简介
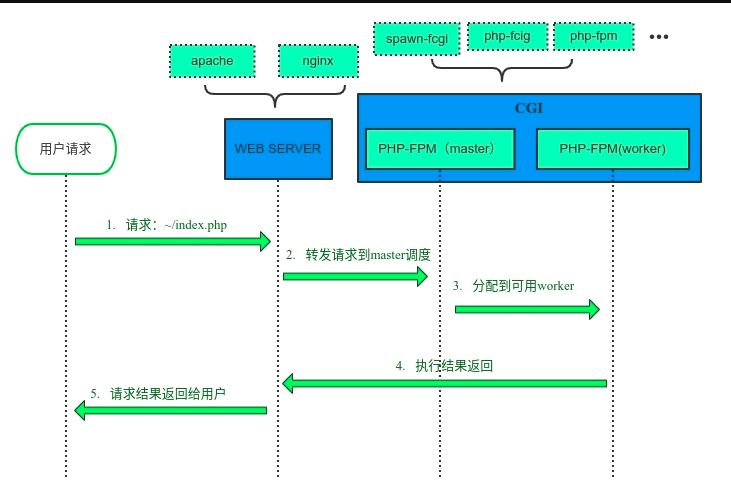
FPM(FastCGI 进程管理器)用于替换 PHP FastCGI 的大部分附加功能,管理PHP进程池。用于接受处理来自WEB服务器(nginx)的请求.
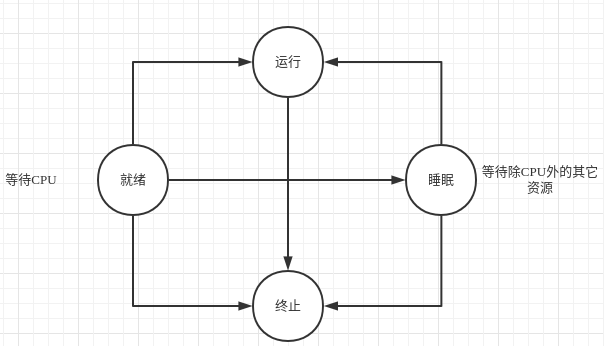
PHP-FPM会创建一个master进程用于管理work进程(fork或killwork进程)和转发请求。work进程会竞争的接受请求,接收成功后,解析FastCGI协议执行脚本,处理完成,等待下一个请求(同步阻塞IO)。
PHP-FPM 对于高并发的处理能力不强。高并发业务推荐使用swoole 或 workman相关生态。
配置项说明 官方文档
全局常用配置
#PID 文件的位置
pid = run/php-fpm.pid
#错误日志目录
error_log = log/php-fpm.log
#日志等级
log_level = warning
#用于设定平滑重启的间隔时间。这么做有助于解决加速器中共享内存的使用问题,可用单位:s(秒),m(分),h(小时)或者 d(天)
emergency_restart_interval = 60s
#如果子进程在 emergency_restart_interval 设定的时间内收到该参数设定进程数量的 SIGSEGV 或者 SIGBUS退出信息号,则FPM会重新启动;
emergency_restart_threshold = 30
#子进程接受主进程复用信号的超时时间
process_control_timeout = 5s
#设置 FPM 在后台运行。设置“no”将 FPM 保持在前台运行用于调试
daemonize = yesemergency_restart 配置解释,在60s内收到30个子进程的SIGSEGV或SIGBUS退出信号,则重启fpm
process_control_timeout场景,例如当父进程发送终止信号时,子进程正在处理某些事情的时候。十秒的时间,他们会有一个更好的机会完成任务并且优雅地退出
进程池相关配置
进程池监听配置
#进程池名称
[yangliuan]
#设置进程池接受 FastCGI 请求的地址,可用格式为:'ip:port','port','/path/to/unix/socket',每个进程池都要设置
listen = /dev/shm/php-cgi.sock
listen.backlog = -1
listen.allowed_clients = 127.0.0.1
listen.owner = yangliuan
listen.group = yangliuan
listen.mode = 0666
user = yangliuan
group = yangliuanTCP Socket 链接方式127.0.0.1:9000 ,可以跨机器通讯 ,使用 Nginx 做负载均衡做 PHP 服务器集群,应用服务器只需要安装php就可以了
Unix Socket 链接方式 /dev/shm/php-cgi.sock,只能本机通讯 ,Nginx 和 FPM 必须都在同一台服务器上,速度比较快而且消耗资源少(差距不会太大 0.1% ~ 5% 的差别),这种情况做集群的话,应用服务器需要同时安装nginx和php
/dev/shm 是linux tmpfs文件系统,数据存储和读取直接使用内存,速度快
对应nginx监听方式
fastcgi_pass 127.0.0.1:9000;
fastcgi_pass unix:/dev/shm/php-cgi.sock;进程池模式
fpm 的运行模式有三种:ondemand 按需创建,dynamic 动态创建,static 固定数量
ondemand
ondemand 初始化时不会创建待命的进程。并且会在空闲时将进程销毁,请求进来时再开启。是一种比较 节省内存 的 FPM 运行方式,不过因为其频繁创建和销毁进程,性能表现不佳。
应用场景:一般是在共享的 VPS 上使用。内存小的机器上。
相关参数
#秒数,多久之后结束空闲进程;默认是 10 秒,超过 10 秒即销毁
pm.process_idle_timeout = 10s
#最大并存进程数,超过此值将不再创建
pm.max_children = 50
#每个进程最多处理多少个请求,超过此值将自动销毁
pm.max_requests = 1000dynamic
