相关文章
MySQL存储海量数据的最后一招:分库分表 后端存储实战课—后端存储实战
官方文档描述比较全面,但是不够简洁以及没有操作流程,所以记录一下备忘。
本文是简单实用的快捷配置方式,使用smtp服务,具体需求看官方文档。
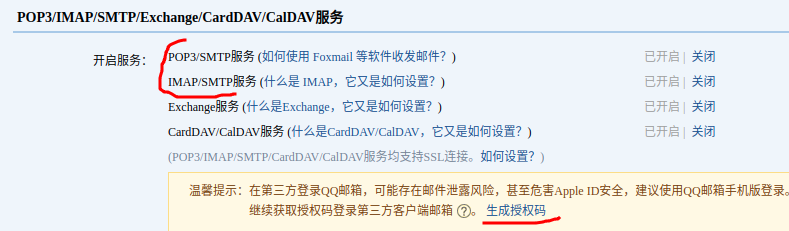
申请发件邮箱,开启SMTP服务
以qq邮箱为例,授权码即使邮箱发送时验证的密码
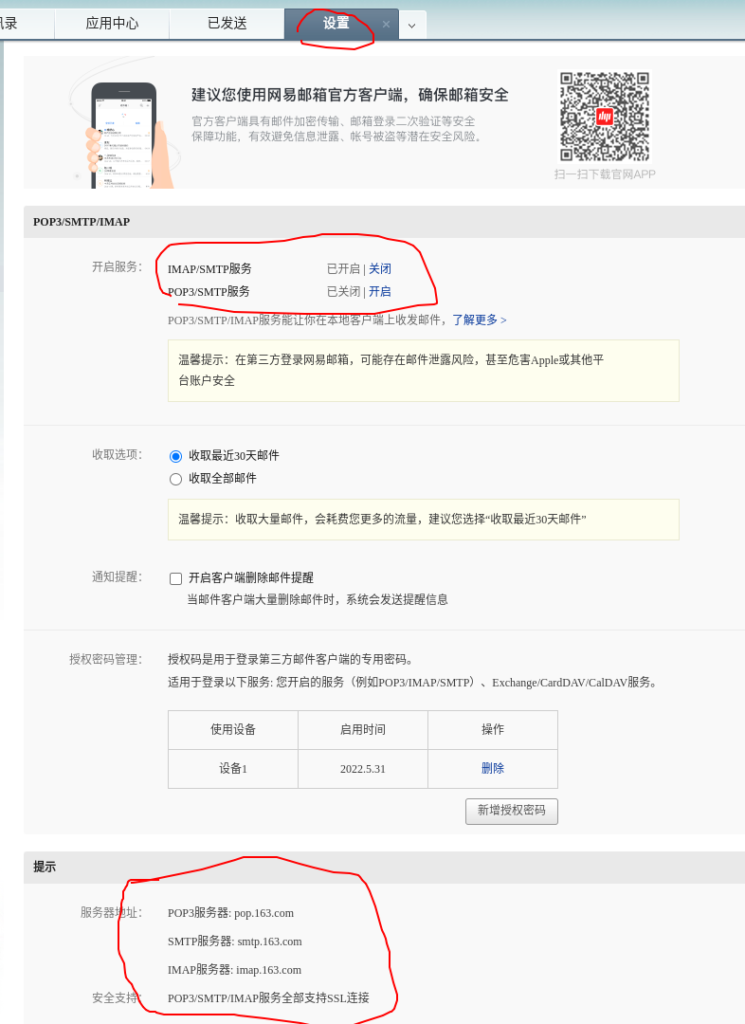
网易163邮箱配置
以客户留言接收邮件通知为例 markdown邮件文档
//生成Mailables Markdown 邮件
php artisan make:mail CustomerFeedbackMail --markdown=emails.customer.feedback
如图会生成两个文件,然后编写代码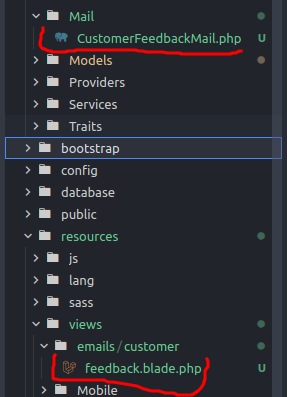
配置在浏览器中预览邮件 文档
//添加路由
Route::get('mailable', 'Pc\PageController@mailable');//预览mark邮件
//控制器方法
public function mailable(Request $request)
{
return new CustomerFeedbackMail();
}
//简单编辑邮件模板feedback.blade.php
@component('mail::message')
# 邮件通知
The body of your message.
