nginx
#屏蔽百度
if ($http_user_agent ~* "Baiduspider")
{
return 403;
}云服务器安全组
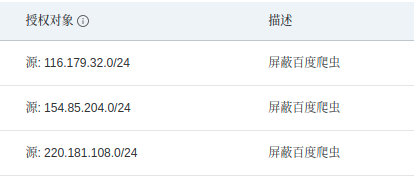
源IP填写为118.124.8.0/24 表示118.124.8.* CIDR无类别域间路由
参考
nginx
#屏蔽百度
if ($http_user_agent ~* "Baiduspider")
{
return 403;
}云服务器安全组
源IP填写为118.124.8.0/24 表示118.124.8.* CIDR无类别域间路由
参考
场景:很多网站,app,等互联网应用,面向国际业务,需要支持多种语言。
方案一
调用第三方翻译API,如,百度翻译,谷歌翻译,有道翻译等等。在渲染页面或这响应接口之前调用api将内容翻译成目标语言,然后在展示。
缺点:依赖第三方服务,延迟高。
方案二
单表冗余字段设计,比如content字段,增加content_en content_fr …
适应于2个语种,字段少的情况。例如,只有content字段需要多语言,而且只有两种语种。
缺点:
方案三
单字段存储json,字段类型设为longText ;
场景:适合短文本少量语种,一旦超出文本限制,就不适用了,例如:长篇富文本多语言支持这类需求。
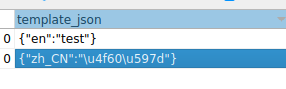
laravel ORM增加语言支持 扩展包 spatie/laravel-translatable 使用json方式存储
需要对多语言字段内容,增加唯一性验证时,使用 codezero-be/laravel-unique-translation
方案四
全表文本都需要翻译的情况,增加语言类型字段
| language | name | content |
| zh-CN | 名称 | 内容 |
| en | name | content |
全表只有几个文本字段的情况,增加语言翻译扩展表
场景:扩展表设计适合,多语种,长文本存储
主表结构存储,不需要翻译文本的字段,附表结构参考上表格,增加关联id
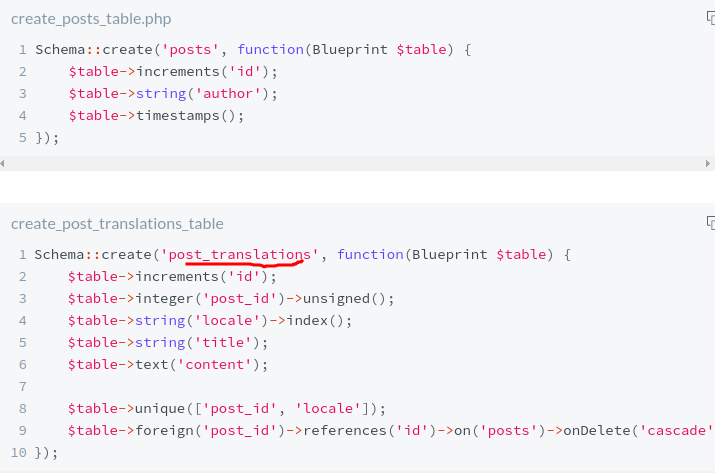
laravel ORM增加语言支持 扩展包 Astrotomic/laravel-translatable 使用该方式实现 文档地址
参考
极客时间教程 php正则文档 转义序列(反斜线)符号表例如\n等
/foo bar/mode分隔符可以是任意非字母数字、非反斜线、非空白字符。 静默忽略合法分隔符之前的空白字符。一般用/分割
方括号外的元字符
| 元字符 | 描述 |
|---|---|
| \ | 一般用于转义字符 |
| ^ | 断言目标的开始位置(或在多行模式下是行首) |
| $ | 断言目标的结束位置(或在多行模式下是行尾) |
| . | 匹配除换行符外的任何字符(默认) |
| [ | 开始字符类定义 |
| ] | 结束字符类定义 |
| | | 开始一个可选分支 |
| ( | 子组的开始标记 |
| ) | 子组的结束标记 |
| ? | 作为量词,表示 0 次或 1 次匹配。位于量词后面用于改变量词的贪婪特性。 (查阅量词) |
| * | 量词,0 次或多次匹配 |
| + | 量词,1 次或多次匹配 |
| { | 自定义量词开始标记 |
| } | 自定义量词结束标记 |
方括号内的元字符(字符类)
| 元字符 | 描述 |
|---|---|
| \ | 转义字符 |
| ^ | 仅在作为第一个字符(方括号内)时,表明字符类取反 |
| – | 标记字符范围 |
模式修复符号
模式修饰符中的空格,换行符会被忽略,其他字符会导致错误。
i (PCRE_CASELESS) 字母会进行大小写不敏感匹配。
m (PCRE_MULTILINE) 多行匹配,如果目标字符串 中没有 “\n” 字符,或者模式中没有出现 ^ 或 $,设置这个修饰符不产生任何影响。
s (PCRE_DOTALL)如果设置了这个修饰符,模式中的点号元字符匹配所有字符,包含换行符。如果没有这个 修饰符,点号不匹配换行符。这个修饰符等同于 perl 中的/s修饰符。 一个取反字符类比如 [^a] 总是匹配换行符,而不依赖于这个修饰符的设置。
x (PCRE_EXTENDED)如果设置了这个修饰符,模式中的没有经过转义的或不在字符类中的空白数据字符总会被忽略, 并且位于一个未转义的字符类外部的#字符和下一个换行符之间的字符也被忽略。 这个修饰符 等同于 perl 中的 /x 修饰符,使被编译模式中可以包含注释。 注意:这仅用于数据字符。 空白字符 还是不能在模式的特殊字符序列中出现,比如序列 (?( 引入了一个条件子组(译注: 这种语法定义的 特殊字符序列中如果出现空白字符会导致编译错误。 比如(?(就会导致错误)。
