延期试用
rm -rf ~/.config/dconf ~/.config/navicat删除上述文件之前先备份连接,否则会丢失
重新运行程序之后,将连接导入
激活
1.使用第三方提供的程序包,和在线激活地址https://rlds.tk/
2. 手动编译激活
参考1 https://github.com/HeQuanX/navicat-keygen-tools/blob/linux/README.zh-CN.md
延期试用
rm -rf ~/.config/dconf ~/.config/navicat删除上述文件之前先备份连接,否则会丢失
重新运行程序之后,将连接导入
激活
1.使用第三方提供的程序包,和在线激活地址https://rlds.tk/
2. 手动编译激活
参考1 https://github.com/HeQuanX/navicat-keygen-tools/blob/linux/README.zh-CN.md
参考
《linux编程基础》
top 显示或管理执行中的程序
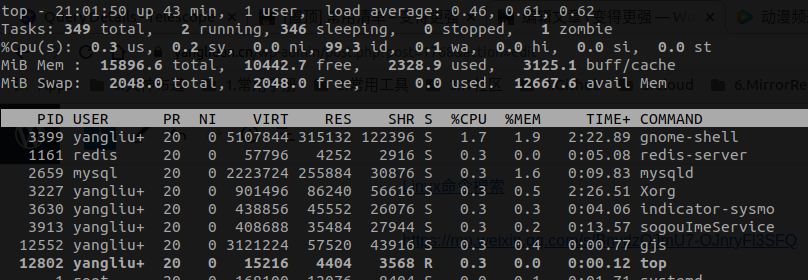
头部信息
| 显示项 | 说明 |
|---|---|
| top – 09:44:56 | 当前系统时间 |
| up 43 min | 系统已经运行时间43分钟 |
| 1 user | 当前登录用户数量 |
| load average: 0.24, 0.40, 0.53 | 三个数字对应1 分钟、5 分钟、15 分钟的平均负载 |
| 进程信息 | Tasks 第二行 |
| 349 total | 系统中的进程数量349个 |
| 2 running | 处于运行态的进程数量 |
| 346 sleeping | 处于睡眠态的进程数量 |
| 0 stopped | 处于停止态的进程数量 |
| 0 zombie | 处于僵尸态的进程数量 |
| CPU信息 | %Cpu(s) 第三行 |
| 0.3 us | 用户占用cpu百分比 us=user |
| 0.2 sy | 系统占用cpu百分比 sy=system |
| 0.0 ni | 用户进程空间内改变过优先级的进程占用cpu百分比 ni=nice |
| 99.3 id | 空闲进程占用cpu百分比 id=idle |
| 0.1 wa | 硬件设备I/O 等待占用 占用cpu百分比 wa=wait |
| 0.0 hi | 硬中断占用cpu百分比 hi=hardirq |
| 0.0 si | 软中断占用cpu百分比 si=softirq |
| 0.0 st | 虚拟机被hypervisior(虚拟监视器)偷去的时间所占的百分比 |
| 内存信息 | MiB(单位) Mem 第四行 |
| 15896.6 total | 物理内存总量 |
| 10442.7 free | 空闲内存总量 |
| 2328.9 used | 使用的物理内存总量 |
| 3125.1 buff/cache | 缓冲内存(缓存) 内存总量 |
| 交换分区信息(虚拟内存) | MiB(单位) Swap 第五行 |
| 2048.0 total | 交换区总容量 |
| 2048.0 free | 空闲交换区总容量 |
| 0.0 used | 使用的交换区总量 |
| 12667.6 avail Mem | 可用交换区总量 |
进程列表标题头
| 标题头 | 说明 |
|---|---|
| PID | 进程PID 进程的唯一标识 |
| USER | 进程的运行用户 |
| PR | 进程优先级 |
| NI | nice值用来控制进程优先级 对应nice命令操作 |
| VIRT | 虚拟内存大小,即进程使用的虚拟内存总量,单位为K |
| RES | 常驻内存及大小,即进程使用的违背换出的物理内存大小,单位为B |
| SHR | 共享内存大小,单位为KB |
| S | 进程状态 对应PS命令的中的STAT |
| %CPU | 上次更新到现在的CPU时间占用,默认按此值排序 |
| %MEM | 进程使用物理内存站总内存的百分比 |
| TIME | 进程占CPU的总时长,单位为1/100秒 |
快捷键
| 热键 | 说明 |
|---|---|
