问些什么问题可以帮助我们了解项目的目标和范畴(scope)。以下几个方面的问题可以作为起始点。
功能:
以下问题主要涉及系统应完成的功能与目标。
- 系统应该做些什么?
- 为什么你想建这个系统?
- 系统看上去应该是怎样的?
- 需要些什么报表?
- 用户需要自己定义新报表吗?
- 系统的操作者会是谁?
数据需求:
这些问题是为了弄清项目的数据需求。了解需要些什么数据能帮助我们定义数据库表。
- 系统界面上需要展现哪些数据?
- 这些数据应该由谁来提供?
- 这些数据是如何关联的?
- 这些工作现在是如何处理的?数据来自哪里?
数据完整性:
这些问题能帮助我们在构建数据库时定义完整性约束。
- 哪些数据是必须填写的?(eg: 一条客户记录必须有电话信息吗?)
- 数据的有效域是什么?(eg: 电话号码是否有格式规定?地址数据应有多长?)
- 系统是否需要根据邮编来检验城市的有效性?
- 系统中是否必须在定义了客户之后才能下订单?
- 系统要求多高的可用性等级?(系统需要7×24的可用性吗?数据的备份频率要多高?)
安全性:
这些问题能帮助我们了解客户对权限控制与审计方面的需求。
- 是否每个用户都需要一个不同的密码?
- 是否需要控制不同的用户所能访问的数据?(eg: 销售代表有权限看到客户的信用卡账号,但订单录入专员却不能)
- 存储在数据库中的数据是否需要加密?
- 谁做了什么操作是否需要记录以便于审计?(eg: 记录销售代表提高客户级别的操作,在需要时可以追溯操作的原因)
- 系统中的客户分成几个级别?每个级别的客户有多少?
- 是否已有文档记录了用户的工作与权责?
环境:
这些问题能帮助我们了解当前项目将代替其他什么系统或流程,以及项目将与其他哪些系统进行交互。
- 当前项目是要代替或升级现有的某系统吗?
•是否有描述现有系统的文档?
•现有系统的哪些功能是需要的?哪些是不需要的?
•现有系统处理些什么数据?这些数据是如何存储的?数据之间是如何关联的?
•是否有关于现有系统数据的文档?
- 当前项目必须与其他哪些系统交互?
•项目与其他系统之间如何交互?
•新项目是否需要向现有系统提供数据?如何提供?
•新项目是否需要接收现有系统的数据?如何接收?
•是否有关于其他系统的文档?
- 客户的整个业务流程是怎样的?(了解在整个业务流程中当前项目的作用)
拜访客户
了解我们要设计和搭建的系统的最好方式是询问客户。拿着我们在上一步中准备的问题清单安排与客户进行会面。这不会像闲聊那么轻松,向客户了解需求是一个冗长且折磨人的过程。
有时我们的穷追猛问会使客户筋疲力竭感到不快。在这些时候我们必须更为耐心,可以分几次多次会议来了解需求,每次针对几个问题或流程。我们的目标是对我们要解决的问题有一个完全且彻底的理解。
即使我们的项目只是去解决整个业务中的一小部分问题,我们也要试图去了解客户的整体业务流程,这可能会给我们带来意想不到的收获。
搞清谁是谁
意识到不同的客户可能对项目有不同的愿景。我们需要分辨出谁是领导,谁是积极支持者,谁是旁观者,谁是唱反调者。
以下列出了一些常见的客户角色:
- 项目发起人——一般是管理层的某位领导,他是项目的最高推动者。他会为项目协调资源,解决项目遇到的一些障碍,但他不会参与到项目每天的事务中。