A (PCRE_ANCHORED)如果设置了这个修饰符,模式被强制为”锚定”模式,也就是说约束匹配使其仅从 目标字符串的开始位置搜索。这个效果同样可以使用适当的模式构造出来,并且 这也是 perl 种实现这种模式的唯一途径。
D (PCRE_DOLLAR_ENDONLY)如果这个修饰符被设置,模式中的元字符美元符号仅仅匹配目标字符串的末尾。如果这个修饰符 没有设置,当字符串以一个换行符结尾时, 美元符号还会匹配该换行符(但不会匹配之前的任何换行符)。 如果设置了修饰符m,这个修饰符被忽略.
S当一个模式需要多次使用的时候,为了得到匹配速度的提升,值得花费一些时间 对其进行一些额外的分析。如果设置了这个修饰符,这个额外的分析就会执行。当前, 这种对一个模式的分析仅仅适用于非锚定模式的匹配(即没有单独的固定开始字符)。
U (PCRE_UNGREEDY)这个修饰符逆转了量词的”贪婪”模式。 使量词默认为非贪婪的,通过量词后紧跟? 的方式可以使其成为贪婪的。这和 perl 是不兼容的。 它同样可以使用 模式内修饰符设置 (?U)进行设置, 或者在量词后以问号标记其非贪婪(比如.*?)。
注意:
在非贪婪模式,通常不能匹配超过 pcre.backtrack_limit 的字符。
X (PCRE_EXTRA)这个修饰符打开了 PCRE 与 perl 不兼容的附件功能。模式中的任意反斜线后就 ingen 一个 没有特殊含义的字符都会导致一个错误,以此保留这些字符以保证向后兼容性。 默认情况下,在 perl 中,反斜线紧跟一个没有特殊含义的字符被认为是该字符的原文。 当前没有其他特性由这个修饰符控制。
J (PCRE_INFO_JCHANGED)内部选项设置(?J)修改本地的PCRE_DUPNAMES选项。允许子组重名, (译注:只能通过内部选项设置,外部的 /J 设置会产生错误。) 自 PHP 7.2.0 起,也能支持 J 修饰符。
u (PCRE_UTF8)此修正符打开一个与 Perl 不兼容的附加功能。 模式和目标字符串都被认为是 UTF-8 的。 无效的目标字符串会导致 preg_* 函数什么都匹配不到; 无效的模式字符串会导致 E_WARNING 级别的错误。 5 字节和 6 字节的 UTF-8 字符序列以无效字符序列对待。
1) grep
最初是 ED 编辑器中的一条命令,用来显示文件中特定的内容。后来成为一个独立的工具 grep。
2) egrep
grep 虽然不断地更新升级,但仍然无法跟上技术的脚步。为此,贝尔实验室写出了 egrep,意为“扩展的 grep”。这大大增强了正则表达式的能力。
3) POSIX(Portable Operating System Interface of UNIX)
可移植操作系统接口。在 grep 发展的同时,其他一些开发人员也根据自己的喜好开发出了具有独特风格的版本。但问题也随之而来,有的程序支持某个元字符,而有的程序则不支持。因此,就有了POSIX。POSIX 是一系列标准,确保了操作系统之间的移植性。不过 POSIX 和 SQL 一样,没有成为最终的标准而只能作为一个参考。
4) Perl(Practical Extraction and Reporting Language)
实际抽取与汇报语言。1987 年,Larry Wall 发布了 Perl。在随后的 7 年时间里,从 Perl1 到现在的 Perl5,最终成为了 POSIX 之后的另一个标准。
5) PCRE
Perl 的成功,让其他的开发人员在某种程度上要兼容”Perl”,包括 C/C++、Java、Python 等都有自己的正则表达式。1997 年,Philip Hazel 开发了 PCRE 库,这是兼容 Perl 正则表达式的一套正则引擎,其他开发人员可以将 PCRE 整合到自己的语言中,为用户提供丰富的正则功能。许多软件都使用 PCRE,PHP 正是其中的一员。
PHP 有两套函数库支持的正则表达式处理操作:
区别
js正则:var patrn=/^[0-9]{1,20}$/;
php正则:$pattern='/(\d)(\d)/';
java正则:String pattern = “(\\D*)(\\d+)(.*)”;
java没有分解符,java中的转义字符是\\。
JS和PHP和JAVA的正则表达式的区别:规则大致一样,注意细微处的差别