| M | 根据常驻内存集RES大小为进程排序 |
| P | 根据%CPU为进程排序 |
| T | 根据TIME + 为进程排序 |
| r | 重置一个进程的优先级 |
| i | 忽略限制和僵尸进程 |
| k | 终止一个进程 |
htop [非内部命令]一个互动的进程查看器,可以动态观察系统进程状况
top的升级版
ps 报告当前系统的进程状态
ps -aux| grep 进程名称 //查看指定名称的进程
ps -aux| grep php-fpm |wc -l //统计php-fpm进程数量pstree 以树状图的方式展现进程之间的派生关系
kill 发送信号到进程
kill -s 9 PID //杀死进程skill 向选定的进程发送信号冻结进程 用于向选定的进程发送信号,冻结进程。这个命令初学者并不常用,深入之后牵涉到系统服务优化之后可能会用到。
killall 使用进程的名称来杀死一组进程 我们可以使用kill命令杀死指定进程PID的进程,如果要找到我们需要杀死的进程,我们还需要在之前使用ps等命令再配合grep来查找进程,而killall把这两个过程合二为一,是一个很好用的命令。
pkill 可以按照进程名杀死进程 pkill和killall应用方法差不多,也是直接杀死运行中的程序;如果您想杀掉单个进程,请用kill来杀掉。
查看进程所在目录
ll /proc/{PID} //{PID}为进程pid进程启动管理
chkconfig 检查或设置系统的各种服务
systemctl 系统服务管理器systemd指令
strace 是一个集诊断、调试、统计与一体的工具
https://help.aliyun.com/noticelist/articleid/1060782748.html
2021年1月13日,阿里云应急响应中心监控到国外某安全研究团队披露了Laravel <= 8.4.2 存在远程代码执行漏洞。
漏洞描述
Laravel 是一个免费的开源 PHP Web 框架,旨在实现的Web软件的MVC架构。2021年1月13日,阿里云应急响应中心监控到国外某安全研究团队披露了 Laravel <= 8.4.2 存在远程代码执行漏洞。当Laravel开启了Debug模式时,由于Laravel自带的Ignition功能的某些接口存在过滤不严,攻击者可以发起恶意请求,通过构造恶意Log文件等方式触发Phar反序列化,从而造成远程代码执行,控制服务器。漏洞细节已在互联网公开。阿里云应急响应中心提醒 Laravel 用户尽快采取安全措施阻止漏洞攻击。
影响版本
Laravel 框架 < 8.4.3
facade ignition 组件 < 2.5.2
安全版本
Laravel 框架 >= 8.4.3
facade ignition 组件 >= 2.5.2
安全建议
建议将 Laravel 框架升级至8.4.3及其以上版本,或者将 facade ignition组件升级至 2.5.2 及其以上版本。
相关链接
客户项目故障,查看日志报错空间不足,通知有两种情况,1.磁盘空间占满2.磁盘inode节点被占满

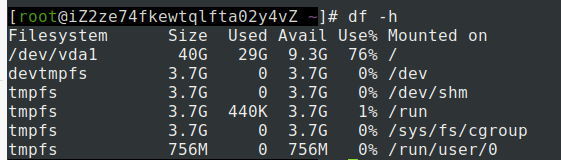
df -h 查看磁盘使用率
df -i 查看inode节点使用率
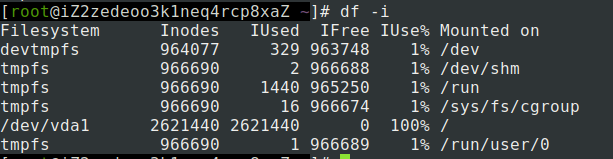
查看当前目录下的文件数量(不包含子目录中的文件)
ls -l|grep "^-"| wc -l查看当前目录下的文件数量(包含子目录中的文件) 注意:R,代表子目录
ls -lR|grep "^-"| wc -l查看当前目录下的文件夹目录个数(不包含子目录中的目录),同上述理,如果需要查看子目录的,加上R
ls -l|grep "^d"| wc -l查询当前路径下的指定前缀名的目录下的所有文件数量
ls -lR 20210101*/|grep "^-"| wc -l统计当前目录下log文件数量
find ~ -name "*.log"|wc -l修改语言为中文
参考
https://jmeter.apache.org/usermanual/properties_reference.html#language
bin目录下jmeter.properties文件
