阅读原文 转自博客园 知行思新
引言:前文(数据库设计Step by Step (9)——ER-to-SQL转化)讨论了如何把ER图转化为关系表结构。本文将介绍数据库范式并讨论如何范式化候选表。我们先来看一下此刻处在数据库生命周期中的位置(如下图所示)。
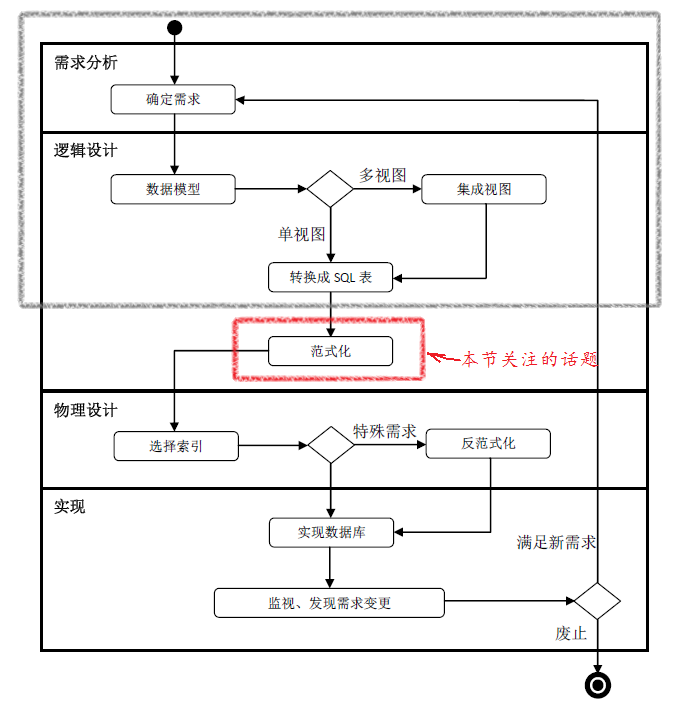
前几篇博文中我们详细的讨论了ER建模的方法。精心设计的ER模型将帮助我们直接得到范式化的表或只需稍许修改即为范式化的表,设计、绘制ER图的重要性也体现在这里。概念数据建模(ER建模)从一开始就潜移默化的引导着我们走向范式化的数据库表结构。
本文的讨论将始于第一范式,止于BCNF范式。在现实数据库设计中,一般需达到的范式化目标是第三或BCNF范式,更高级别的范式更多的是理论价值,本文也不将涉及。

范式基础
关系数据库中的表有时会面对性能、一致性和可维护性方面的问题。举例来说,把整个数据库中的数据都定义在一张表中将导致大量冗余的数据,低效的查询和更新性能,对某些数据的删除将造成有用数据的丢失等。如图1所示,products, salespersons, customers, orders都存储在一张名为Sales的表中。
| product_name | order_no | cust_name | cust_addr | credit | date | sales_name |
| vacuum cleaner | 1435 | Dave | Austin | 6 | 2010-03-01 | Carl |
| computer | 2730 | Qiang | Plymouth | 10 | 2011-04-15 | Ted |
| refrigerator | 2460 | Mike | Ann Arbor | 8 | 2010-09-12 | Dick |
| DVD player | 519 | Peter | Detroit | 3 | 2010-12-05 | Fred |
| radio | 1986 | Charles | Chicago | 7 | 2011-05-10 | Richard |
| CD player | 1817 | Eric | Mumbai | 8 | 2010-08-03 | Paul |
| vacuum cleaner | 1865 | Charles | Chicago | 7 | 2010-10-01 | Carl |
| vacuum cleaner | 1885 | Betsy | Detroit | 8 | 2009-04-19 | Carl |
| refrigerator | 1943 | Dave | Austin | 6 | 2011-01-04 | Dick |
| television | 2315 | Sakti | East Lansing | 6 | 2011-03-15 | Fred |
(图1 Sales表)
在这张表中,某些产品和客户信息是冗余的,浪费了存储空间。某些查询如“上个月哪些客户订购了吸尘器”需要搜索整张表。当要修改客户Dave的地址需要更新该表的多条记录。最后删除客户Qiang的订单(2730)将造成该客户姓名、地址、信用级别信息的丢失,因为该客户只有唯一这个订单。
如果我们通过一些方法把该大表拆分成多个小表,从而消除上述这些问题使数据库更为高效和可靠,范式化就是为了达到这一目标。范式化是指通过分析表中各属性之间的互相依赖,并把大表映射为多个小表的过程。
第一范式(1NF)
定义:当且仅当一张表的所有列只包含原子值时,即表中每行中的每一个列只有一个值,则该表符合第一范式。
图1中的Sales表的每一行、每一列中只有原子值,故Sales表满足第一范式。
为了更好的理解第一范式,我们讨论一下域、属性、列之间的差异。
域是某属性所有可能值的集合,但同一个域可能被用于多个属性上。举例来说,人名的域包含所有可能的姓名集合,在图1的表中可用于cust_name或sales_name属性。每一列代表一个属性,有些情况下代表不同属性的多个列具有相同的域,这并不会违反第一范式,因为表中的值仍是原子的。
仅符合第一范式的表常会遇到数据重复、更新性能以及更新一致性等问题。为了更好的理解这些问题,我们必须定义键的概念。