常用正则表达式
参考
目的,为了使命名更具有语义化和可读性,方便维护
以laravel框架为例,按实际操作行为划分
表字段,标注注释,表索引
创建表
create_xxxx_table.php删除表
drop_xxxx_table.php修改表
包含添加删除字段或索引或其他 ,2种以上行为
modify_xxxx_table.php字段名称,字段数据类型,字段注释
添加字段
create_xxxx_table_column.php删除字段
drop_xxxx_table_column.php修改字段
包含添加和删除和修改字段,2种以上行为
modify_xxxx_table_column.php操作普通索引,全文索引,空间索引等;
索引优化是业务开发中,修改频率很高的行为,所以需要单独列出来,有很多场景需要,单独的变更索引,而不修改字段
添加索引
create_xxxx_table_index.php删除索引
drop_xxxx_table_index.php修改索引
包含添加 删除 修改 和自定义 2种以上行为时
modify_xxxx_table_index.php单一操作行为的规则,参考上文以此类推。
多次重复行为时增加语义化版本后缀
需要改进
比如第一次业务变更 增加了字段 create_users_table_column.php
第二次业务变更,又要对users表增加字段,则命名为 create_users_table_column_v1.0.0.php
// 转储当前数据库架构并删除所有现有迁移。。。
php artisan schema:dump --prune操作系统->编程语言->框架类库->Web API
编程语言是对操作系统的API封装,框架类库是对编程语言API的封装, Web API是对框架类库的封装
| RPC | REST API | WebSocket API | |
| 消息格式 | 二进制Thrift,Protobuf,GRPC | 文本XML,JSON,GraphQL | 二级制,文本json |
| 通讯协议 | TCP | HTTP,HTTP/2 | HTTP,websocket |
| 性能 | 高 | 一般 | 一般 |
| 接口契约IDL | Thrift,Protobuf IDL | Swagger | Swagger |
| 客户端 | 强类型客户端 | HTTP客户端 | websocket客户端 |
| 框架 | Dubbo,GPRC,Thrift | web框架 | websocket框架 |
| 开发者友好 | 一般自动生成存根、客户端、使用友好,二进制消息阅读不友好 | json可读性高,通用性 | json可读性高,通用性 |
| 应用场景 | 服务间通讯推荐PRC | 对外暴露接口推荐REST | 大文件类的流式数据,语言识别服务 |
业务应用
app,小程序,pc站,手机站 等客户端提供 api
开放平台(Open API)
PaaS,SaaS Serverless 平台的服务API
规范和风格
restful api 风格,laravel框架自带
github路由风格,https://api.github.com/
全部小写,多单词时用短划线分隔
http://xxxx/register-phone不要用下划线,下划线的域名和路由在一些第三方开放平台无法通过验证,如qq互联申请时
鉴权
OAuth2
防止重放攻击
请求限流
按时间限流,req/minute
随机拒绝,如秒杀场景
api(路由)版本管理
调用接口
主要功能,很多sdk都是使用该类库开发
写爬虫抓取页面
项目中应用案例
java的古籍PC网站,该项目无人维护,无法提供书籍数据的接口。分析页面结构和接口使用guzzle库爬取书籍数据,完成数据对接。
在所用请求中共享cookie功能 文档
//创建客户端
$this->client = new Client([
'base_uri' => $this->config['base_uri'],
'timeout' => 20.0,
'cookies' => true, //共享cookie会话
);
//登录
protected function login()
{
$response = $this->client->request('POST', 'XXX', [
'headers' => [
'Accept' => 'application/json'
],
'form_params' => [
'loginName' => $this->config['login_name'],