@component('mail::button', ['url' => ''])
进入官网后台管理
@endcomponent
@endcomponent引入通知用到模型数据 文档
//预览页面控制器
class PageController extends Controller
{
public function mailable(Request $request)
{
$message = Message::find(1);
return new CustomerFeedbackMail($message);
}
}
//邮件mailable
class CustomerFeedbackMail extends Mailable
{
use Queueable, SerializesModels;
public $message;
public function __construct(Message $message)
{
$this->message = $message;
}
/**
* Build the message.
*
* @return $this
*/
public function build()
{
//emails.customer.feedback是视图文件目录和文件
return $this->markdown('emails.customer.feedback', ['feedback' => $this->message])->subject('邮件标题');
}
}
//邮件视图文件markdown
@component('mail::message')
# 客户留言通知
## 姓名:{{$feedback->name}},
## 电话:{{$feedback->mobile}},
## 留言:{{$feedback->content}},
## 提交终端:{{$feedback->terminal}},
## 提交页面名称:{{$feedback->page_name}},
@component('mail::button', ['url' => ''])
进入官网后台管理
@endcomponent
@endcomponent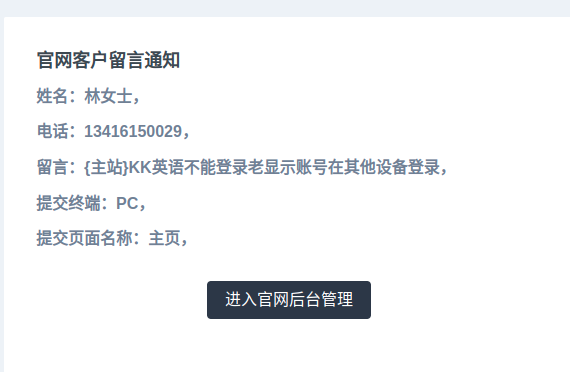
发送到指定邮箱 遍历收件人列表
//修改config/mail.php 配置,增加默认收件邮箱
'to' => [
'address' => explode(',', env('MAIL_DEFAULT_TO_ADDRESS', '')),
'name' => env('MAIL_TO_NAME', ''),
],
//修改env配置
MAIL_MAILER=smtp
MAIL_HOST=smtp.qq.com
MAIL_PORT=465
MAIL_USERNAME=xxxx@qq.com
MAIL_PASSWORD=xxxx
MAIL_ENCRYPTION=ssl
MAIL_FROM_ADDRESS=xxx@qq.com
MAIL_FROM_NAME=xxx
MAIL_DEFAULT_TO_ADDRESS=xxx@foxmail.com
MAIL_TO_NAME=留言通知
//发送代码,此处使用terminable中间件延时发送
use Illuminate\Support\Facades\Log;
use Illuminate\Support\Facades\Mail;
use App\Mail\CustomerFeedbackMail;
use App\Models\Message;
class SendFeedbackMailTerminable
{
/**
* Handle an incoming request.