超键是一个或多个属性的集合,其能帮助我们唯一确定一条记录。若组成超键属性列的子集仍为一个超键,但该子集少了任何一个属性都将使其不再是一个超键,则该属性列子集称为候选键。主键是从一张表的候选键集合中任意挑选出的,作为该表的一个索引。
作为一个例子,图2中表的所有属性组成一个超键。
| report_no | editor | dept_no | dept_name | dept_addr | author_id | author_name | author_addr |
| 4216 | woolf | 15 | design | argus1 | 53 | mantei | cs-tor |
| 4216 | woolf | 15 | design | argus1 | 44 | bolton | mathrev |
| 4216 | woolf | 15 | design | argus1 | 71 | koenig | mathrev |
| 5789 | koenig | 27 | analysis | argus2 | 26 | fry | folkstone |
| 5789 | koenig | 27 | analysis | argus2 | 38 | umar | prise |
| 5789 | koenig | 27 | analysis | argus2 | 71 | koenig | mathrev |
(图2 Report表)
在关系模型中不允许有重复的行,因此一个明显的超键是表的所有列(属性)的组合。假设表中每一个部门的地址(dept_addr)都相同,则除dept_addr之外的属性仍然是一个超键。对其他属性作类似的假设,逐步缩小属性的组合。我们发现属性组合report_no, author_id能唯一确定表中的其他属性,即是一个超键。同时report_no或author_id中的任意一个都无法唯一确定表中的一行,故属性组合report_no, author_id是一个候选键。由于它们是该表的唯一候选键,它们也是该表的主键。
一张表能有多个候选键。举例来说,在图2中,若有附加列author_ssn(SSN:社会保险号),属性组合report_no, author_ssn也能唯一确定表中的其他属性。因此属性组合(report_no, author_id)和(report_no, author_ssn)都是候选键,可以任选其一作为主键。
第二范式(2NF)
为了解释第二以及更高级别范式。我们需引入函数依赖的概念。一个或多个属性值能唯一确定一个或多个其他属性值称为函数依赖。给定某表(R),一组属性(B)函数依赖于另一组属性(A),即在任意时刻每个A值只与唯一的B值相关联。这一函数依赖用A –> B表示。以图2中的表为例,表report的函数依赖如下:
report: report_no –> editor, dept_no
dept_no –> dept_name, dept_addr
author_id –> author_name, author_addr
定义:一张表满足第二范式(2NF)的条件是当且仅当该表满足第一范式且每个非键属性完全依赖于主键。当一个属性出现在函数依赖式的右端,且函数依赖式的左端为表的主键或可由主键传递派生出的属性组,则该属性完全依赖于主键。
report表中一个传递函数依赖的例子:
report_no –> dept_no
dept_no –> dept_name
因为我们能派生出函数依赖(report_no –> dept_name),即dept_name传递依赖于report_no。
继续我们的例子,图2中表的复合键(report_no, author_id)是唯一的候选键,即为表的主键。该表存在一个FD(dept_no –> dept_name, dept_addr),其左端没有主键的任何组成部分。该表的另两个FD(report_no –> editor, dept_no和author_id –> author_name, author_addr)的左端包含主键的一部分但不是全部。故report表的任何一条FD都不满足第二范式的条件。