'loginPassword' => $this->config['login_password']
]
]);
$json = json_decode($response->getBody(), true);
if (isset($json['operateMsg']) && $json['operateMsg'] !== '登录成功!') {
throw new GujiException('原古籍系统账号故障');
}
}
//请求接口数据
protected function request(string $pathUrl, array $param)
{
$this->login(); //首先登录获取Cookies
$response = $this->client->request('POST', $pathUrl, [
'headers' => [
'Accept' => 'application/json'
],
'form_params' => $param
]);
$contents = $response->getBody()->getContents();
$json = json_decode($contents, true);
if (json_last_error() === JSON_ERROR_NONE) {
return $json;
} elseif (json_last_error() == 10) {
//解决json_decode错误Single unpaired UTF-16 surrogate in unicode escape
$contents = \preg_replace('/(?<!\\\)\\\u[a-f0-9]{4}/iu', '', $contents);
$json = \json_decode($contents, true);
if (json_last_error() !== JSON_ERROR_NONE) {
$json = $this->customJsonDecode($contents);
}
return $json;
}
{
throw new GujiException("请求古籍系统接口失败");
}
}
//抓取页面数据
protected function capture(string $pathUrl, array $param = [])
{
$this->login(); //首先登录获取Cookies
$response = $this->client->request('GET', $pathUrl, $param);
if ($response->getStatusCode() == 200) {
//获取页面内容
return $response->getBody()->getContents();
} else {
throw new GujiException("古籍系统故障");
}
}跟随重定向
https://docs.guzzlephp.org/en/stable/faq.html#how-can-i-track-redirected-requests
https://docs.guzzlephp.org/en/stable/request-options.html#allow-redirects
调用非知名第三方支付系统,前后端分离架构,前端重定向到接口,接口调用第三方支付接口,成功后跟随响应到成功页面
use Illuminate\Support\Facades\Http;
use Psr\Http\Message\UriInterface;
use Psr\Http\Message\RequestInterface;
use Psr\Http\Message\ResponseInterface;
//Http::withOptions laravel对guzzle的封装,详情看文档
$response = Http::withOptions([
'allow_redirects' => [
'max' => 1,
'on_redirect' => function (
RequestInterface $request,
ResponseInterface $response,
UriInterface $uri
) use ($data) {
//自动跟随重定向响应
header('Location:' . $uri);
},
]
])->asForm()->post($this->config['base_uri'] . '/multipay/h5.do', $data);代码质量的评价词