*
* @param \Illuminate\Http\Request $request
* @param \Closure $next
* @return mixed
*/
public function handle($request, Closure $next)
{
return $next($request);
}
public function terminate($request, $response)
{
$response_data = json_decode($response->getContent(), true);
if (!isset($response_data['data']['message_id']) || empty($response_data['data']['message_id'])) {
return;
}
Log::info('留言id=>'.$response_data['data']['message_id']);
$message = Message::find($response_data['data']['message_id']);
if (!$message instanceof Message) {
return;
}
$toAddress = config('mail.to.address');
foreach ($toAddress as $value) {
try {
Mail::to($value)->send(new CustomerFeedbackMail($message));
} catch (\Throwable $th) {
Log::channel('sendmail')->info('发送邮件失败'.$th->getMessage());
continue;
}
Log::channel('sendmail')->info('[官网留言邮件通知记录]:', ['email' => $value, 'message_id' => $response_data['data']['message_id']]);
}
}
}普通重启方法,按住音量减同时按住电源建。之后会出现滑动关机和医疗卡以及SOS按钮。
IPhone 11如果如果卡死,正常的启动无法启动。需要强制重启,按一下手机侧面的音量加键,之后按一下音量减键,然后按住电源键不放,直到出现滑动关机按钮,(注意此时没有医疗卡和SOS按钮只有滑动关机),之后等待手机重启即可。
有一次出现,卡死灰屏,上述方法没生效。试了一下同事按住音量加,音量减,然后按住电源不放。最后重启了。
下载地址
下载ES 下载kibana logstash cerebo analysis-ik中文分词插件 用户案例
所有软件及插件版本必须一致
启动方式systemed
service elasticsearch start查看版本
sudo /usr/share/elasticsearch/bin/elasticsearch --version
Version: 7.17.1, Build: default/deb/e5acb99f822233d62d6444ce45a4543dc1c8059a/2022-02-23T22:20:54.153567231Z, JVM: 17.0.2开发机器修改内存配置
//配置文件目录,如果没有权限请使用高权限账号修改
/etc/elasticsearch/jvm.options
//内存配置项,开发机建议设置为1~2g节省内存,生产环境不能超过32g
-Xms1g
-Xmx1g安装插件 以analysis-ik为例
插件默认目录:/usr/share/elasticsearch/plugins 新建目录ik
下载插件,移动所有文件到ik目录下,重启elasticsearch
sudo cd /usr/share/elasticsearch/plugins
sudo unzip -o elasticsearch-analysis-ik-x.x.x.zip -d ik
sudo rm -rf elasticsearch-analysis-ik-x.x.x.zip访问地址和默认端口 http://127.0.0.1:9200/
{
"name" : "MINIPC-PN51-E1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "e9ml_7fiTemo3tW5ug5_Jg",
"version" : {
"number" : "7.17.0",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "bee86328705acaa9a6daede7140defd4d9ec56bd",
"build_date" : "2022-01-28T08:36:04.875279988Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}配置用户名,密码
service kibana start访问地址和默认端口 http://localhost:5601/
汉化配置
//配置文件目录
/etc/kibana/kibana.yml
//i18n 设置为中文
i18n.locale: "zh-CN"下载logstash 需要安装jdk
下载地址 需要安装jdk
启动失败解决方法
#修改systemd配置 /usr/lib/systemd/system/cerebro.service
ExecStart=/usr/share/cerebro/bin/cerebro -java-home /usr/java/jdk-11.0.12 -Dhttp.port=9000 -Dhttp.address=127.0.0.1service cerebro start访问地址和默认端口 http://localhost:9000/
GCC编译器 官网
通过apt yum dnf 等包管理工具安装
GCC原名为GNU C语言编译器(GNU C Compiler),只能处理C语言。但其很快扩展,变得可处理C++,后来又扩展为能够支持更多编程语言,如Fortran、Pascal、Objective -C、Java、Ada、Go以及各类处理器架构上的汇编语言等,所以改名GNU编译器套件(GNU Compiler Collection) [1] 。