language=zh_CN
关闭日志文件
bin目录下log4j2.xml 日志配置文件,将filename改成空则不再自动home根目录下创建jmeter.log

测试计划处可以添加全局变量
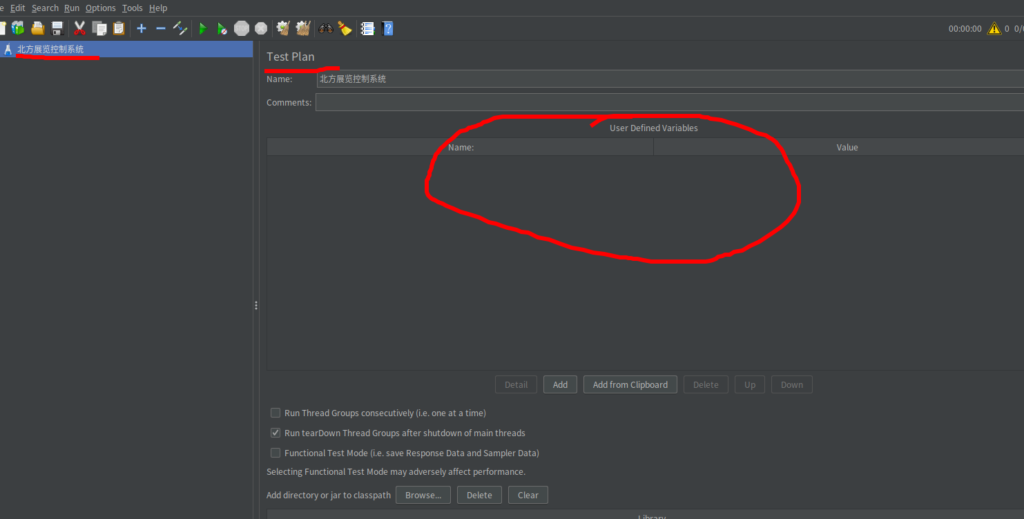
左侧树状图中齿轮状的节点称为『线程组』(Thread Group),灰色的是被禁用状态。默认情况下各个线程组的执行是相互独立并且是并行执行的,我们勾选了 Run Thread Groups consecutively 使其变成依次执行:
添加线程组

相关文章
Jmeter(一) – 从入门到精通 – 环境搭建(详解教程)
Jmeter(二) – 从入门到精通 – 创建测试计划(Test Plan)(详解教程)
Jmeter(三) – 从入门到精通 – 测试计划(Test Plan)的元件(详解教程)
Jmeter(四) – 从入门到精通 – 创建网络测试计划(详解教程)
Jmeter(五) – 从入门到精通 – 创建网络计划实战和创建高级Web测试计划(详解教程)
Jmeter(六) – 从入门到精通 – 建立数据库测试计划(详解教程)
Jmeter(七) – 从入门到精通 – 建立数据库测试计划实战<MySQL数据库>(详解教程)
Jmeter(八) – 从入门到精通 – JMeter配置元件(详解教程)
Jmeter(九) – 从入门到精通 – JMeter逻辑控制器 – 上篇(详解教程)
Jmeter(十) – 从入门到精通 – JMeter逻辑控制器 – 中篇(详解教程)
Jmeter(十一) – 从入门到精通 – JMeter逻辑控制器 – 下篇(详解教程)
Jmeter(十二) – 从入门到精通 – JMeter逻辑控制器 – 终篇(详解教程)
Jmeter(十三) – 从入门到精通 – JMeter定时器 – 上篇(详解教程)
Jmeter(十四) – 从入门到精通 – JMeter定时器 – 下篇(详解教程)
Jmeter(十五) – 从入门到精通 – JMeter导入自定义的Jar包(详解教程)
Jmeter(十六) – 从入门到精通 – JMeter前置处理器(详解教程)
Jmeter(十七) – 从入门到精通 – JMeter后置处理器 -上篇(详解教程)
Jmeter(十八) – 从入门到精通 – JMeter后置处理器 -下篇(详解教程)
Jmeter(十九) – 从入门到精通 – JMeter监听器 -上篇(详解教程)
Jmeter(二十) – 从入门到精通 – JMeter监听器 -下篇(详解教程)
Jmeter(二十一) – 从入门到精通 – JMeter断言 – 上篇(详解教程)
Jmeter(二十三) – 从入门到精通 – JMeter函数 – 上篇(详解教程)
Jmeter(二十四) – 从入门到精通 – JMeter函数 – 中篇(详解教程)
Jmeter(二十五) – 从入门到精通 – JMeter函数 – 下篇(详解教程)
Jmeter(二十六) – 从入门到精通 – 搭建开源论坛JForum(详解教程)
Jmeter(二十七) – 从入门到精通 – Jmeter Http协议录制脚本(详解教程)
Jmeter(二十八) – 从入门到精通 – Jmeter Http协议录制脚本工具-Badboy1(详解教程)
Jmeter(二十九) – 从入门到精通 – Jmeter Http协议录制脚本工具-Badboy2(详解教程)
Jmeter(三十) – 从入门到精通 – Jmeter Http协议录制脚本工具-Badboy3(详解教程)
Jmeter(三十) – 从入门到精通 – Jmeter Http协议录制脚本工具-Badboy3(详解教程)
Jmeter(三十一) – 从入门到精通 – Jmeter Http协议录制脚本工具-Badboy4(详解教程)
Jmeter(三十二) – 从入门到精通 – Jmeter Http协议录制脚本工具-Badboy5(详解教程)
Jmeter(三十三) – 从入门到精通 – Jmeter Http协议录制脚本工具-Badboy6(详解教程)
Jmeter(三十四) – 从入门到精通进阶篇 – 参数化(详解教程)