思考一下仅满足第一范式的report表的缺陷。report_no, editor和dept_no对该Report的每一位author都需要重复,故当Report的editor需要变更时,多条记录必须同步修改。这就是所谓的更新异常(update anomaly),冗余的更新会降低性能。当没有把所有符合条件的记录同步更新时,还会造成数据的不一致。若要在表中加入一位新的author,只有在该author参与了某Report的撰写才能插入该author的记录,这就是所谓的插入异常(insert anomaly)。最后,若某一张Report无效了,所有与该Report相关联的记录必须一起删除。这可能造成author信息的丢失(与该Report相关联的author_id, author_name, author_addr也被删除了)。这一副作用被称为删除异常(delete anomaly),使数据丧失了完整性。
上述这些缺陷可通过把仅满足第一范式的表转化为多张满足第二范式的表来克服。在保留原先函数依赖和语义关系的前提下,把Report表映射为三张小表(report1, report2, report3),其中包含的数据如图3所示。
Report 1
| report_no | editor | dept_no | dept_name | dept_addr |
| 4216 | woolf | 15 | design | argus 1 |
| 5789 | koenig | 27 | analysis | argus 2 |
Report 2
| author_id | author_name | author_addr |
| 53 | mantei | cs-tor |
| 44 | bolton | mathrev |
| 71 | koenig | mathrev |
| 26 | fry | folkstone |
| 38 | umar | prise |
| 71 | koenig | mathrev |
Report 3
| report_no | author_id |
| 4216 | 53 |
| 4216 | 44 |
| 4216 | 71 |
| 5789 | 26 |
| 5789 | 38 |
| 5789 | 71 |
(图3 2NF表)
这些满足第二范式表的函数依赖为:
report1: report_no –> editor, dept_no
dept_no –> dept_name, dept_addr
report2: author_id –> author_name, author_addr
report3: report_no, author_id为候选键,无函数依赖
现在我们已得到了三张满足第二范式的表,消除了第一范式表存在的最糟糕的问题。第一、editor, dept_no, dept_name, dept_addr不再需要为每一位author重复。第二、更改一位editor只需要更新report1的一条记录。第三、删除report不再会造成author信息丢失的副作用。
我们可以注意到这三张满足第二范式的表可以直接从ER图转化得到。ER图中的Author、Report实体以及之间的“多对多”关系可根据上一篇博文(数据库设计Step by Step (9)——ER-to-SQL转化)的规则很自然的转化为三张表。
第三范式(3NF)
第二范式相对于第一范式已经有了巨大的进步,但由于存在传递依赖(transitive dependency),满足第二范式的表仍会存在数据操作异常(anomaly)。当一张表中存在传递依赖,其意味着该表中描述了两个单独的事实。每个事实对应于一条函数依赖,函数依赖的左侧各不相同。举例来说,删除一个report,其包含删除report1和report3表中的相应记录(如图3所示),该删除动作的副作用是dept_no, dept_name, dept_addr信息也被删除了。如果把表report1映射为包含列report_no, editor, dept_no的表report11和包含列dept_no, dept_name, dept_addr的表report12(如图4所示),我们就能消除上述问题。
Report11
| report_no | editor | dept_no |
| 4216 | woolf | 15 |
| 5789 | koenig | 27 |
Report12