Make 文档
通过apt yum dnf 等包管理工具安装
GNU Make是一个可以自动运行shell命令并帮助执行重复任务的程序。它通常用于将文件转换成其他形式,例如将源代码文件编译成程序或库。
Make适用于构建小型C/ c++项目或库,这些项目或库将包含在另一个项目的构建系统中。大多数构建系统都有办法集成基于make的子项目。
对于较大的项目,您会发现更现代的构建系统更易于使用。
在以下情况下,我建议使用非Make的构建系统:
当正在构建的目标(或文件)数量为(或最终将为)数百时。 需要一个“配置”步骤,它设置和保存变量、目标定义和环境配置。 该项目将保持内部或私有,将不需要由终端用户构建。 您会发现调试是一项令人沮丧的工作。 您需要构建的是跨平台的,可以在macOS、Linux和Windows上构建。 在这些情况下,您可能会发现使用CMake、Bazel、Meson或其他现代构建系统是一种更愉快的体验。
一般情况下发布的linux源码包中包含了makefile文件
Autoconf 官网
帮助我软件开发者通过使用GNU m4语言在configure.ac中写出限定配置脚本行为的列表。Autoconf将configure.ac中的命令转化为对应特定平台的配置脚本。Autoconf本身并不具备编译能力,它仅仅用于产生通常附带在软件包中的配置脚本。生成configure脚本。
Automake
是一种编程工具,可以产生供make程序使用的Makefile,用来编译程序。它是自由软件基金会发起的GNU计划的其中一项,作为GNU构建系统的一部分。automake所产生的Makefile符合GNU编程标准。
automake是由Perl语言所写的,必须和GNU autoconf一并使用。
具体使用参考相关文章automake,autoconf使用详解
CMake 官网
跨平台的编译工具 ,一般情况下不用(c语言的程序),因为服务器软件大多跑在linux上。
可以用简单的语句来描述所有平台的安装(编译过程)。他能够输出各种各样的makefile或者project文件,能测试编译器所支持的C++特性,类似UNIX下的automake。只是 CMake 的组态档取名为 CMakeLists.txt。Cmake 并不直接建构出最终的软件,而是产生标准的建构档(如 Unix 的 Makefile 或 Windows Visual C++ 的 projects/workspaces),然后再依一般的建构方式使用。这使得熟悉某个集成开发环境(IDE)的开发者可以用标准的方式建构他的软件,这种可以使用各平台的原生建构系统的能力是 CMake 和 SCons 等其他类似系统的区别之处。

configure配置
通过 –help可以查看命令选项

默认的通用参数 --prefix安装目录,不指定则安装到默认目录
./configure --prefix=/xxx/xxx/
其他配置项,需要看具体软件编译安装文档说明make -j 线程数 加速编译 ldd 二进制程序文件 可以查看静态的二进制文件依赖的共享库
lsof -p PID 显示Linux系统当前已打开的所有文件列表,PID为进程数字
执行./configure 根据依赖报错来确定需要的依赖
安装后提示xxx.so.7: cannot open shared object file: No such file or directory
执行 ldconfig /usr/local/lib/ 更新动态库缓存
编译安装php
编译安装ffmpeg
相关文章
我们平常写的高级语言和汇编语言是个人看的CPU无法直接运行,需要编译成机器码给CPU执行。
从软件工程师的角度来讲,CPU 就是一个执行各种计算机指令(Instruction Code)的逻辑机器。这里的计算机指令,就好比一门 CPU 能够听得懂的语言,我们也可以把它叫作机器语言(Machine Language)。
不同的 CPU 能够听懂的语言不太一样。比如,我们的个人电脑用的是 Intel 的 CPU,苹果手机用的是 ARM 的 CPU。这两者能听懂的语言就不太一样。类似这样两种 CPU 各自支持的语言,就是两组不同的计算机指令集,英文叫 Instruction Set。这里面的“Set”,其实就是数学上的集合,代表不同的单词、语法。
复杂指令集计算机包含许多应用程序中很少使用的特定指令,由此产生的缺陷是指令长度不固定。
目前x86架构微处理器如Intel的Pentium/Celeron/Xeon与AMD的Athlon/Duron/Sempron;以及其64位扩展系统的x86-64架构的Intel 64的Intel Core/Core 2/Celeron/Pentium/Xeon与AMD64的Phenom II/Phenom/Athlon 64/Athlon II/Opteron/AMD APU/Ryzen/EPYC都属于复杂指令集。主要针对的操作系统是微软的Windows和苹果公司的macOS。另外Linux,一些UNIX等,都可以运行在x86(复杂指令集)架构的微处理器。
精简指令集计算机通过只执行在程序中经常使用的指令来简化处理器的结构,而特殊操作则以子程序的方式实现,它们的特殊使用通过处理器额外的执行时间来弥补。
这种指令集运算包括惠普的PA-RISC,国际商业机器的PowerPC,康柏(后被惠普收购)的Alpha,美普思科技公司的MIPS,SUN公司的SPARC,ARM公司的ARM架构等。目前有UNIX、Linux以及包括iOS、Android、Windows Phone等在内的大多数移动操作系统运行在精简指令集的处理器上。
除了 C 这样的编译型的语言之外,不管是 Python 这样的解释型语言,还是 Java 这样使用虚拟机的语言,其实最终都是由不同形式的程序,把我们写好的代码,转换成 CPU 能够理解的机器码来执行的。只是解释型语言,是通过解释器在程序运行的时候逐句翻译,而 Java 这样使用虚拟机的语言,则是由虚拟机对编译出来的中间代码进行解释,或者即时编译成为机器码来最终执行。
为什么同一个程序,在同一台计算机上(可是我们的 CPU 并没有换掉,指令集是同一个),在 Linux 下可以运行,而在 Windows 下却不行呢?反过来,Windows 上的程序在 Linux 上也是一样不能执行的?