Jmeter(三十五) – 从入门到精通进阶篇 – 关联(详解教程)
Jmeter(三十六) – 从入门到精通进阶篇 – 设置负载阶梯式压测场景(详解教程)
Jmeter(三十七) – 从入门到精通进阶篇 – 输出HTML格式的性能测试报告(详解教程)
Jmeter(三十八) – 从入门到精通进阶篇 – 命令行运行JMeter详解(详解教程)
Jmeter(三十九) – 从入门到精通进阶篇 – Jmeter配置文件的刨根问底 – 上篇(详解教程)
Jmeter(四十) – 从入门到精通进阶篇 – Jmeter配置文件的刨根问底 – 中篇(详解教程)
Jmeter(四十一) – 从入门到精通进阶篇 – Jmeter配置文件的刨根问底 – 下篇(详解教程)
Jmeter(四十二) – 从入门到精通进阶篇 – Jmeter配置文件的刨根问底 -番外篇(详解教程)
Jmeter(四十三) – 从入门到精通高级篇 – Jmeter之IP伪装和欺骗(详解教程)
Jmeter(四十四) – 从入门到精通高级篇 – Jmeter远程启动(本地运行+远程运行)(详解教程)
Jmeter(四十五) – 从入门到精通高级篇 – Jmeter之网页爬虫-上篇(详解教程)
Jmeter(四十六) – 从入门到精通高级篇 – Jmeter之网页图片爬虫-下篇(详解教程)
Jmeter(四十七) – 从入门到精通高级篇 – 分布式压测部署之负载机的设置(详解教程)
Jmeter(四十八) – 从入门到精通高级篇 – Jmeter监控服务器性能(详解教程)
Jmeter(四十九) – 从入门到精通高级篇 – jmeter使用监视器结果监控tomcat性能(详解教程)
Laravel电商教程进阶 – 压力测试
参考
概念
磁盘文件系统 操作磁盘,存储文件
闪存文件系统 操作移动设备,存储文件
数据库文件系统
文件管理方面的一个新概念是一种基于数据库的文件系统的概念。不再(或者不仅仅)使用分层结构管理,文件按照他们的特征进行区分,如文件类型、专题、作者或者亚数据进行区分。于是文件检索就可以按照SQL风格甚至自然语言风格进行。例如BFS[1]和WinFS。
网络文件系统
NFS,Network File System是一种将远程主机上的分区(目录)经网络挂载到本地系统的一种机制
常见文件系统介绍
RAW文件系统是一种磁盘未经处理或者未经格式化产生的文件系统,最快的方法是立即格式化
FAT32
NTFS
centos安装ntfs支持
centos7 unix系统哲学一切都是文件
linux 设备和文件目录
| 设备 | 设备在Linux中的文件名 |
| IDE硬盘 | /dev/hd[a-d] |
| SCS/SATA/USB硬盘 | /dev/sd[a-p] |
| U盘 | /dev/sd/[a-p] 与SATA相同 |
| 软驱 | /dev/fd[0-1] |
| 打印机 | 25针:/dev/ip[0-2] USB:/dev/usb/lp[0-15] |
| 鼠标 | USB:/dev/usb/mouse[0-15] PS2:/dev/psaux |
| 当前CD ROM/DVD ROM | /dev/cdrom |
| 当前鼠标 | /dev/mouse |
| 磁带机 | IDE:/dev/ht0 SCSI:/dev/st0 |
| 目录 | 说明 |
| / | 根目录,zhhibaohao只包含目录不包含具体文件 |
| /bin | 存放可执行文件 |
| /dev | 存放设备文件 |
| /root | root用户的工作目录 |
| /home | 普通用户的工作目录 |
| /lib | 存放动态链接库文件,类似于Win的dll,一般以SO结尾;也存放与内核相关的文件 |
| /boot | 启动时用到的文件,内核,引导程序 |
| /etc | 系统管理文件,配置文件 |
| /mnt | 挂载存储设备的挂载目录 |
| /proc | 系统内存映射直接通过访问目录获取系统信息 |
| /opt | 附加应用目录 |
| /tmp | 存放临时文件系统重启后不会保存 |
| /swp | 虚拟内存交换文件 |
| /usr | 用户程序/usr/bin 库文件/usr/lib 文档/usr/share/doc |