| dept_no | dept_name | dept_addr |
| 15 | design | argus 1 |
| 27 | analysis | argus 2 |
Report 2
| author_id | author_name | author_addr |
| 53 | mantei | cs-tor |
| 44 | bolton | mathrev |
| 71 | koenig | mathrev |
| 26 | fry | folkstone |
| 38 | umar | prise |
| 71 | koenig | mathrev |
Report 3
| report_no | author_id |
| 4216 | 53 |
| 4216 | 44 |
| 4216 | 71 |
| 5789 | 26 |
| 5789 | 38 |
| 5789 | 71 |
(图4 3NF表)
定义:一张表满足第三范式(3NF)当且仅当其每个非平凡函数依赖X –> A,其中X和A可为简单或复合属性,必须满足以下两个条件之一。1. X为超键 或 2. A为某候选键的成员。若A为某候选键的成员,则A被称为主属性。注:平凡函数依赖的形式为YZ –> Z。
在上述例子中通过把report1映射为report11和report12,消除了传递依赖report_no –> dept_no –> dept_name, dept_addr,我们得到了如图4所示的第三范式表及函数依赖:
report11: repot_no –> editor, dept_no
report12: dept_no –> dept_name, dept_addr
report2: author_id –> author_name, author_addr
report3: report_no, author_id为候选键(无函数依赖)
Boyce-Codd范式(BCNF)
第三范式消除了大部分的异常,也是商业数据库设计中达到的最普遍的标准。剩下的异常情况可通过Boyce-Codd范式(BCNF)或更高级别范式来消除。BCNF范式可看作加强的第三范式。
定义:一张表R满足Boyce-Codd范式(BCNF),若其每一条非平凡函数依赖X –> A中X为超键。
BCNF范式是比第三范式更高级别的范式因为其去除了第三范式中的第二种条件(允许函数依赖右侧为主属性),即表的每一条函数依赖的左侧必须为超键。每一张满足BCNF范式的表同时满足第三范式、第二范式和第一范式。
以下的例子展示了一张满足第三范式但不满足BCNF范式的表。这样的表和那些仅满足较低范式的表一样存在删除异常。
断言1:一个小组里的每一名员工只由一位领导来管理。一个小组可能有多位领导。
emp_name, team_name –> leader_name
断言2:每一位领导只会参与一个组的管理。
leader_name –> team_name
| emp_name | team_name | leader_name |
| Sutton | Hawks | Wei |
| Sutton | Condors | Bachmann |
| Niven | Hawks | Wei |
| Niven | Eagles | Makowski |
| Wilson | Eagles | DeSmith |
(图5 team表)
team表满足第三范式,具有复合候选键emp_name, team_name
team表有如下删除异常:若Sutton离开了Condors组,Bachmann为Condors组的领导这一信息将丢失。
消除这一删除异常最简单的方法是根据两条断言创建两张表,通过两张表中冗余的信息来消除删除异常。这一分解是无损的并保持了所有原先的函数依赖,但这降低了更新性能,并需要更多存储空间。为了避免删除异常,这样做是值得的。
注:无损分解是指把一张表分解为两张小表后,通过对两张小表进行natural join得到的表与原始表相同,不会产生任何多余行。

数据库范式化示例
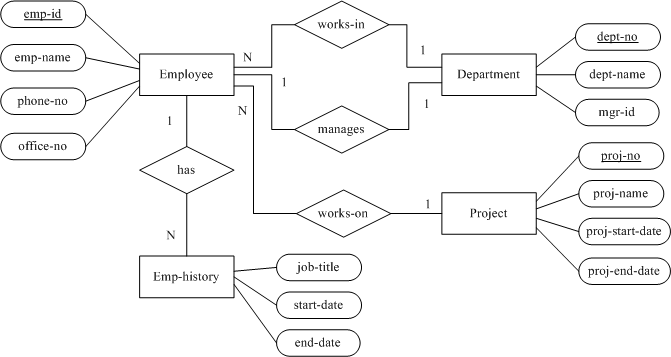
该案例基于图6中的ER模型和以下相关函数依赖。一般而言,函数依赖可通过分析ER图及业务经验推得。