C 语言代码 – 汇编代码 – 机器码” 这个过程,在我们的计算机上进行的时候是由两部分组成的。
第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。在这三个阶段完成之后,我们就生成了一个可执行文件。
第二部分,我们通过装载器(Loader)把可执行文件装载(Load)到内存中。CPU 从内存中读取指令和数据,来开始真正执行程序。
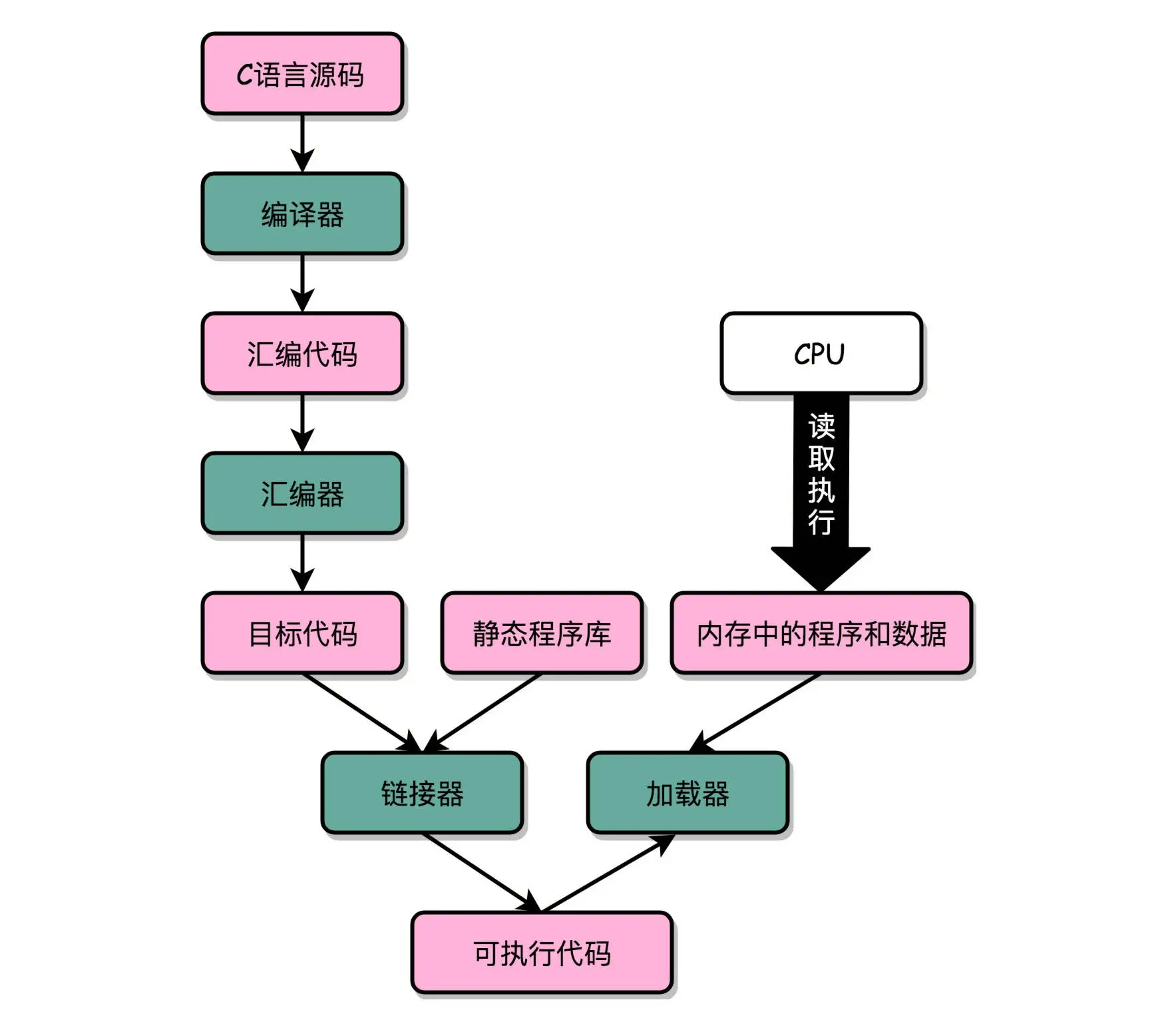
在 Linux 下,可执行文件和目标文件所使用的都是一种叫 ELF(Execuatable and Linkable File Format)的文件格式,中文名字叫可执行与可链接文件格式,这里面不仅存放了编译成的汇编指令,还保留了很多别的数据,包含所有的代码,都存放在这个 ELF 格式文件里。这些名字和它们对应的地址,在 ELF 文件里面,存储在一个叫作符号表(Symbols Table)的位置里。符号表相当于一个地址簿,把名字和地址关联了起来
链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。
在链接器把程序变成可执行文件之后,要装载器去执行程序就容易多了。装载器不再需要考虑地址跳转的问题,只需要解析 ELF 文件,把对应的指令和数据,加载到内存里面供 CPU 执行就可以了。
Linux 下的 ELF 文件格式,而 Windows 的可执行文件格式是一种叫作 PE(Portable Executable Format)的文件格式。Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。
Linux 下著名的开源项目 Wine,就是通过兼容 PE 格式的装载器,使得我们能直接在 Linux 下运行 Windows 程序的。而现在微软的 Windows 里面也提供了 WSL,也就是 Windows Subsystem for Linux,可以解析和加载 ELF 格式的文件。
推荐阅读想要更深入了解程序的链接过程和 ELF 格式,我推荐你阅读《程序员的自我修养——链接、装载和库》的 1~4 章。这是一本难得的讲解程序的链接、装载和运行的好书。
本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序:
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
二级制安装包,是厂商预先在对应的cpu架构的电脑上编译好的二进制安装包,然后通过包管理工具分发,yum,rpm,apt,dpkg.优点是安装快。缺点是一些特殊的软件无法进行定制安装,目录和相关配置无法指定都是预先编译好的。
编译安装比较耗费时间,可以对模块进行定制,安装到指定目录。升级时需要重新编译
举例说明,比如php语言这种模块形式的服务软件,有很多扩展用不到,用软件包完全安装之后占用更多的系统资源,而有的第三方的模块,系统分发的软件包里没有,需要自己重新编译