- 项目执行负责人——他对于客户的需求和整个业务最为了解。他是了解用户需求阶段最重要的人,他必须有足够的时间来帮助我们定义项目目标以及回答我们的问题。当别人对某业务环节迟疑不决时,我们需要向他请教。
- 客户代表——客户代表是回答我们问题的人,他们也可能成为系统的最终用户。他们可能是某一部分业务的专家,我们需要与多个客户代表进行访谈来了解业务全貌。
- 利益相关者——这是项目将影响到的人,其中某些人可能同时也是客户代表。这些人可能对项目也有兴趣,但未必对系统都有发言权。我们在进行系统设计时也需要考虑对这些人的影响(特别是附带损害)。
- 唱反调者——这是我们需要关注的一些人。如果唱反调者只是让其他人理性或现实地来看待项目,而并不是彻底反对这个项目的话,他将是我们非常好的资源,他将帮助我们说服其他对项目抱有不切实幻想的客户。而如果唱反调者对整个项目抱有抵触时,我们就必须非常小心,有时需要项目执行负责人出面来协调这些人。
挖掘客户大脑
一旦搞清楚谁是谁之后,我们就要与项目执行负责人讨论客户需要什么。客户希望的解决方案是怎样的,需要包含什么数据,怎样呈现,以及不同数据之间如何关联。
与尽可能多的利益相关者进行交流,我们需要考虑每个人的意见,但心中要牢记项目执行负责人最为理解客户的需求并具有最终决定权。
根据项目的规模,这一过程短则几个小时,长则需要几周才能完成。
尝试客户的工作
观察客户每日的工作能帮助我们更好的理解业务。如果我们能做一会儿客户的工作来了解其中包括的内容那就最好了。
即使我们不能实际尝试客户的工作,一般我们还是可以坐在他们身边近距离观察。告诉客户我们将稍稍降低他们的工作效率并问一些愚蠢且恼人的问题,之后我们就可以开问了。在这个过程中要进行记录,学习尽可能多的东西。有些时候外行者的一些看法可能转化为客户怎么也不会想到的好主意。
学习现有操作
在尝试客户的工作之后,我们还可以看一下是否有其他途径能了解现有流程。通常公司有描述客户角色和职责的操作手册或文档。
寻找客户现在使用的数据存储方式,可能是关系型数据库系统或是电子表格或是纸质的单据等等。了解这些数据是怎样使用的,之间是如何关联的。一般物理数据库之间是通过包含冗余信息来相互关联的,如:客户ID。
头脑风暴
此刻我们已经对客户的业务和需求较为了解了。为了确认没有什么遗漏,我们需要安排头脑风暴。召集项目执行负责人和尽可能多的客户代表与利益相关者,向他们描述前期了解到的需求情况,之后让他们畅所欲言谈谈其中有什么问题或还缺什么。
在这个过程中我们不急于答应或排除任何客户的要求,我们先把客户说到的东西记录下来,并确定这些方面我们已经考虑到了。在正式开发前,我们会与项目执行负责人一起根据项目的规模与交付期限确定需求的优先级。
展望未来
在头脑风暴过程中思考一下将来的需求。问问客户他们的业务在将来是否会变化或他们希望系统将来能包含什么功能。
我们可以把他们的一些想法放入当前的项目中,即使不能也可以使我们知道将来可能会有些什么扩展,在设计数据库时我们能预先留有余地。
理解客户的质疑