灵活性(flexibility)、可扩展性(extensibility)、可维护性(maintainability)、可读性(readability)、可理解性(understandability)、易修改性(changeability)、可复用(reusability)、可测试性(testability)、模块化(modularity)、高内聚低耦合(high cohesion loose coupling)、高效(high effciency)、高性能(high performance)、安全性(security)、兼容性(compatibility)、易用性(usability)、整洁(clean)、清晰(clarity)、简单(simple)、直接(straightforward)、少即是多(less code is more)、文档详尽(well-documented)、分层清晰(well-layered)、正确性(correctness、bug free)、健壮性(robustness)、鲁棒性(robustness)、可用性(reliability)、可伸缩性(scalability)、稳定性(stability)、优雅(elegant)、好(good)、坏(bad)
面向对象和面向过程是编程范式(方法),不局限于编程语言,即使语言不是面向对象的语言。面向过程语言的特点是不支持丰富的面向对象编程特性(继承,多台,封装)。
面向过程风格的代码被组织成了一组方法集合及其数据结构(struct User),方法和数据结构的定义是分开的
面向对象风格的代码被组织成一组类,方法和数据结构被绑定一起,定义在类中。
面向对象编程语言更适用于大规模复杂应用。二进制指令,汇编语言,面向过程语言,是一种计算机思维方式,面向对象是一种人类思维方式,需要对业务建模,将现实的世界的事物,映射为类或对象,将开发者聚焦业务本身,而不是思考如何和机器打交道。
面向过程风格代码转换面向对象风格,规律总结,
函数等于类方法,复用的变量等于类型属性,
滥用geter,setter,违反了封装特性,举例:将购物车列表list可以随意修改,不应该将业务逻辑暴露给上层代码,要封装到方法中。让上层无法随意修改list
封装:通过访问控制语法提供数据访问保护,隐藏内部数据,外部仅能通过类有限的结果访问修改内部数据。调用者无需关心业务的细节,调用就可以了。
抽象:基于interface和abstract语法,更好的实现封装的方法,隐藏实现细节,是封装的具体实现。
继承:获取父类的方法和属性,复用代码,使用时要避免过度继承和高度耦合
多态:基于,父类可以引用子类,支持继承语法,子类可以重写(override)父类中的方法的语法机制实现多态特性。可以基于interface类实现,提高代码扩展性和复用性
面向对象语言的的设计流程,类分析->类设计->实现
思考如何给业务建模,如何将需求翻译为类,如何给类之间建立交互关系,而完成这些工作完全不需要考虑错综复杂的处理流程。
有了类的设计之后,然后再像搭积木一样,按照处理流程,将类组装起来形成整个程序。这种开发模式、思考问题的方式,能让我们在应对复杂程序开发的时候,思路更加清晰
面向对象编程比面向过程编程,更加容易应对大规模复杂程序的开发。但像 Unix、Linux 这些复杂的系统,也都是基于 C 语言这种面向过程的编程语言开发的,你怎么看待这个现象?
取决于需求是业务复杂度,还是技术复杂度
1.面向过程的编程语言不代表不能实现面向对象思想 2.操作系统的复杂相对于业务系统的快速开发迭代是另一个维度复杂,基础系统更看重性能和稳定,而业务系统看重的是维护,复用,拓展。3.操作系统是要频繁跟硬件打交道的,“低级”的语言更快更简洁
接口和抽象类,基于接口而非实现编程
组合优于继承
贫血模型和充血模型
随着编程语言的演进,一些设计模式(比如 Singleton)也随之过时,甚至成了反模式,一些则被内置在编程语言中(比如 Iterator),另外还有一些新的模式诞生(比如 Monostate)。
反面模式 明显出现但又低效或是有待优化的设计模式,是用来解决问题的带有共同性的不良方法

场景:数据库连接 日志 在应用中锁定文件 线程池(threadpool)、缓存(cache)、对话框、处理偏好设置和注册表(register)对象
laravel中服务容器注册单例类 simps-swoole使用单例trait来实现单例
管道设计范式
Laravel 中的 Pipeline (管道) — 管道设计范式
在 PHP 中管道( Pipeline (管道) ) 能帮我们做什么?