从操作系统的角度来说,它仅仅提供最原始的系统调用是不够的,有很多业务逻辑的封装,在用户态来做更合适。但是,它也无法去穷举所有的编程语言,然后一一为它们开发各种语言的基础库。那怎么办?
聪明的操作系统设计者们想了一个好办法:动态库。几乎所有主流操作系统都有自己的动态库设计,包括:
动态库本质上是实现了一个语言无关的代码复用机制。它是二进制级别的复用,而不是代码级别的。这很有用,大大降低了编程语言标准库的工作量。
动态库的原理其实很简单,核心考虑两个东西。
有了动态库,编程语言的设计者实现其标准库来说就多了一个选择:直接调用动态库的函数并进行适度的语义包装。大部分语言会选择这条路,而不是直接用系统调用。
例如php的各种扩展,调用系统的动态库

可以通过在.bashrc或者.cshrc中配置该环境变量,LD_LIBRARY_PATH的意思是告诉loader在哪些目录中可以找到共享库. 可以设置多个搜索目录, 这些目录之间用冒号分隔开.
同样是上面的例子,可以通过以上的方法来实现
在.bashrc或.cshrc中增加一行,export LD_LIBRARY_PATH = ~/exe:$LD_LIBRARY_PATH即可。
通过编译选项-Wl, -rpath指定动态搜索的路径
-Wl选项告诉编译器将后面的参数传递给链接器
pkg-configpkg-config 是一个用于检索安装在Linux系统上的库文件信息和编译选项的工具。 而 pkgconfig 目录则是默认的包含了许多库文件信息和编译选项的目录之一。当我们想要使用被安装在系统上的某个库文件时,我们需要指定它的头文件路径、链接库路径和其他编译选项等信息,而这些信息通常会存储在 /usr/local/lib/pkgconfig/ 或者 /usr/lib/pkgconfig/(根据不同的发行版,目录可能有所不同)等目录下的对应库文件的 .pc 文件中。使用 pkg-config 工具可以方便地读取这些信息,并将它们传递给编译器来编译我们自己的程序,以便正确地链接和运行所需的库文件
在某些情况下,我们需要根据需要手动指定pkgconfig的目录
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig/:$PKG_CONFIG_PATH常见的pkg config 目录,ubuntu系统
/usr/lib/pkgconfig
/usr/lib/x86_64-linux-gnu/pkgconfig
/usr/local/lib/pkgconfig
相关文章
消息功能和站内信的需求概括
B站消息功能界面截图
一般项目的消息功能都会有多种类型,比如订单状态推送,点赞推送,收藏,系统通知,到期提醒,系统公告(后台会有发送消息的需求)。同时可能会伴随多种渠道(短信,邮件,app push)的消息推送。
按推送用户数量分为,发送给全部用户,发送给部分用户,实现发送消息和已读状态更能,在用户数量不多(中小型项目)的情况下,最适合的方法是存中间表。
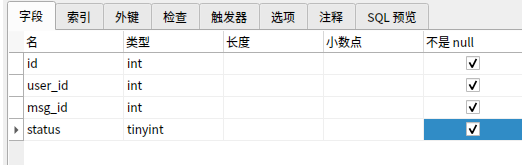
当用户数量增长之后,比如100万人同时点赞,每天产生的数据量非常大,不存数据库该如何实现?