一些热心且懂些技术的用户会跑来建议我们如何设计系统,应该创建怎样结构的数据表。我们可能觉得这些建议毫无意义甚至可笑。但在忽视这些建议之前我们应谨慎思考用户提出这些建议或质疑的深层原因是什么。客户比我们更了解业务,他们的建议或质疑中可能蕴含着我们还未了解到的业务变化点或某些特殊业务情况。
弄清客户的真正需求
有时客户并不了解自己的真正需求。他们能看到问题的表象,但未必清楚其根源。我们需要帮助客户寻找到问题的根源并针对问题的源头提出解决方案。
有时客户认为数据库或新系统能神奇般的提高销售,减少成本。事实上一个设计精良的数据库能减少输入差错,提高操作效率,提供数据报表,帮助客户管理数据等等。我们在与客户沟通的过程中需要告诉他们新系统能做些什么,不能做些什么,让客户建立起正确的预期。
优先级
经过先前的步骤,我们已列出一张长长的期望功能列表。其中的某些功能可能不切实际或超出了当前项目的范畴。为了使项目规模可控,我们要与客户一起定义功能的优先级。
一般我们可以把功能分为三个等级。第一优先级是在本期开发中必须包含的功能,没有完成这些功能意味着项目的失败。第二优先级是可以放到下一期开发的功能,当第一优先级的功能完成后,我们可以把第二优先级的部分功能提到当期开发。第三优先级是那些相对不重要或超出项目范畴的功能,我们可以忽略这些功能。
有些情况下优先级是可能转化的。当第一优先级的某功能非常难实现时,我们可以与客户进行沟通,确认该功能是否如此重要,是否能移到第二优先级中以避免影响项目进度。当第二优先级中的某些功能很容易实现,我们可以把该功能调整到第一优先级列表中。但做这些调整之前必须与客户沟通,得到客户的认可。
验证你的理解
梳理我们对业务和需求的理解,并一一与客户进行确认。当客户说“但是”、“除了”、“有时”等词时,我们要特别当心,确认客户只是强调了我们已经知道的东西,而没有出现新的情况。在这个阶段客户可能会想到他们之前没有考虑到的例外情况。
例外情况是数据库设计的大害。在需求分析阶段把例外情况挖掘出来,我们才能在数据库设计时有所准备。例如,我们向客户确认退货流程说:“到这里收货员会输入RMA号并点击完成按钮是吗?”客户可能会说:“嗯…这是大多数情况,但有时没有RMA号,收货员会填入None。”这就是一个客户之前没有告诉我们的重要例外情况,我们必须立刻记录下来。再有一个例子,假设客户使用的纸质订单有配送地址与账单地址两个栏目。我们向客户确认时说:“订单需要有一个配送地址和一个账单地址。”客户打断说:“有时我们需要两个配送地址,因为订单不同部分可能要送到不同的地方。”,并找出一张订单,第二个配送地址被标注在订单的边沿处。这是一个重大例外,在纸上可以很容易的进行标注,但在数据库的一个表单元中增加一个地址是不可能的。只有知道这一例外,我们才能用设计的方法解决这一需求。
撰写需求文档
需求文档描述了我们要构建的系统,该文档也被称为需求规格说明。需求文档要讲清楚我们将构建怎样的系统,该系统会完成什么工作,包含哪些功能点,并描述客户如何使用该系统来解决他们的问题。需求文档明确了项目将完成的功能,这也避免了系统交付时出现争执的情况。
需求文档中应定义可交付成果,即里程碑。里程碑是可直观展现并能验证的中间成果。客户通过里程碑能衡量项目的进度。在需求文档中还需定义最终交付成果,这也是确定项目是否完成的标准。
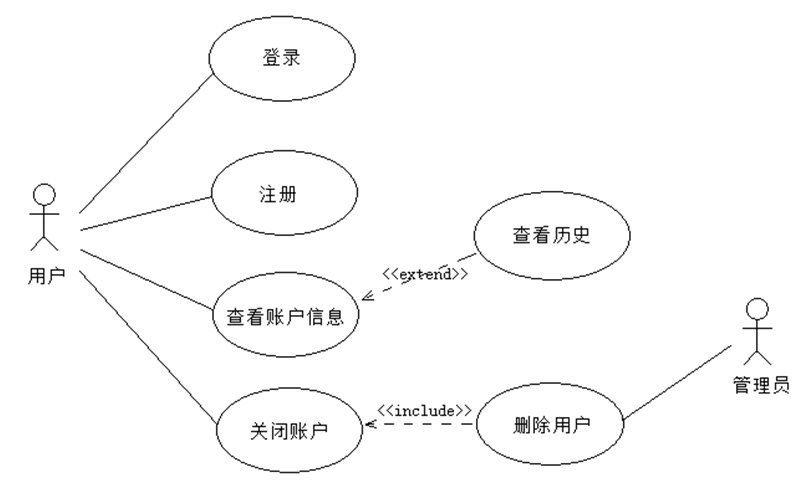