参考
字符编码笔记:ASCII,Unicode 和 UTF-8 ——阮一峰
字符编码详解(基础) ——PHP鸟哥
字节(Byte或byte):计算机系统中用于计量存储容量的一种计量单位, 1B=8bit
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等,但是一个字符在计算机中占用多少字节是与编码方式有关的,不同的编码方式占用的内存不一样。例如:标点符号+是一个字符,汉字我们是两个字符,在GBK编码中一个汉字占2个字节,在UTF-8编码中一个汉字占3个字节。
mysql(utf8mb4编码)中varchar(255) 255是字符长度不需要考虑不同字符(中文,英文)字节占用问题这是mysql底层处理的
字节和字符有什么联系和区别呢?简单来说字节是计算机存储和操作的最小单位,字符是人们阅读的最小单位;字节是存储(物理)概念,字符是逻辑概念;字节代表数据(内涵和本质),字符代表其含义;字符由字节组成。
举几个例子说明两者区别:“中国”包含2个字符,GBK编码表示需要4个字节,UTF-8编码需要6个字节;数字“1234567890”,包含10个字符,用int32类型表示只需4个字节
编码规范 随着计算机的普及,人们希望能在计算机中显示字符,但是计算机只能显示0和1这样的二进制数,为了显示字符,国际组织就制定了编码规范,希望使用不同的二进制数来表示代表不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。所谓字符集其实就是一套编码规范中的子概念,所以我们通常就称呼其为XX编码,XX字符集。例如:GBK 编码规范,根据这套编码规范,计算机就可以在中文字符和二进制数之间相互转换。而使用GBK编码就可以使计算机显示中文字符。
字库表 一套编码规范不一定包含世界上所有的字符,每套编码规范都有自己的使用场景,而字库表就存储了某种编码规范中能显示的所有字符,计算机就是根据二进制数从字库表中找到与之对应的字符然后显示给用户的,字库表相当于一个存储字符的数据库。例如:几乎所有汉字都保存在GBK 编码规范的字库表中。所以可以显示汉字,但法语,俄语并不在其字库表中,所以使用GBK编码的文档不能正常显示法语,俄语等不包含在其字库表中的字符。
编码字符集(字符集)在一个字库表中,每一个字符都有一个对应的二进制地址,而编码字符集就是这些地址的集合。字符集定义了字符和二进制的对应关系,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。
字符编码(编码方式 )而字符编码规定了如何将字符的编号存储到计算机中,如果使用了类似 GB2312 和 GBK 的变长存储方案(不同的字符占用的字节数不一样),那么为了区分一个字符到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码。
字符集和字符编码的关系
通常特定的字符集采用特定的编码方式(即一种字符集对应一种字符编码(例如:ASCII、IOS-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码,但Unicode不是,它采用现代的模型)),因此基本上可以将两者视为同义词
字符和字符编码的异同可参见:https://www.cnblogs.com/lanhaicode/p/11214827.html
粗略总结
常见的编码规范及其发展过程
单字节
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码),是最早产生的编码规范,共128个字符,用7位二进制表示(00000000-01111111即0x00-0x7F),可以看出ASCII码只需要1个字节的存储空间,它没有特定的编码方式,直接使用地址对应的二进制数来表示,非要说那就叫他ASCII 编码方式。可以表示阿拉伯数字和大小写英文字母,以及一些简单的符号。
EASCII(Extended ASCII),256个字符,用8位二进制表示(00000000-11111111即0x00-0xFF)。当计算机传到了欧洲,国际标准化组织在ASCII的基础上进行了扩展,形成了ISO-8859标准,跟EASCII类似,兼容ASCII,在高128个码位上有所区别。ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性