泛化、实现、关联、聚合、组合、依赖
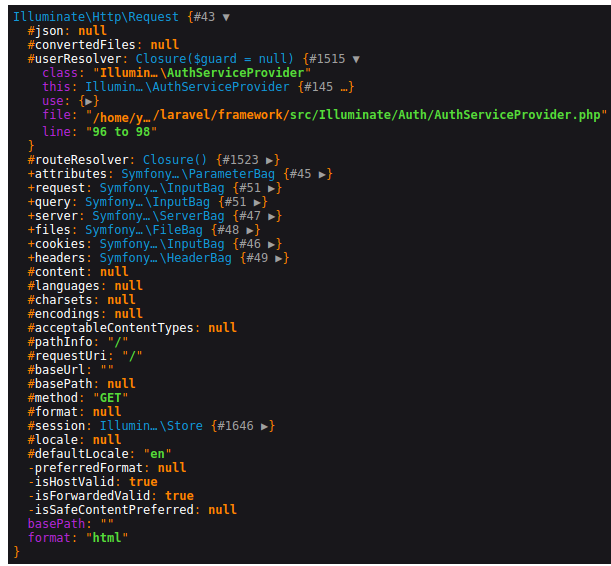
uml类图符号的作用,以laravel框架的request类 dd($request)结果为示例,“+”表示 public ,“-”表示 private, “#”表示 protected ,不带符号表示 default
参考教程
日志目录
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信息
/var/log/cron 与定时任务相关的日志信息
/var/log/spooler 与UUCP和news设备相关的日志信息
/var/log/boot.log 守护进程启动和停止相关的日志消息
/var/log/wtmp 该日志文件永久记录每个用户登录、注销及系统的启动、停机的事件
/var/log/yum.log
/var/log/syslog
/var/log/dmesg
/var/log/journalhistory 显示或操作历史列表 文档
more 显示文件内容,每次显示一屏 文档
Space 键:显示文本的下一屏内容。Enter 键:只显示文本的下一行内容。|:接着输入一个模式,可以在文本中寻找下一个相匹配的模式。less 分屏上下翻页浏览文件内容 文档
tail 在屏幕上显示指定文件的末尾若干行 文档
#查看指定ip的nginx日志
tail -f /dir_name/access.log | grep xxx.xxx.xxx.xxxsudo journalctl -xe 查看systemd 错误日志 journalctl
参考
ag – 通过目录层次结构,快速搜索文本
Linux shell 中$() ` `,${},$[] $(()),[ ] (( )) [[ ]]作用与区别
currentdate=$(date +%Y%m%d)字符串操作
Here 文档内部会发生变量替换,同时支持反斜杠转义,但是不支持通配符扩展,双引号和单引号也失去语法作用,变成了普通字符。
cat >> 1.txt <<EOF
export NVM_DIR="\$HOME/.nvm"
[ -s "\$NVM_DIR/nvm.sh" ] && \. "\$NVM_DIR/nvm.sh" # This loads nvm
[ -s "\$NVM_DIR/bash_completion" ] && \. "\$NVM_DIR/bash_completion" # This loads nvm bash_completion
EOFsudo -u username command
su -c "cd /www/wwwroot/tuntun/server_php && /www/server/php/74/bin/php artisan schedule:run >> /dev/null 2>&1" -s /bin/sh www应用场景描述
安装nvm脚本时需要添加环境变量,卸载时又想把环境变量删除。可以在写入时,在文件末尾追加特殊标识,删除时通过sed删除末尾有标识行
#写入时增加##nvm标识
cat >> /home/${run_user}/.bashrc <<EOF
export NVM_DIR="\$HOME/.nvm"##nvm
[ -s "\$NVM_DIR/nvm.sh" ] && \. "\$NVM_DIR/nvm.sh"##nvm
[ -s "\$NVM_DIR/bash_completion" ] && \. "\$NVM_DIR/bash_completion"##nvm
EOF
#删除末尾有##nvm的行,通过元字符$匹配
sed -i '/##nvm$/d' .bashrc#方式一
cat /proc/version
Linux version 5.13.0-51-generic (buildd@lcy02-amd64-046) (gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0, GNU ld (GNU Binutils for Ubuntu) 2.34) #58~20.04.1-Ubuntu SMP Tue Jun 14 11:29:12 UTC 2022
#方式二
uname -a
Linux MINIPC-PN51-E1 5.13.0-51-generic #58~20.04.1-Ubuntu SMP Tue Jun 14 11:29:12 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux#方式一
lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.4 LTS
Release: 20.04
Codename: focal
#方式二
cat /etc/issue
Ubuntu 20.04.4 LTS
#仅适合Redhat系的Linux
cat /etc/redhat-release
Linux shell中2>&1的含义解释 (全网最全,看完就懂)
#读取目录下名字为php*的目录,存为数组, 然后合并数组
enable_dir=(`find /usr/local/php/etc/php.d -maxdepth 1 -type f -name "*.ini" | sort`)
disable_dir=(`find /usr/local/php/etc/php.d/disable -maxdepth 1 -type f -name "*.ini" | sort`)
extension_dir=(${enable_dir[@]} ${disable_dir[@]})