用例图是一种非常好的需求分析工具,可以作为需求文档的一部分。用例图的最主要功能就是用来表达系统的功能性需求或行为。用例图从业务角度上体现谁来使用系统、用户希望系统提供什么样的服务,以及用户需要为系统提供的服务,也便于软件开发人员最终实现这些功能。在官方文档中用例图包含六个元素,分别是:参与者(Actor)、用例(Use Case)、关联关系(Association)、包含关系(Include)、扩展关系(Extend)以及泛化关系(Generalization)。但是有些UML的绘图工具多提供了一种直接关联关系(Directed Association)。
- 参与者:是指用户在系统中扮演的角色
- 用例:是指外部可见的系统功能,对系统提供的服务进行描述
- 关联关系:连接参与者和用例,表示该参与者代表的外部系统实体与该用例描述的系统需求有关
- 包含关系:是来自于用例的抽象,即从数个不同的Use Case中,分离出公共的部分,而成为可以复用的用例
- 扩展关系:表示某一个用例的对话流程中,可能会根据条件临时插入另外一个用例,而前者称为基础用例后者称为扩展用例
- 泛化关系:一个用例可以被特别列举为一个或多个用例,这被称为用例泛化
eg:用户管理的用例图如下所示,图中人形图标表示参与者,椭圆表示用例(图的出处请参见“总结与参考”)

主要内容回顾
1. 搞清哪个客户扮演哪个角色
2. 从客户的脑海中挖掘信息
3. 寻找关于用户角色、职责、现有流程和现有数据的文档
4. 观察客户的工作,学习他们的业务操作
5. 进行头脑风暴,把收集到的功能需求点按优先级分成第一、第二和第三级
6. 确认对客户需求的理解
7. 撰写需求文档,包含可验证的里程碑和用例
用例图参考
1. 初学UML之——-用例图(http://blog.csdn.net/dl88250/archive/2007/10/16/1826713.aspx)
2. UML用例图(http://www.alisdn.com/wordpress/?p=1161)
数据库设计 Step by Step (4)——高级ER模型构件
阅读原文 转自博客园 知行思新
引言:数据库设计 Step by Step (3)中我们讨论了基本实体关系模型构件及其语义。这些概念非常重要,是今天这一讲的基础,在开始本文内容之前建议大家可以再回顾一下上一篇的内容。今天我们将讨论高级实体关系模型构件,与上一篇一起涵盖了ER模型构图的大部分内容。三元关系是今天这一讲的难点,大家可以重点关注。

泛化(Generalization):超类型与子类型
原始的ER模型已经能描述基本的数据和关系,但泛化(Generalization)概念的引入能方便多个概念数据模型的集成。
泛化关系是指抽取多个实体的共同属性作为超类实体。泛化层次关系中的低层次实体——子类型,对超类实体中的属性进行继承与添加,子类型特殊化了超类型。
ER模型中的泛化与面向对象编程中的继承概念相似,但其标记法(构图方式)有些差异。
下图表示员工与经理、工程师、技术员、秘书之间的泛化关系。Employee为超类实体,并包含共同属性,Manager、Engineer、Technician、Secretary都是Employee的子类实体,它们能包含自身特有的属性。