MySQL数据库默认编码是Latin1就是利用了这个特性。ASCII编码是一个7位的容器,ISO-8859-1编码是一个8位的容器。由此可见,ISO-8859-1只占1个字节,且MySQL数据库默认编码就是ISO-8859-1,有时,tomcat服务器默认也是使用ISO-8859-1编码,然而ISO-8859-1是不支持中文的,有时这就是在浏览器上显示乱码的原因。但是由于欧洲的语言环境十分复杂,所以根据各地区的语言又形成了很多子标准,ISO-8859-1、ISO-8859-2、ISO-8859-3、……、ISO-8859-16。
双字节
当计算机传到了亚洲,256个码位就不够用了。于是乎继续扩大二维表,单字节改双字节,16位二进制数,65536个码位。在不同国家和地区又出现了很多编码,中国的GB2312、港台的BIG5、日本的Shift JIS,韩国的Euc-kr等等。
一般在国内,汉字较多时使用。GBK(Chinese Internal Code Specification)是GB2312的扩展,GBK 向下与 GB 2312 编码兼容,向上支持 ISO 10646.1国际标准,是前者向后者过渡过程中的一个承上启下的产物。ISO 10646 是国际化标准组织 ISO 公布的一个编码标准,即 Universal Multilpe-Octet Coded Character Set(简称UCS),与 Unicode 组织的 Unicode 编码完全兼容。
GBK全称《汉字内码扩展规范》,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字。GBK字符集中所有字符占2个字节,不论中文英文都是2个字节。 没有特殊的编码方式,习惯称呼GBK 编码。
GBK编码,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。
多字节
当互联网席卷了全球,地域限制被打破了,不同国家和地区的计算机在交换数据的过程中,由于之前出现的各种不同的编码方式,文本就会出现乱码的问题,即对同一组二进制数据,不同的编码会解析出不同的字符。而当某个字符集中没有文本中的字符编码时,就会出现乱码。
通用字符集UCS(Universal Character Set)对应两种编码:对每一个字符采用四个8比特字节编码的称为UCS-4,对每一个字符采用两个8比特字节编码的称为UCS-2。
Unicode字符集的出现就是为了解决这个问题。Unicode 是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。2)Unicode 在很长一段时间内无法推广
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
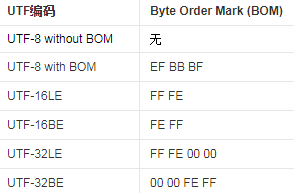
BOM
BOM(字节顺序标记, byte-order mark)也是我们常见到的名词, 比如我们的代码文件都要求使用UTF-8无BOM形式保存, 不然有可能编译不过, 或者出现一些诡异的事情.
BOM实际上是位于码位U+FEFF的Unicode字符的名称.
对于UTF-16, UCS-2, UTF-32 / UCS-4这类码元不是8位的编码方式来说, 编码后的数据要存储/传输时, 必然会有字节序的问题, BOM出现在字节流的开头, 则用于标识该字节流的字节序. 各编码方案按自己的方式对U+FEFF进行编码, 放在头部即可标志编码该字节流时使用的字节序.
比如, 当我们知道即将读取的字节流以UTF-16编码, 字节序未知, 读到的前两个字节是0xFF, 0xFE, Unicode中U+FFFE则不映射到字符, 而这两个字节必定是编码的U+FEFF, 因此可以判断当前字节流使用小端序, 即UTF-16 LE
对于UTF-8, 由于它使用的是8位的码元, 不存在字节序的问题, 也不建议在头部添加BOM, 因为可能影响到一些工具, 因此使用无BOM的UTF-8成了主流.