- emp_id, start_date –> job_title, end_date
- emp_id –> emp_name, phone_no, office_no, proj_no, proj_name, dept_no
- phone_no –> office_no
- proj_no –> proj_name, proj_start_date, proj_end_date
- dept_no –> dept_name, mgr_id
- mgr_id –> dept_no
我们的目标是设计至少能达到第三范式(3NF)的关系数据库表结构,并尽可能减少表的数量。
如果将函数依赖1至6放入一张表,并设置复合主键:emp_id, start_date,那么我们违反了第三范式,因为函数依赖2至6的等式左侧不是超键。因此,我们需要把函数依赖1从其余的函数依赖中分离出来。如果将函数依赖2至6进行合并,我们将得到很多传递依赖。故函数依赖2、3、4、5必须分到不同的表中。我们再来考虑函数依赖5和6是否能在不违反第三范式的前提下进行合并。因为mgr_id和dept_no是相互依赖的,这两个属性在表中都是超键,所以可以合并。
通过合理的映射函数依赖1至6,我们能得到如下表:
emp_hist: emp_id, start_date –> job_title, end_date
employee: emp_id –> emp_name, phone_no, proj_no, dept_no
phone: phone_no –> office_no
project: proj_no –> proj_name, proj_start_date, proj_end_date
department: dept_no –> dept_name, mgr_id
mgr_id –> dept_no
这一解决方案涵盖了所有函数依赖。满足第三范式和BCNF范式,同时该方案创建了最少数量的表。
范式化从ER图得到的候选表
在数据库生命周期中,对表的范式化是通过分析表的函数依赖完成的。这些函数依赖包括:从需求分析中得到的函数依赖;从ER图中得到的函数依赖;从直觉中得到的函数依赖。
主函数依赖代表了实体键之间的依赖。次函数依赖代表实体内数据元素间的依赖。一般来说,主函数依赖可从ER图中得到,次函数依赖可从需求分析中得到。表1展示了每种基本ER构件所能得到的主函数依赖。
| 关系的度(Degree) | 关系的连通数(Connectivity) | 主函数依赖 |
| 二元或二元回归 | “一对一” “一对多” “多对多” | 2个:键(“一”侧) –> 键(“一”侧) 1个:键(“多”侧) –> 键(“一”侧) 无(由两侧键组成的组合键) |
| 三元 | “一对一对一” “一对一对多” “一对多对多” “多对多对多” | 3个:键(“一”),键(“一”) –> 键(“一”) 2个:键(“一”),键(“多”) –> 键(“一”) 1个:键(“多”),键(“多”) –> 键(“一”) 无(有三侧键组成的组合键) |
| 泛化 | 无 | 无 |
每个候选表一般会有多个主函数依赖和次函数依赖,这决定了当前表的范式化程度。对每个表采用各种技术使其达到需求规格中要求的范式化程度,在范式化过程中要保证数据完整性,即范式化后得到的表应包含原先候选表的所有函数依赖。精心设计的概念数据模型通常能得到基本已范式化的表,后期的范式化处理不会很困难,所以概念数据建模非常重要。

主要内容回顾
1. 不良的表结构设计将导致表数据的更新异常(update anomaly)、插入异常(insert anomaly)、删除异常(delete anomaly)
2. 范式化通过消除冗余数据,来解决数据库存在的一致性、完整性和可维护性等方面的问题。
3. 在实际数据库设计中,范式化的目标一般是达到第三范式或BCNF范式。
4. 精心设计的概念数据模型(ER模型)能帮助我们得到范式化的表。
数据库范式化参考资料
1. Database Normalization(http://en.wikipedia.org/wiki/Database_normalization)
2. 3 Normal Forms Database Tutorial(http://www.phlonx.com/resources/nf3/)