方案一 使用 redis 的 bitmap
参考 一看就懂系列之 详解redis的bitmap在亿级项目中的应用
redis bitmap介绍
bitmap不是一个实际的数据类型,而是一组定义在String类型上的面向位的操作。由于字符串是二进制安全的blobs,其最大长度为512MB,所以它们适合设置2^32个不同的位。
位操作分为两组:恒定时间的单位操作,如将一个位设置为1或0,或获得其值,以及对位组的操作,如在给定的位范围内计算设置的位的数量(如人口计数)。
位图最大的优点之一是,它们在存储信息时往往能极大地节省空间。例如在一个系统中,不同的用户由递增的用户ID代表,只需使用512MB的内存就可以记住40亿用户的一个比特信息(例如,知道一个用户是否想收到通讯)。
位是用SETBIT和GETBIT命令来设置和检索的。
setbit key 10 1
(整数) 1
getbit key 10
(整数) 1
getbit key 11
(整数) 0
SETBIT命令的第一个参数是位号,第二个参数是要将该位设置为的值,即1或0。
GETBIT只是返回指定索引处的位的值。超出范围的位(寻址的位在存储到目标键的字符串长度之外)总是被认为是零。
有三个命令对位组进行操作。
BITOP在不同的字符串之间进行位的操作。提供的操作有AND、OR、XOR和NOT。
BITCOUNT执行群体计数,报告设置为1的位的数量。
BITPOS找到第一个具有指定值0或1的位。
BITPOS和BITCOUNT都能对字符串的字节范围进行操作,而不是对字符串的整个长度进行操作。下面是一个调用BITCOUNT的微不足道的例子。
setbit key 0 1
(integer) 0
setbit key 100 1
(整数) 0
bitcount key
(整数) 2
位图的常见用户案例有。
各种类型的实时分析。
储存与对象ID相关的节省空间但性能高的布尔信息。
例如,想象一下,你想知道你的网站用户每天访问的最长连贯时间。你从零开始计算天数,也就是你公开网站的那一天,并在每次用户访问网站的时候用SETBIT设置一个位。作为一个比特索引,你只需取当前的unix时间,减去初始偏移量,然后除以3600*24。
这样,对于每个用户,你都有一个包含每天访问信息的小字符串。通过BITCOUNT可以很容易地得到一个给定的用户访问网站的天数,而通过几个BITPOS调用,或者简单地获取和分析客户端的位图,就可以很容易地计算出最长的连绵时间。
将位图分割成多个键是很容易的,例如,为了分片数据集,以及在一般情况下,最好避免使用巨大的键。为了将一个位图分割成不同的键,而不是将所有的位设置成一个键,一个简单的策略就是每个键存储M个位,用位数/M获得键的名称,用位数MOD M获得键内的第N位。
//设置用户已读:
$redis->setBit('message:'.$msg_id, $uid, 1);
//获取是否读取状态:
$redis->getBit('message:'.$msg_id, $uid);
//支持千万级用户,并且不会有数据存储方面的压力
另外:bitmap 还可以做签到,活跃统计,在线状态等等参考文章
技术方案参考文章
消息功能中系统通知这一类信息的已读未读除了用数据表之外有没有比较好的解决方案
37 | 计数系统设计(一):面对海量数据的计数器要如何做?——极客时间