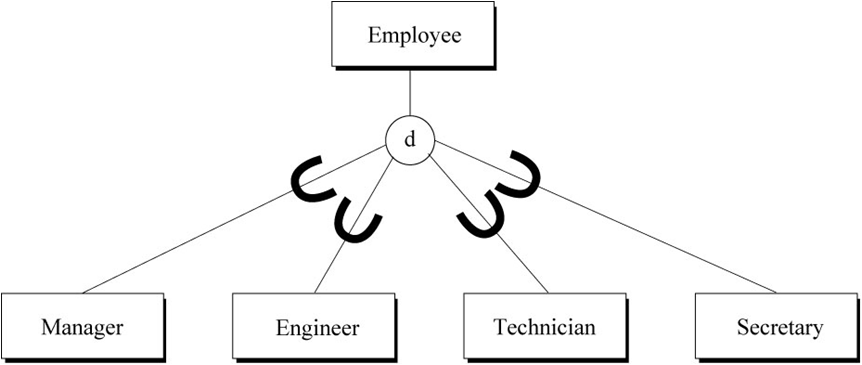
泛化可以表达子类型的两种重要约束,重叠性约束(disjointness)与完备性约束(completeness)。
重叠性约束表示各个子类型之间是否是排他的。若为排他的则用字母“d”标识,否则用“o”标识(o -> overlap)。图1中各子类实体概念上是排他的。
对员工、客户实体进行泛化,抽象出超类实体个人,得到如下关系图。由于部分Employee也可能是Customer,故子类实体Employee与Customer之间概念是重叠的。
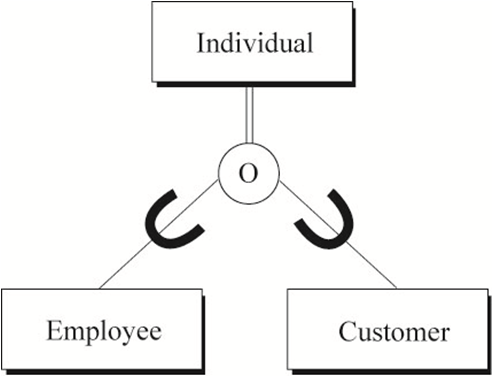
完备性约束表示所有子类型在当前系统中是否能完全覆盖超类型。若能完全覆盖则在超类型与圆圈之间用双线标识(可以把双线理解为等号)。在图2中子类实体Employee与Customer能完全覆盖超类Individual实体。
聚合(Aggregation)
聚合是与泛化抽象不同的另一种超类型与子类型间的抽象。
泛化表示“is-a”语义,聚合表示“part-of”语义。聚合中子类型与超类型间没有继承关系。
聚合关系的标记法是在圆圈中标识字母“A”来表示。
下图表示软件产品由程序与用户手册组成。

三元关系(Ternary Relationships)
当通过二元关系无法准确描述三个实体间的联系时,我们需要使用三元关系。
三元关系中“连通数”的确定方法:
a) 以三元关系中的一个实体作为中心,假设另两个实体都只有一个实例
b) 若中心实体只有一个实例能与另两个实体的一个实例进行关联,则中心实体的连通数为“一”
c) 若中心实体有多于一个实例能与另两个实体实例进行关联,则中心实体的连通数为“多”
注:什么时候需要使用三元关系的实例请参看:数据库设计 Step by Step (3)中的“关系的度(Degree of a Relationship)”小节。关系的“连通数”概念请参看:数据库设计 Step by Step (3)中的“关系的连通数(Connectivity of a Relationship)”小节。
我们来看几个三元关系的实例,注意各个图中关系的度,并理解其中的语义。
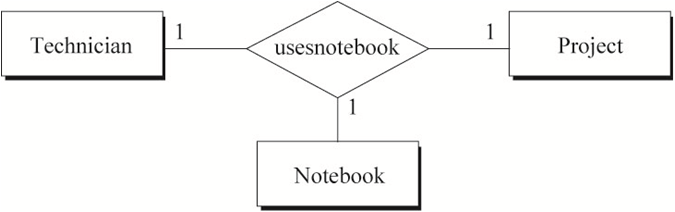
图4中蕴含的语义为:
a) 一名技术员对于每一个项目使用一本手册
b) 每一本手册对于每一个项目属于一名技术员
c) 一名技术员可能在做多个项目,对于不同的项目维护不同的手册
用数学中的函数依赖表示图4的关系:
a) emp-id, project-name -> notebook-no
b) emp-id, notebook-no -> project-name
c) project-name, notebook-no -> emp-id
{kind=link}
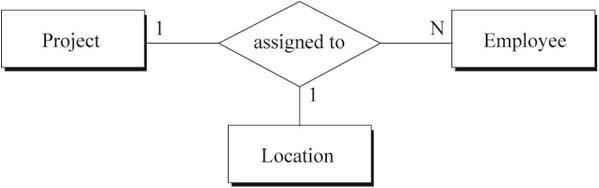
图5中蕴含的语义为:
a) 每一个员工在一个地点只能被分配一个项目,但可以在不同地点做不同的项目
b) 在一个特定的地点,一个员工只能做一个项目