ANSI
ANSI全称(American National Standard Institite)美国国家标准学会(美国的一个非营利组织),首先ANSI不是指的一种特定的编码,而是不同地区扩展编码方式的统称,各个国家和地区所独立制定的兼容ASCII,但互相不兼容的字符编码,微软统称为ANSI编码

总结对照
常用的字符编码ASCII,GBK,GB2312,BIG5,UTF-8 英文和中文简繁
Unicode字符集的编码方式有UTF-8,UTF-16,UTF-32
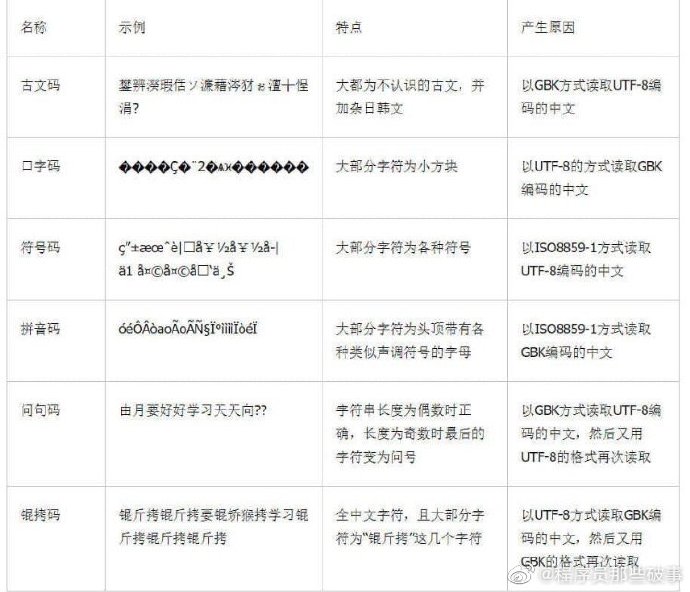
中文乱码产生的原因
PHP获取中文的第一个字符
//多字节字符串 PHP文件编码为UTF-8
$str = '你好PHP';
var_dump($str[0]); //输出结果 b"ä",乱码
var_dump(substr($str, 0, 1));//输出结果 b"ä",乱码
var_dump(substr($str, 0, 3));//输出结果 你 ,utf-8编码中一个汉字是三个字节
var_dump(mb_substr($str, 0, 1));//输出结果 你PHP处理字符串的方式默认是把字符串作为单字节字符处理的,例如数组方式取字符和普通字符串函数
PHP处理多字节字符串需要用这些扩展 国际化与字符编码支持 常用的有mbstring 扩展和 iconv 函数
mbstring扩展支持的编码 https://www.php.net/manual/zh/mbstring.supported-encodings.php
iconv_get_encoding 获取 iconv 扩展的内部配置变量,
文本文件和二进制的区别
文本文件是二进制文件的一种,底层存储也是0和1;文本文件可读性和移植性好,但表现字符有限;二进制文件数据存储紧凑,无字符编码限制。文本文件基本上只能存放数字、文字、标点等有限字符组成的内容;二进制没有字符约束,可随意存储图像、音视频等数据。
用存储数字的例子可以形象的看出文本文件和二进制文件存储内容上的差异。例如要存储数字1234567890,文本文件要存储0-9这十个数字的ASCII码,对应的十六进制表示为:31 32 33 34 35 36 37 38 39 30,占用10个字节;1234567890对应的二进制为“0100 1001 1001 0110 0000 0010 1101 0010”,占用4个字节(二进制表示32位,一个字节8位),存储到文件的16进制表示为(大端):49 96 02 D2。
文本文件按字符存放内容,二进制按字节存放,这是两种文件最本质的区别。根据这个特性,可以推断出一些常见结论:二进制文件常常比文本文件紧凑,占用空间少;文本文件更友好易用,能用所见即所得的方式编辑;二进制文件常常需要专用程序打开,等等。
回过头看文本编辑器打开二进制文件常常是乱码的现象。例如一个二进制文件存放了一个整数1234(四个字节),用16进制表示为:00 00 04 D2。文本编辑器打开后逐个字符解释,会发现这几个字节拼不出可显示的字符,只好乱码相待。乱码的原因是文本编辑器不能正确解析字节流,这也是二进制文件需要用专用软件打开的原因。例如jpg文件要用看图软件打开,如果用音乐播放器打开,完蛋!视频文件要用播放器打开,用压缩软件打开,歇菜!有的专用软件会做处理打开不支持的格式后不做反应,有的会报错。
文件格式
Windows按文件拓展名识别文件格式,并调用对应的程序打开文件;
(类)Unix系统,拓展名可有可无,有file命令,这个命令可以告诉我们文件到底是什么格式文件拓展名不是文件格式的本质区别,内容才是。把a.zip改成a.txt/a.jgp/a.mp3,无论什么文件名,file都让其原形毕露:Zip archive data, at least v1.0 to extract。file命令的工作原理可这篇文章。
PHP读取txt文本文件获取第一个字符乱码
参考
有一个ASCII的编码的文本文件,在linux上打开会显示乱码,因此使用windows记事本打开转成了UTF-8编码,然后用php读取该文本文件第一个字符时出现乱码,原因是windows记事本保存文件时会给文本文件增加bom头。
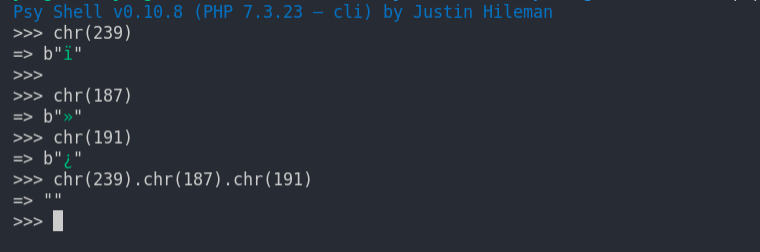
php检测处理bom头的原理,就是用ord函数检测前三个字符在ASCII编码中的数字是否为239,187,191
if (ord($contents[0]) === 239 && ord($contents[1]) === 187 && ord($contents[2]) == 191)
{
$contents = substr($contents, 3);