动态创建,这个是默认选项,也是比较灵活的选项。兼顾稳定和快速响应。因为一直保证有「空闲进程」可供使用,所以 dynamic 的配置,相比 ondemand 进程要同时创建,响应速度还是比较快的。然而在还是避免不了频繁创建和销毁进程对系统造成的消耗
应用场景:一台服务器上跑多个php项目,平常访问量不多。
相关配置:
#FPM 启动时创建的进程数
pm.start_servers = 10
#最大并存进程数,超过此值将不再创建
pm.max_children = 50
#空闲进程数最小值,如果空闲进程小于此值,则创建新的子进程
pm.min_spare_servers = 10
#空闲进程数最大值,如果空闲进程大于此值,则进行清理
pm.max_spare_servers = 40
#每个进程最多处理多少个请求,超过此值将自动销毁
pm.max_requests = 1000dynamic模式 进程数量公式
处理请求中的进程数量 + pm.max_spare_servers = pm.max_children超过最大进程数后,新来的请求将会阻塞等待,php-fpm日志会出现 server reached pm.max_children setting (n), consider raising it 警告日志。n为配置的pm.max_children最大进程数值
static
固定进程数量是性能最好,省去了创建和销毁进程的开销,资源利用率最高的运行方式,一般在要求单机性能最高的时候使用
应用场景:PHP 服务器集群,希望每台机器都能物尽其用;本地lnmp开发环境,保证占用内存固定
相关配置:
#FPM 启动时创建的进程数,并且会一直保持这个数
pm.max_children = 50
#每个进程最多处理多少个请求,超过此值将自动销毁
pm.max_requests = 1000该模式需要计算评估一般场景下,每个进程占用多少内存,以及每台机器的总内存。然后根据情况配置。
使用ab压力测试工具或jmeter工具,对访问频率较高的页面和请求进行的正常流量情况下的压力测试。
然后使用如下命令进行统计,查看内存使用情况,单个php进程占用进程数
ps -eo size,pid,user,command --sort -size | awk '{ hr=$1/1024 ; printf("%13.2f Mb ",hr) } { for ( x=4 ; x<=NF ; x++ ) { printf("%s ",$x) } print "" }' | grep php-fpm要求不严谨的情况下,可以根据经验和项目的业务场景的代码对每个进程数进行粗略估算,例如一个常用接口查询请求下占用多少内存,然后在计算。
最大进程数量计算公式
pm.max_children = 可用内存 / 每个进程暂用内存大小可用内存不是本机所有内存,要除去其他程序运行,例如nginx,mysql,等其它服务的内存。
调试期间,要在生产环境中实战观察,一般建议使用 80% 的内存使用率,留 20% 给内存泄露的空间和其他软件运行。
最后是 pm.max_requests 值,需要我们观察应用是否有 内存泄漏。现代的 PHP 程序,尤其是 Laravel ,会依赖于非常多的扩展包,这些扩展包代码质量参差不齐,多少会出现内存泄漏的问题。如果内存泄露不严重,那么把值设置高一点,让单个进程在存活期间多处理一些请求,如果内存泄露比较严重,应当酌情设置低一点。否则会出现系统内存不够用,然后去使用 Swap 物理内存 的窘境。
如果代码质量非常高,不会出现发生内存泄露的情况,可以将其设置为 pm.max_requests=0 可以避免过高的 PM 开销
请求的生命周期设置
#设置单个请求的超时中止时间。该选项可能会对 php.ini 设置中的 'max_execution_time' 因为某些特殊原因没有中止运行的脚本有用
request_terminate_timeout = 600非分片上传大文件时,需要用到
请求慢日志设置
#当一个请求该设置的超时时间后,就会将对应的 PHP 调用堆栈信息完整写入到慢日志中,0关闭
request_slowlog_timeout = 60
#慢日志路径
slowlog = var/log/slow.log
#慢日志记录脚本堆栈的深度
request_slowlog_trace_depth = 20文件打开限制
#设置文件打开描述符的 rlimit 限制
rlimit_files = 51200
#设置核心 rlimit 最大限制值。可用值:'unlimited',0 或者正整数
rlimit_core = 0worker进程开启日志记录
catch_workers_output = yes参考