c) 在一个特定的地点,一个项目可以由多个员工来做
用数学中的函数依赖表示图5的关系:
a) emp-id, loc-name -> project-name
b) emp-id, project-name -> loc-name
{kind=link}
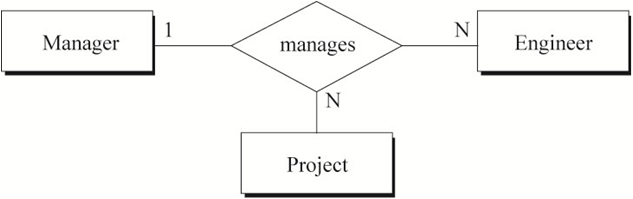
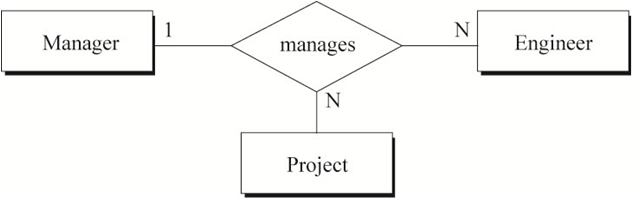
图6中蕴含的语义为:
a) 一名经理手下的一名工程师可能参与多个项目
b) 一名经理管理的一个项目可能会有多名工程师
c) 做某一个项目的一名工程师只会有一名经理
用数学中的函数依赖表示图6的关系:
a) project-name, emp-id -> mgr-id
{kind=link}
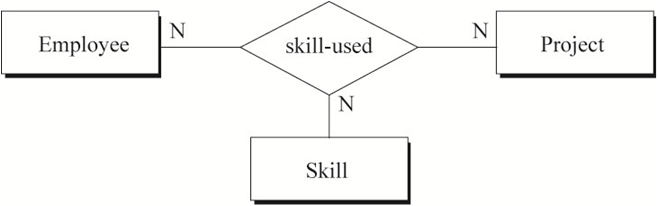
图7中蕴含的语义为:
a) 一名员工在一个项目中可以使用多种技能
b) 一名员工的一种技能可以在多个项目中使用
c) 一种技能在一个项目中可以被多名员工使用
图7各实体之间没有函数依赖
上述4种形式的三元关系,连通数为“一”的实体数量与该三元关系反映的函数依赖语义的数目一致。
三元关系也能有属性。属性值由三个实体的键的组合唯一确定。
n元关系(General n-ary Relationships)
三元关系可以扩展到n元关系,描述n个实体之间的关系。
一般而言,n元关系中每一个连通数为“一”的实体的键都会出现在一个函数依赖表达式的右侧。
对于n元关系,使用语言来表达其中的约束相对较为困难。建议使用数学形式即函数依赖(FD)来表现。
n元关系的函数依赖条目数量与关系图中“一”端实体的数量相同(0~n条)。
n元关系的函数依赖表达式包含n个元素,n-1个元素出现在表达式左侧,1个元素出现在右侧。
排他性约束(Exclusion Constraint)
一般(默认)情况下,多种关系之间是兼容的“或”关系,即允许任意或所有实体参与这些关系。
在某些情况下,多种关系之间是非兼容性“或”关系,即参与关系的实体只能选择其中一种关系,不能同时选择多种关系。
下图表示的语义为:一项工作任务要么被归为外部项目中,要么被归为内部项目中,不可能同时属于外部项目和内部项目。
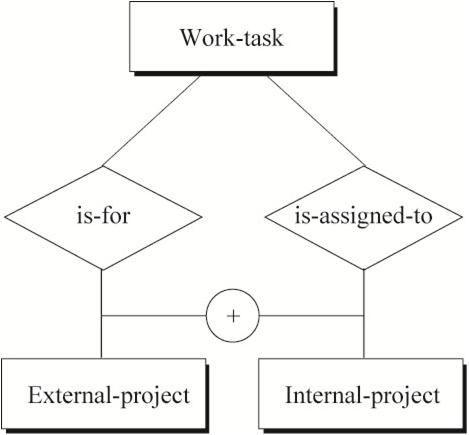
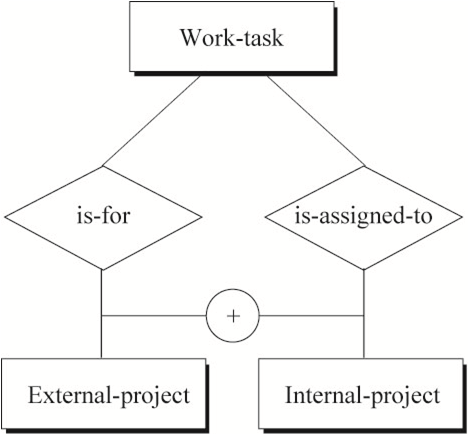{kind=link}

我们对上一篇数据库设计 Step by Step (3)与本篇的重点内容做一个总的回顾
1. 我们讨论了ER模型及构图的基本概念
2. 一个实体可以是一个人,地方,东西或事件
3. 属性是实体的描述信息
4. 属性可以是唯一标识或非唯一的描述
5. 关系描述了实体之间“一对一”,“一对多”,“多对多”的联系
6. 关系的度反映了参与关系的实体数量,如二元关系,三元关系,n元关系
7. 角色(名)定义了一个实体在一个关系中所具有的功能
8. 关系的存在概念表示一个实体在关系中是强制存在还是可选的
9. 泛化允许把实体抽象成超类与子类
10. 三元关系可使用函数依赖来定义