var_dump($contents[0]);
}对应的字符如下
用户的操作系统类型是不确定,因此文本文件的字符编码也无法确定 ,需要对用户上传的文本文件转换字符编码
$fileContents = file_get_contents($path);//读取文件字符串,此处可以用框架方法替代
$encoding = mb_detect_encoding($fileContent, ['ASCII', 'GBK', 'GB2312', 'BIG5', 'UTF-8']);//获取文件内容编码
$fileContent = mb_convert_encoding($fileContent, 'UTF-8', $encoding);//转码
//$contents = iconv($encoding, 'UTF-8', $contents);//iconv也可以前置知识
接口站点 nginx 配置 添加请求头 和 自动响应
#表示允许这个域跨域调用(客户端发送请求的域名和端口)
#$http_origin动态获取请求客户端请求的域,不用*的原因是带cookie的请求不支持*号
add_header Access-Control-Allow-Origin $http_origin;
#表示请求头的字段 动态获取
add_header Access-Control-Allow-Headers $http_access_control_request_headers;
#指定允许跨域的方法,* 代表所有
add_header Access-Control-Allow-Methods "GET,POST,PUT,PATCH,DELETE,OPTIONS";
#带cookie请求需要加上这个字段,并设置为true
add_header Access-Control-Allow-Credentials true;
#预检命令的缓存,如果不缓存每次会发送两次请求 单位s
add_header Access-Control-Max-Age 3600;
#自动响应options请求
if ($request_method = OPTIONS){
return 204;
}页面站点 nginx 配置 使用反向代理请求接口
通过代理将页面站点和接口站点变成同域
前置条件:页面的路由不能和接口路由存在冲突,否则路由无法代理到接口
ex: 所有接口的前缀都是/api 且页面路由中不存在 /api前缀
location = /api {
proxy_pass http://apihost;
}PHP响应增加请求头
此方法也可用于不支持自动跨域php框架,在框架入口文件 或者 路由文件 最上方增加 header
header("Access-Control-Allow-Origin: *"); //允许请求来源
header("Access-Control-Allow-Credentials : true"); //允许携带cookies
header("Access-Control-Allow-Headers: *");//允许请求头
header("Access-Control-Allow-Methods: GET,POST,PUT,PATCH,DELETE,OPTIONS");//允许请求方法
header("Access-Control-Max-Age: 3600");//预检请求缓存时间Laravel 框架
laravel 7.0 以后版本 官方集成了 laravel-cors 扩展包 文档
return [
'paths' => ['api/*', 'sanctum/csrf-cookie'], //触发cors的路由前缀
'allowed_methods' => ['*'],//允许请求方法
'allowed_origins' => ['*'], //允许请求来源
'allowed_origins_patterns' => [],//允许请求来源,正则表达式匹配
'allowed_headers' => ['*'], //允许请求头
'exposed_headers' => [], //排除的请求头
'max_age' => 0, //预检请求缓存时间
'supports_credentials' => false, //是否允许携带cookie
];参考
laravel 的单元测试(tests/Unit目录下),不支持很多内置函数,适合测试不依赖laravel方法的独立方法。
否则会报错,例如在一个job中引用了config(‘xxxx’),执行test时会报错。

将测试方法放到tests/Feature 中,运行成功,因此laravel unit测试里的方法适合独立的自定义方法,并且没有依赖laravel本身的方法。
